
| Research Abstracts Home | CSAIL Digital Archive | Research Activities | CSAIL Home |
![]()
|
Research
Abstracts - 2007
|
|
LabelMe: A Database and Web-based Tool for Image AnnotationBryan C. Russell, Antonio Torralba, Samuel Davies, Kevin P. Murphy & William T. FreemanMotivation:Research in object detection and recognition in cluttered scenes requires large image and video collections with ground truth labels. The labels should provide information about the object classes present in each image, as well as their shape and locations, and possibly other attributes such as pose. Such data is useful for testing, as well as for supervised learning. Even algorithms that require little supervision need large databases with ground truth to validate the results. New algorithms that exploit context for object recognition [1] require databases with many labeled object classes embedded in complex scenes. Such databases should contain a wide variety of environments with annotated objects that co-occur in the same images. Building a large database of annotated images with many objects is a costly and lengthy enterprise. Traditionally, databases are built by a single research group and are tailored to solve a specific problem (e.g, face detection). Many databases currently available only contain a small number of classes, such as faces, pedestrians, and cars. A notable exception is the Caltech 101 database [2], with 101 object classes. Unfortunately, the objects in this set are generally of uniform size and orientation within an object class, and lack rich backgrounds. Approach:Web-based annotation tools provide a new way of building large annotated databases by relying on the collaborative effort of a large population of users [3,4,5,6]. LabelMe is an online annotation tool that allows the sharing of images and annotations. The tool provides many functionalities such as drawing polygons, querying images, and browsing the database. Both the image database and all of the annotations are freely available. The tool runs on almost any web browser, and uses a standard Javascript drawing tool that is easy to use (see Figure 1 for a screenshot). The resulting labels are stored in the XML file format, which makes the annotations portable and easy to extend. A Matlab toolbox is available that provides functionalities for manipulating the database (database queries, communication with the online tool, image transformations, etc.). The database is also searchable online. Results:Currently the database contains more than 139,000 objects labeled within 37,000 images covering a large range of environments and several hundred object categories (Figure 2). The images are high resolution and cover a wide field of view, providing rich contextual information. Pose information is also available for a large number of objects. Since the annotation tool has been made available online there has been a constant increase in the size of the database (see Figure 3). One important concern when data is collected using web-based tools is quality control. Currently quality control is provided by the users themselves. Polygons can be deleted and the object names can be corrected using the annotation tool online. Despite the lack of a more direct mechanism of control, the annotations are of quite good quality (see Figure 4). Another issue is the complexity of the polygons provided by the users - do users provide simple or complex polygon boundaries? Figure 5 illustrates the average number of points used to define each polygon for several object classes that were introduced using the web annotation tool. These polygons provide a good idea of the outline of the object, which is sufficient for most object detection and segmentation algorithms. Another issue is what to label. For example, should you label a whole pedestrian, just the head, or just the face? What if it is a crowd of people - should you label all of them? Currently we leave these decisions up to each user. In this way, we hope the annotations will reflect what various people think are ``natural'' ways to segment an image. A third issue is the label itself. For example, should you call this object a ``person'', ``pedestrian'', or ``man/woman''? An obvious solution is to provide a drop-down menu of standard object category names. However, we currently prefer to let people use their own descriptions, since these may capture some nuances that will be useful in the future. We have incorporated WordNet [7], an electronic dictionary, to extend the LabelMe descriptions. We can now query for objects at various levels of the WordNet tree. Figure 6 shows examples of queries for superordinate objects. Very few of these examples were labeled with the superordinate label, but nonetheless we can find them. For more details, please refer to [5] or visit the project page: http://labelme.csail.mit.edu. 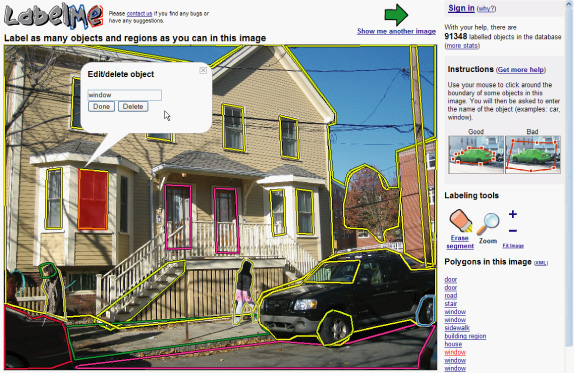
Figure 1: A screenshot of the labeling tool in use. The user is shown an image along with possibly one or more existing annotations, which are drawn on the image. The user has the option of annotating a new object by clicking along the boundary of the desired object and indicating its identity, or editing an existing annotation. The user may annotate as many objects in the image as they wish. 
