
| Research Abstracts Home | CSAIL Digital Archive | Research Activities | CSAIL Home |
![]()
|
Research
Abstracts - 2007
|
|
Virtual Training for Multi-View Object Class RecognitionHan-Pang Chiu, Tomas Lozano-Perez & Leslie Pack KaelblingWhat:Our goal is to circumvent one of the roadblocks to using existing approaches for single-view recognition for achieving multi-view recognition, namely, the need for sufficient training data for many viewpoints. We construct virtual training examples for multi-view recognition using a simple model of objects (nearly planar facades centered at arbitrary 3D positions). The models can be learned from a few labeled images for each object class. Why:In most current approaches to object class recognition [1][2][3][4][5], the problem of recognizing multiple views of the same object class is treated as recognizing multiple independent object classes, with a separate model learned for each. This independent-view approach can be made to work well when there are lots of instances at different views available for training, but can typically only handle new viewpoints that are a small distance from some view on which it has been trained. An alternative strategy is to use multiple views of multiple instances to construct a model of the distribution of 3-dimensional shapes of the object class. Such a model would allow recognition of many entirely novel views. This is a very difficult problem, which is as yet unsolved. How:In this work, we take an intermediate approach. We define the facade model of 3-dimensional objects as a collection of parts. The model allows the parts to have an arbitrary arrangement in 3D, but assumes that, from any viewpoint, the parts themselves can be treated as being nearly planar. We will refer to the arrangement of the part centroids in 3D as the skeleton of the object. As one moves the viewpoint around the object, the part centroids move as dictated by the 3D skeleton; but rather than having the detailed 3D model that would be necessary for predicting the transformation of each part shape from one view to another, we model the change in views of each shape as a 2D perspective transformation. The facade model is trained and used in two phases. In the first phase, multiple views of some simple object instances, such as boxes, are used to learn fundamental transforms from view to view. The necessary data can be relatively simply acquired from real or synthetic image sequences of a few objects rotating through the desired space of views. In the second phase, a collection of views of different object instances of the target class, from arbitrary views, is used to estimate the 3D skeleton of the object class and tune the view transforms for each of the parts. Given a new view of interest, the skeleton can easily be projected into that view, specifying the 2D centroids of the parts. Then, the 2D part images of the training examples in other views can be transformed into this view using the transforms learned in the initial phase. This gives us a method for generating ``virtual training examples'' of what it would be like to see this object from a novel view. These virtual training examples, along with any real training examples that are available, can then be fed into a relatively traditional view-dependent 2D part-based recognition model, which can be used to look for instances of the object class in the novel viewpoint. 
Progress:We used two different object classes for our experiments: four-legged chairs and bicycles [6]. There are 10 real training examples in each of the view bins (6 views for chairs and 4 views for bicycles). Any real training example in one view can be used to generate one virtual training example in each of the other views. Then we trained object detectors from the combination of actual and virtual examples. We tested the trained detectors on the problem of localization of objects within images, and found that it enabled the recognition system to perform well with significantly less real training data than would have been required by independent models. In addition, it was able to do a reasonable job of recognizing objects at views significantly different from those seen in the training images. 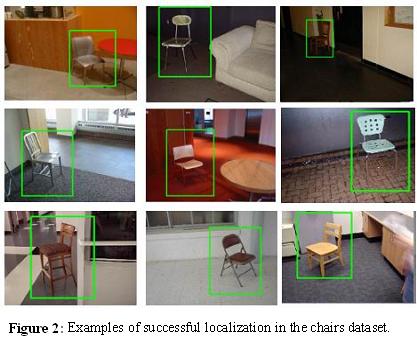
Acknowledgements:We thank Meg Aycinena, Sam Davies, Sarah Finney, and Kaijen Hsiao for all their helps on this project. Research Support:This research was supported in part by DARPA IPTO Contract FA8750-05-2-0249, Effective Bayesian Transfer Learning. References:[1] R. Fergus, P. Perona, and A. Zisserman, Object class recognition by unsupervised scale-invariant learning, In CVPR, pp. 264-271, 2003. [2] M. P. Kumar, P. H. S. Torr, A. Zisserman, Extending pictorial structures for object recognition, In BMVC, 2004. [3] D. Crandall, P. F. Felzenszwalb, D. P. Huttenlocher, Spatial priors for part-based recognition using statistical models, In CVPR, 2005. [4] S. Agarwal and D. Roth, Learning a sparse representation for object detection, In ECCV, 2002. [5] R. Fergus, P. Perona, and A. Zisserman, A sparse object category model for efficient learning and exhaustive recognition, In CVPR, 2005. [6] M. Everingham, A. Zisserman, C. Williams, and L. V. Gool, The pascal visual object classes challenge 2006 (voc2006) results, In 1st PASCAL Challenge Workshop, to appear. |
|||
|