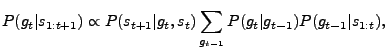| Research Abstracts Home | CSAIL Digital Archive | Research Activities | CSAIL Home |
![]()
|
Research
Abstracts - 2007
|
|
Goal Inference as Inverse PlanningChris L. Baker, Rebecca R. Saxe & Joshua B. TenenbaumIntroductionInfants and adults are adept at inferring agents' goals from observations of behavior. Often these observations are ambiguous or incomplete, yet we confidently make goal inferences from such data many times each day. The apparent ease of goal inference masks a sophisticated probabilistic induction. There are typically many goals logically consistent with an agent's actions in a particular context, and the apparent complexity of agents' actions invokes a confusing array of explanations, yet observers' inductive leaps to likely goals occur effortlessly and accurately. Unlike humans, computers have great difficulty with goal inference. By building computational models of human goal inference, we hope to close the gap between human and computer performance. Here, we propose a computational framework for goal inference in terms of inverse probabilistic planning. It is often said that "vision is inverse graphics": computational models of visual perception -- particularly in the Bayesian tradition -- often posit a causal physical process of how images are formed from scenes (i.e. "graphics"), and this process must be inverted in perceiving scene structure from images. By analogy, in inverse planning, planning is the process by which intentions cause behavior, and the observer infers an agent's intentions, given observations of an agent's behavior, by inverting a model of the agent's planning process. To evaluate specific models within our framework, we compare predictions of the models with predictions of human subjects on artificial stimuli designed to probe a broad range of goal inferences. Here, we describe the specific model that best explains people's judgments across several experiments we have conducted. We describe one of these experiments to illustrate our basic experimental methodology. Inverse planning frameworkAt its core, the inverse planning framework assumes that human observers represent other agents as rational planners solving MDPs. The causal process by which goals cause behavior is generated by probabilistic planning in MDPs with goal-dependent reward functions. Using Bayesian inference, this causal process can be integrated with prior knowledge of likely goal structures to yield a probability distribution over agents' goals given their behavior. Let Let
The value function
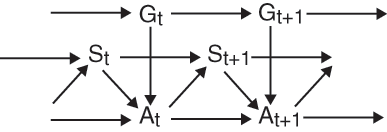
The general inverse planning framework we have described includes many specific models that differ in the complexity they assign to the beliefs and desires of agents. Fig. 1 illustrates the specific model we consider here in graphical model notation. This model assumes that agents' goals can change over time according to a Markov process. Although the graphical model representation captures the relationships between variables in the model, inverse planning is required to construct the CPTs that determine the agent's policy.
Model predictions are generated by computing the posterior probability
of goals, given observations of behavior. To compute the posterior distribution
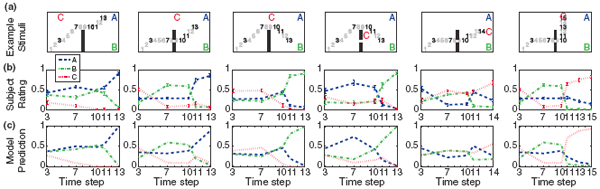
over goals at time which follows from the graphical model in Fig. 1. Experiment and resultsParticipants were 16 members of the MIT community. They were told they would watch 2D videos of intelligent aliens moving around in simple environments with visible obstacles, with goals marked by capital letters. There were 100 stimuli in total. An illustrative subset is shown in Fig. 2(a). Each stimulus contained 3 goals. There were 4 different goal configurations, and two different obstacle conditions: gap and solid, for a total of 8 different environments. There were 11 different complete paths: two paths headed toward 'A', two paths headed toward 'B', and 7 paths headed toward 'C' (to account for C's varying locations). Partial segments of these paths starting from the beginning were shown in each different environment. Because many of the paths were initially identical, and because many of the paths were not possible in certain environments (i.e. collided with walls), the total number of unique stimuli was reduced to 100. Stimuli were presented shortest lengths first in order to not bias subjects toward particular outcomes, and stimuli of the same length were shown in random order. After each stimulus presentation, subjects were asked to rate which goal they thought was most likely (or if two or more were equally likely, to pick one of the most likely). After this choice, subjects were asked to rate the likelihood of the other goals relative to the most likely goal, on a 9-point scale from "Equally likely", to "Half as likely", to "Extremely unlikely". Ratings were normalized to sum to 1 for each stimuli, then averaged across all subjects and renormalized to sum to 1. Example subject ratings are plotted with standard error bars in Fig. 2(b). Our model makes strong predictions about people's ratings in this experiment. Model predictions are computed using Eq. 2. Example model predictions are plotted in Fig. 2(c); these match subjects' ratings very closely. The correlation of the model predictions with subjects' ratings across all 100 stimuli was very high, with a correlation coefficient of r = .96.
DiscussionThis abstract is based on work from [1] and [2]. These papers describe further experiments that were conducted, and provide comparisons with several alternative models. Overall, our results provide support for the specific model described in this paper, and for the inverse planning framework more generally. Ongoing work is aimed at extending our results to more realistic and complex environments, and exploring the capacity of our framework to predict people's inferences about other mental states, such as belief. For further details on this project, see Chris Baker's research webpage. Research supportCLB was supported by a Department of Homeland Security Graduate Fellowship. Further support provided under AFOSR Contract# FA9550-05-1-0321. References[1] Chris L. Baker, Joshua B. Tenenbaum & Rebecca R. Saxe. Bayesian models of human action understanding. In Advances in Neural Information Processing Systems 18, 2006. [2] Chris L. Baker, Joshua B. Tenenbaum & Rebecca R. Saxe. Goal inference as inverse planning. In Proceedings of the Twenty-Ninth Annual Conference of the Cognitive Science Society, submitted. |
|||||||
|
![$\displaystyle V^{\pi}_{g,w}(s) =
E_{\pi}\Biggl[\sum_{t=1}^{\infty} \sum_{a_t} P_{\pi}(a_t\vert s_t,g,w) C(a_t,s_t)
\Biggl\vert\Biggr. s_1 = s \Biggr].$](img24.gif)