Figure 2: Examples of annotated scenes. These images have more than 80% of their pixels labeled and span multiple scene categories. Notice that many different object classes are labeled per image. 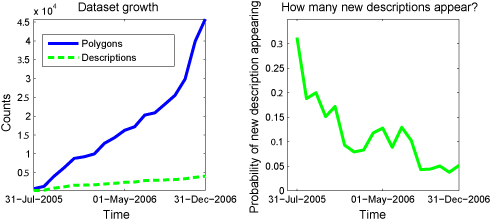
Figure 3: Evolution of the online annotation collection over time. Left: total number of polygons (blue) and descriptions (green) in the LabelMe dataset as a function of time. Right: the number of new descriptions entered into the dataset as a function of time. Notice that the dataset has steadily increased while the rate of new descriptions entered has decreased. 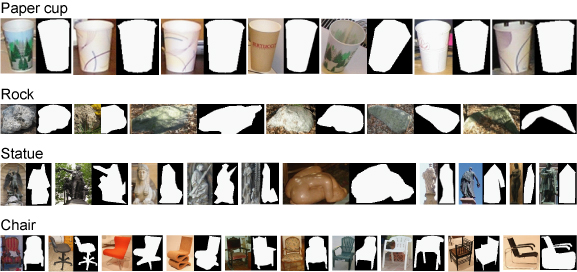
Figure 4: Image crops of labeled objects and their corresponding silhouette, as given by the recorded polygonal annotation. Notice that, in many cases, the polygons closely follow the object boundary. Also, many diverse object categories are contained in the dataset. 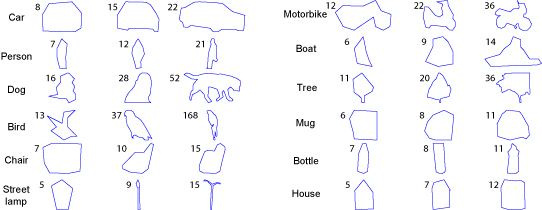
Figure 5: Illustration of the quality of the annotations in the dataset. Foreach object we show three polygons depicting annotations corresponding to the 25th, 50th, and 75th percentile of the number of control points recorded for the object category. Therefore, the middle polygon corresponds to the average complexity of a segmented object class. The number of points recorded for a particular polygon appears near the top-left corner of each polygon. Notice that, in many cases, the object's identity can be deduced from its silhouette, often using a small number of control points. 
Figure 6: Superordinate object label queries after incorporating WordNet. Very few of these examples were labeled with the superordinate label (the original LabelMe descriptions are shown below each image). Nonetheless, we are able to retrieve these examples. Research Support:Financial support was provided by the National Geospatial-Intelligence Agency, NEGI-1582-04-0004, and a grant from BAE Systems. Kevin Murphy was supported in part by a Canadian NSERC Discovery Grant. References:[1] A. Torralba. Contextual priming for object detection. International Journal of Computer Vision, 53(2):153-167, 2003. [2] L. Fei-Fei, R. Fergus, and P. Perona. A Bayesian approach to unsupervised one-shot learning of object categories. In Proc. ICCV, 2003. [3] Luis von Ahn and Laura Dabbish. Labeling images with a computer game. In Proc. SIGCHI conference on Human factors in computing systems, 2004. [4] Flikr. http://www.fickr.com. [5] B. C. Russell, A. Torralba, K. P. Murphy, and W. T. Freeman. LabelMe: a database and web-based tool for image annotation. Technical report, MIT AI Lab Memo AIM-2005-025, 2005. [6] D.G. Stork. The Open Mind Initiative. IEEE Intelligent Systems and Their Applications, 14-3, 1999, pages 19-20. [7] C. Fellbaum. Wordnet: An Electronic Lexical Database. Bradford Books, 1998. |
|||
|