| Research Abstracts Home | CSAIL Digital Archive | Research Activities | CSAIL Home |
![]()
|
Research
Abstracts - 2007
|
|
Management of Personal Information ScrapsMichael Bernstein, Max Van Kleek, MC Schraefel & David R. KargerIntroductionInformation workers today have an enormous assortment of tools and techniques - both digital and physical - to help them organize, record, and retrieve their data. In the digital realm, simple file and folder hierarchies are now accompanied by organizational strategies such as tagging, full-text keyword search, and time-based approaches. Interestingly, ethnographic research (e.g., [3]) has consistently found one kind of data to resist organization. It exhibits itself as small files strewn on the computer desktop, as Post-Its? littering the workplace, and as emails sent to oneself to ensure that a particular blog quote is retrievable later. We keep this information on loose paper in our pockets, save it inside other documents, and archive it with our email. This information is the subject of our research. We introduce a line of Personal Information Management (PIM) research toward the design of a new tool for managing personal information scraps. We define information scraps as short, self-contained notes intended for their author?s use. Information scraps typically span a few words to a few partial sentences in length, containing only enough clues to evoke the complete thought in the author?s mind. They serve a variety of purposes, including functioning as reminders, memory aids, or holding places for incomplete thoughts. Despite their widespread use, personal information scraps are not well handled by conventional tools and thus a variety of ad-hoc keeping strategies have arisen to control them. The typical information scrap requires more effort to file correctly than the user is willing to concede to the endeavor; as a result, a lightweight, catch-all backup strategy is used to ensure that the note is archived, indexed, and/or classified. While there are a number of tools dedicated to scrap management in the digital world, from Sticky Notes to Backpack, it is not clear that an optimal approach for scrap support has been developed. Our research therefore steps back to fundamentally examine information scraps: what they are, what kind of user information they encapsulate, how they are used now, and how they might be used if we were less constrained by current application/data paradigms. We take as a fundamental assumption that information scraps are not user filing failures, but instead are failures of the interface to support the characteristics and needs of a specific class of data. Solving the information scrap problem will help knowledge workers manage the variegated and often fragmented information they deal with in their everyday work. Ethnography: Uncovering Current PracticeWe are engaging several different methodologies to uncover the ways by which people currently handle their information scraps. We begin with a preliminary diary study, and are now proceeding to uncover more data via survey resesarch and experience sampling. To examine the implications of a Quicksilver-like command interface to scrap entry, and to learn more about the nature of information scraps, we ran an informal weeklong "Fake Computer" diary study wherein the researchers recorded into a text file any interactions they would have had, should a system as we described above actually be available. We were interested in considering: what kind of data gets recorded in this file? What kind of contextual information would be recorded if we assumed that it might be reusable or useful later on? What kind of syntax was invented to enter, retrieve, and manipulate this data? A sample of entries from our text files is displayed in Table 1. We discovered a variety of recording styles: for instance, Researcher 2 and Researcher 3 assiduously annotated context data, while Researchers 1 and 4 recorded only the data itself. Consistent with Blandford et al. [1], notes often included deliberate ambiguities such as ?do ____ stuff? or a ?remind me? note without any mention of when the reminder should actually occur. Commands like ?open cal? were also used. Structure ranged from very orderly notes to almost unparseable text. Verbosity also varied between clearly explicated sentences and very condensed text, even within the same log. Reflecting on the process of recording these notes generated additional insights. For example, one researcher was later unable to decipher his notes? original meanings ? clearly, facilitating this kind of message unpacking will play an important role in our future work. The logs tended to evolve shorthand for meaningful tokens (e.g., ?Tim Berners-Lee? became ?timbl?). Also, some notes were continually updated: one of the researchers would even return later to flesh out hastily-written notes. Contextual data was also written as interpreted rather than as it occurred, so that the hallway outside a colleague?s office become simply "(colleague)?s office". Strikingly, we found that much of the information in these logs might not have otherwise been recorded on a computer.
