| Research Abstracts Home | CSAIL Digital Archive | Research Activities | CSAIL Home |
![]()
|
Research
Abstracts - 2007
|
|
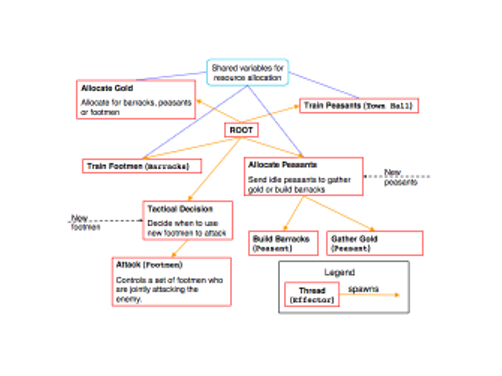
Learning Action HierarchiesBhaskara Marthi, Leslie Pack Kaelbling & Tomas Lozano-PerezAbstractWe are working on the problem of learning the structure of action hierarchies from observed optimal behavior on a sequential decision problem, such that the action hierarchy can then be used to learn faster on future instances of the problem. MotivationReinforcement learning (RL) is the problem of learning, by doing actions and receiving rewards, how to act optimally in some environment. Often, having learnt a good policy for some environment, humans are able to learn much more quickly in related environments. For example, consider the following two environments, which are examples of real-time strategy video games. Although the rules, types of units, and goals of the two games might not be exactly the same, a human who had experience playing the first one would probably quickly achieve some degree of competence on the second.
We would like to have RL algorithms that can transfer information in this manner. To do this requires deciding first what exactly is being transferred. Since the two problems are not identical, it doesn't make sense to transfer the entire decision policy in all its detail. Instead, one might want to transfer an action hierarchy that breaks the overall problem into tasks and subtasks. A hierarchy for a simple example strategy game is shown below. There are several existing hierarchical reinforcement learning algorithms that can make use of such a hierarchy to learn faster. Thus the problem we consider is: given a set of observed executions of a near-optimal policy for an environment, come up with a good action hierarchy. Objective functionWe have formalized our problem as an optimization of a certain objective function. This objective function has two pieces. First, we would like it to be the case that the hierarchy does not overconstrain the possible policies, thus ruling out all the good ones. So we have a term, called the hierarchy loss, that measures how much reward is lost by using the hierarchically optimal policy instead of the optimal one. Second, we would like to be able to learn quickly using the hierarchy. So we have a term, called the hierarchy complexity, that measures the expected number of samples needed to learn a hierarchically optimal policy from experience in future environments. Both these terms are hard to compute exactly, so we use surrogate quantities. For the hierarchy loss, we use the assumption that the observed execution trajectories are near-optimal, and therefore try to find a hierarchy that can 'explain' them well. This task can be formalized and solved efficiently as an extension of parsing in stochastic context-free grammars. For the hierarchy complexity, we take the view that hierarchies are useful because they shorten the reward horizon and because they allow subtasks to be treated somewhat independently. In each case, we have developed a way to estimate the resulting gains in sample complexity. We also want to make sure that the hierarchy is not overly specific to the particular task for which it was learnt. We do this by allowing the system designer to provide a hierarchy language that constrains the kinds of hierarchies that may be considered. For example, we may forbid the hierarchy from referring to specific locations on the map of the first problem. Search problemOptimizing the objective function over the space of allowed hierarchies is likely to be intractable, and so we resort to local search. The search will proceed in a top-down fashion, beginning with a trivial hierarchy with a single task, and splitting tasks into subtasks when necessary. The observed trajectories can be used to guide this process. For example, if there is a particular feature that, on many trajectories, begins by being false, and subsequently becomes true, we may hypothesize that this feature corresponds to a task of achievement, and consider adding this task to the hierarchy. Another approach is to look for long stretches of trajectories where only a restricted set of actions is used. ProgressWe have implemented an initial version of the objective function. On a simulated navigation problem, it correctly distinguishes the hierarchy that seems sensible. We are currently working on scaling to larger problems, which will require more attention to the heuristics used during search. Funding sourcesThis material is based upon work supported by the Defense Advanced Research Projects Agency (DARPA). Any opinions, findings, and conclusions or recommendations expressed in this material are those of the authors and do not necessarily reflect the views of DARPA. |
|||
|