| Research Abstracts Home | CSAIL Digital Archive | Research Activities | CSAIL Home |
![]()
|
Research
Abstracts - 2007
|
|
From Sentence Processing to Multimedia Information AccessBoris KatzThe ProblemIt is clear that a robust full-text natural language understanding system cannot realistically be expected any time soon. Numerous problems such as intersentential reference and paraphrasing, summarization, common sense implication, and many more, will take a long time to solve to everybody's satisfaction. At the same time, however, it turns out that given a sophisticated grammar, a large lexicon enhanced by advances in Lexical Semantics, and an inference engine, it is possible to build a natural language system with satisfactory sentence-level performance. We have developed natural language annotation technology which lets us bridge the gap between our ability to analyze natural language sentences and our appetite for processing huge amounts of natural language text and multimedia. Using this technology, one can immediately access text, images, sound, video, Web pages, and more, without relying on the as-yet-unreached goal of full-text language understanding. ApproachOur work builds on the START natural language system [1] [2], which has been used by researchers at MIT and other universities and research laboratories for constructing and querying knowledge bases using English. The START system analyzes English text and produces a knowledge base which incorporates, in the form of nested ternary expressions, the information found in the text. One can think of the resulting entry in the knowledge base as a "digested summary" of the syntactic structure of an English sentence. (Other information contained within the sentence is stored as ancillary information and is used only secondarily in indexing and retrieving, providing efficiency without information loss.) A user can retrieve the information stored in the knowledge base by querying it in English. The system will then produce an English response. A representation mimicking the hierarchical organization of natural language syntax has one undesirable consequence: sentences differing in their surface syntax but close in meaning are not considered similar by the system. START solves the problem by deploying structural transformation rules (in forward and backward modes) which make explicit the relationship between alternate realizations of the arguments of verbs [5] and other structures.
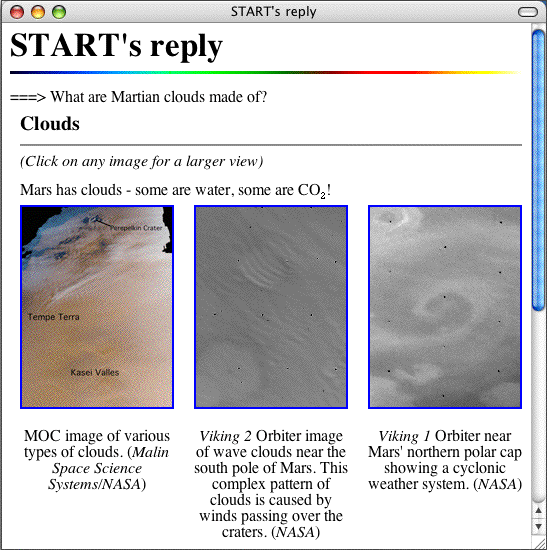
The START system bridges the gap between current sentence-level text analysis capabilities and the full complexity of unrestricted natural language by employing natural language annotations [3]. Annotations are computer-analyzable collections of natural language sentences and phrases that describe the contents of various information segments. START analyzes these annotations in the same fashion as any other sentences, but in addition to creating the required representational structures, the system also produces special pointers from these representational structures to the information segments summarized by the annotations. For example, the HTML fragment about clouds on Mars in Figure 1 may be annotated with the following English sentences and phrases:
START parses these annotations and stores the parsed structures (nested ternary expressions) with pointers back to the original information segment. To answer a question, the user query is compared against the annotations stored in the knowledge base. Because this match occurs at the level of syntactic structures, linguistically sophisticated machinery such as synonymy/hyponymy, ontologies, and structural transformation rules are all brought to bear on the matching process. Linguistic techniques allow the system to achieve capabilities beyond simple keyword matching, for example, handling complex syntactic alternations such as those involving verb arguments. If a match is found between ternary expressions derived from annotations and those derived from the query, the segment corresponding to the annotations is returned to the user as the answer. For example, the annotations above allow START to answer the following questions (see Figure 1 for an example):
With large resources, of course, it is impractical to annotate all of the content. However, resources of all types—structured, semi-structured and unstructured—can contain significant amounts of parallel material. Parameterized annotations address this situation by combining fixed language elements with “parameters” that specify variable portions of the annotation. As such, they can be used to describe whole classes of content while preserving the indexing power of non-parameterized annotations. As an example, the parameterized annotation (with parameters in italics)
can describe, on the data side, a large table of population figures for various cities. On the question side, this annotation can support questions submitted in many forms:
In combination with other parameterized annotations that describe the population figures in other ways (for example, using the terms “population” or “populous”, or referring to people “being in” the city, or the city being “large” or “small”), a significant range of questions can be processed from the given data as a result of matches to parameterized annotations. The annotation technology has been used to create START knowledge bases in a number of topic areas, including cities, countries, weather reports, U.S. colleges and universities, U.S. presidents, movies, and more. Our Omnibase [4] system allows us to access heterogeneous structured and semi-structured databases on the Web and elsewhere. FutureThe sheer amount of information available in the world today places a practical limit on the amount of knowledge that can be incorporated into a system by a single research group. Although natural language annotations are easy and intuitive, there is simply too much content. Parameterized annotations make it worthwhile to provide natural language access to a limited number of structured and semi-structured data sources, but are not readily applicable to unlimited quantities of unrestricted material such as the complete World Wide Web. However, we are working on other techniques (see related abstracts) to automatically extract annotations from unrestricted text. Research SupportThis work is supported in part by the Disruptive Technology Office as part of the AQUAINT Phase 3 research program. References:[1] Boris Katz. A Three-step Procedure for Language Generation. Technical Report 599, 1980. [2] Boris Katz. Using English for Indexing and Retrieving. In Artificial Intelligence at MIT: Expanding Frontiers, v. 1; Cambridge, MA, 1990. [3] Boris Katz. Annotating the World Wide Web Using Natural Language. In Proceedings of the 5th RIAO Conference on Computer Assisted Information Searching on the Internet (RIAO '97), Montreal, Canada, 1997. [4] Boris Katz, Sue Felshin, Deniz Yuret, Ali Ibrahim, Jimmy Lin, Gregory Marton, Alton Jerome McFarland, and Baris Temelkuran. Omnibase: Uniform Access to Heterogeneous Data for Question Answering. In Proc. of the 7th Int. Workshop on Applications of Natural Language to Information Systems (NLDB '02), Stockholm, Sweden, June 2002. [5] Boris Katz and Beth Levin. Exploiting Lexical Regularities in Designing Natural Language Systems. In Proceedings of the 12th International Conference on Computational Linguistics (COLING '88), 1988. |
|||||
|