For our upcoming survey, we will be investigating a variety of currently-existing practices for information scrap capture and organization. We are currently in the process of collecting responses to answer the following questions:
We will augment this information with an experience sampling study to gain access to actual information scraps as they are created. The experience sampling method [2] involves interrupting participants at unannounced points during the day to ask them to share their most recent information scrap. This will allow us access to answer another set of questions:
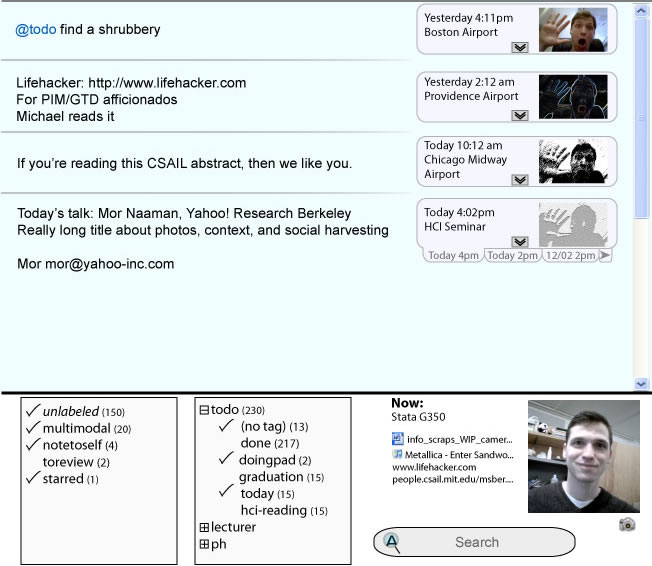
Technology SolutionsWe are currently in the process of designing and building research systems to address the information scrap problem. These systems must lower the cost of input while simultaneously supporting usable retrieval mechanisms. The jourKnow system (Figure 1) is our current information scrap solution. It focuses on lightweight input -- we have learned that making input as lightweight as possible is critical to the adoption of any such system. Instead, we do as much work as possible for the user. Our first method is automatic context capture: users often do not want to be bothered to record contextual information surrounding the scrap creation, even when it may be useful for later refinding activity. To this end, we are recording a myriad of contextual activities as the user interacts with his or her computer: location, web sites and documents accessed, files modified, music playing, and even a photo. Our second method is application integration, whereby users may use the jourKnow as lightweight input to their existing application suite, including calendar, email, web browser, and address book. A user may enter freeform information about an appointment for later that day and upon his or her approval synchronize this information with the structured information held by the calendar program. Later changes to the calendar program will cause the original note to be annotated with the revision. We believe that loosening this requirement for highly structured data entry will help users overcome current programs' inability to record half-formed ideas.
ConclusionInformation scraps ? small pieces of user-generated data which fit poorly within existing filing paradigms ? represent a significant percentage of our information workspace, yet to date HCI research has found no satisfactory solution for them. Scraps run counter to many of the assumptions of our current filing paradigms: for example, assumptions that all data must be given an unambiguous filing location and name immediately upon creation. (Compare performing Save As? on an internet download to slapping a hastily scribbled Post-It? on the wall.) If research can design support for this ad-hoc data wherein users can quickly save an information scrap and easily find it later, we will have more fully enabled a wide variety of information work, including note taking, memory aids, document editing and to-dos.
References:[1] Blandford, A.E. and Green, T.R.G. Group and Individual Time Management Tools: What You Get is Not What You Need. In Personal and Ubiquitous Computing 5:4, pp. 213-230, 2001. [2] Csikszentmihalyi, M. and Larsen, R.E. Validity and Reliability of the Experience-Sampling Method. J. Nerv. Ment. Dis. 175:9, pp.526-536, 1987. [3] Hayes, G., Pierce, J.S. and Abowd, G.D. Practices for capturing short important thoughts. Ext. Abstracts CHI 2003, ACM Press, pp. 904-905, 2003. |
|||||||||||||
|