| Research Abstracts Home | CSAIL Digital Archive | Research Activities | CSAIL Home |
![]()
|
Research
Abstracts - 2007
|
|
Discourse and Dialog in the START Question Answering SystemBoris Katz & Sue FelshinThe ProblemQuestion answering systems based on human language enable expressive and concise communication: the user can pose natural questions and receive natural and relevant responses. However, language can be ambiguous and vague. We should not force the user to adapt to the computer and formulate precise and unambiguous queries. Instead, the computer should adapt itself to ambiguity and missing data as a human does: by engaging in conversation, by inferring information missing from the question, by clarifying answers and by giving intelligent related answers when the exact answer is not available (“near-miss” answers [2]). The START system (see [1] and related abstracts in this collection) provides users with convenient access to information through its ability to retain conversational state, recognize ellipsis, give appropriate near-miss answers, and report intelligently on ambiguity and failure to find information. MotivationConversational and interactive abilities allow START to make assumptions about information missing from the question or query the user about it, choose amongst multiple answers to questions, and provide intelligent explanations and near-miss answers. These conversational capabilities allow the user to interact with the system with convenient, natural brevity. ApproachSTART operates by parsing user questions into structural representations, matching these representations against its knowledge base, and retrieving information in order to return high-precision answers to questions. START's use of linguistic processing gives it several opportunites to incorporate discourse and dialog techniques to improve its operation:
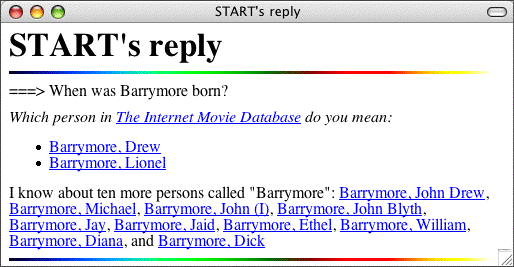
Ellipsis and AnaphoraUsing the structural representation of the preceding question, START identifies what material in the preceding question should be replaced by the new, elliptical question phrase and chooses among multiple potential antecedents by examining their lexical features to find the closest semantic match. The second example below contains examples of anaphor resolution as well. ⇒ What Asian country has the eighth largest population? Selecting Among Multiple ResultsThe more understanding a system has of the structure and intent of the question, the better it is able to select among multiple results. Because START performs a linguistic analysis of questions, it can distinguish types of ambiguity and multiplicity; it can distinguish whether multiple replies are different answers to the same interpretation of the question, or answers to different interpretations of the question. For example, when word(s) in the question can match more than one entity in a class of object, START may choose to respond about all entities or to query the user for clarification. Some entities are marked as important (this is either manually assigned or heuristically calculated) and are preferred over others in the same class. Thus START presents the information which is most likely wanted, yet remains fully informative.
Near Misses, Partial Answers, and Recognizable FailuresFor structured and semi-structured databases indexed by START [3] (see related abstract in this collection), START can be confident that if no answer is found in the source, it is because the source does not contain the answer. START uses knowledge of real-world properties of entities in order to provide near-miss and partial answers. This requires ontological knowledge of how properties and entities relate within and across types of properties and entities, and therefore can only be implemented in the general case by building a complete ontology. In practice, however, the bulk of actual user questions address a relatively small number of types and properties, so that a small amount of ontology building can improve a comparatively large proportion of questions.
Future WorkEllipsis: One area of research is distinguishing when elliptical material should be considered an addition to previous material vs. a replacement: Given "What is the largest country in Europe?", does a followup of "In NATO?" mean "What is the largest country in Europe in NATO?" (France) or "What is the largest country in NATO?" (Canada)? Selecting among multiple results: Our importance labels are sometimes derived manually, but we have also experimented with deriving them automatically. For example, a limited source can be used to derive importance labels for a broader source. The principal difficulty in acquiring importance labels in this way is determining equivalence between elements in two sets which may look different and be the same, as "Bill Clinton" vs. "William Jefferson Clinton", or look the same and be different, as the many "John Smith"s. Our research is ongoing in this area. Near misses, partial answers, and recognizable failures: Success in this area relies largely on ontology building, which is an ongoing effort. Research SupportThis work is supported in part by the Disruptive Technology Office as part of the AQUAINT Phase 3 research program. References:[1] Boris Katz. Annotating the World Wide Web Using Natural Language. In Proceedings of the 5th RIAO Conference on Computer Assisted Information Searching on the Internet (RIAO '97), Montreal, Canada, 1997. [2] Boris Katz and Sue Felshin. Discourse and Dialog in the START Question Answering System. In Proceedings of the 5th SIGdial Workshop on Discourse and Dialogue (SIGdial '04), Demos during the Workshop, Cambridge, Massachusetts, 2004. [3] Boris Katz, Sue Felshin, Deniz Yuret, Ali Ibrahim, Jimmy Lin, Gregory Marton, Alton Jerome McFarland, and Baris Temelkuran. Omnibase: Uniform Access to Heterogeneous Data for Question Answering. In Proc. of the 7th Int. Workshop on Applications of Natural Language to Information Systems (NLDB '02), Stockholm, Sweden, June 2002. |
|||||
|