
| Research Abstracts Home | CSAIL Digital Archive | Research Activities | CSAIL Home |
![]()
|
Research
Abstracts - 2007
|
|
Making Reusable Structured Data on The Web CheaperDavid F. Huynh, Robert C. Miller & David R. KargerIntroductionWhen we encounter data on the Web, often it can only be read on the original pages, at the original sites, in its original forms that its original authors intended. If several people's names and addresses are coded as a list on a web page, then it is very costly, in terms of cognitive demand, efforts, and time, to visualize them all on a map—a reasonable alternative. For all practical purposes, such data is not reusable beyond copying it as unstructured (plain) text. Ironically, it might be stored in databases behind web sites where it can readily be exported in structured formats convenient for reuse, but for the purpose of presenting to humans, it has been shoehorned into HTML, stripped completely of all its structure and semantics. Reuse is desirable for several reasons. No producer of any data can anticipate all potential uses of that data in the future, have enough resources to fit the data for all those uses, and address all desires of all potential consumers of that data. Hence, it is appealing to let each individual consumer of any data to interact with that data in ways personalized to her, suiting her needs at the moment of use. Reusable data from several disparate sources can also be more easily recombined to satisfy needs that no single source addresses. The explosive growth of Web mashups is evidence that information recombination is addressing real world problems. The Semantic Web project [1] envisions a future Web wherein structured data flows smoothly, unhindered by format incompatibility. In such a medium, machines can automatically process the data unaided by human users. Data becomes cheaper, so to speak, as there is little cost for people to repurpose that data. In spite of this appealing vision of cheap reusable data, there is no commonly held opinion of how to build the Semantic Web from the existing Web, or to get the existing data on the Web into more structured forms. Paving a practical path to this future of cheap reusable data is the goal of our research. Approach & ProgressAs a communication medium, the Web has information consumers and producers (roles that can also be played simultaneously by any single individual). In order to increase the amount of cheap reusable data, we address these two groups differently: we increase consumers' awareness of and desire for cheap reusable data and we give producers incentives for publishing such data. We deploy these two strategies on the existing Web using its existing infrastructure. For consumers of information, we provide tools such as Piggy Bank [2], a web browser extension that can extract information out from Web pages using Javascript-based screen scrapers and provide sophisticated browsing and management features on the extracted data. Data can be recombined from several separate sources once it has all been converted into a common data model. The collected data can also be pooled together in communal repositories. Users of Piggy Bank will hopefully develop an appreciation as well as a demand for cheap reusable data. They will also incidentally help converting existing data in HTML into more structured formats just by using Piggy Bank. As Javascript screen scrapers are difficult to write, we experimented with automatic generation of screen scraping code that can work on many relatively consistently structured web pages. Sifter [3] is a successor of Piggy Bank that requires as few as two clicks to get the data out of a web page, which is then used to augment the web page in-place with faceted browsing functionality (see screenshot below). Unlike previous web extraction work, Sifter does not require the user to manually label any field but still brings benefits by simply leveraging the existing visual semantics on the original page. 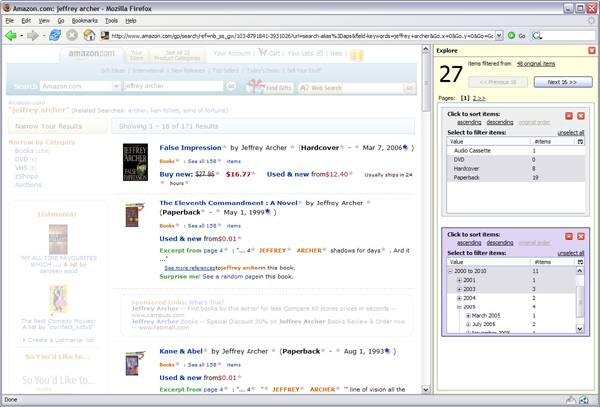
Sifter works on web pages that are consistently structured, such as those generated from databases through server-side templates. These sites belong to large institutions and companies who can afford engineering costs of three-tier web applications. While these institutions and companies are important citizens of the Web, they do not represent the whole Web, nor does their data represent all information on the Web. Outside of Sifter's aim are the web pages created by individuals and small groups who do not have enough resources to afford enterprise web solutions. These information producers must often settle for static web pages that offer few of those features users have come to expect from interacting with enterprise web sites. Moreover, being hand-coded, those static web pages are far more difficult to scrape automatically. To these information producers we propose Exhibit [4], a very lightweight structured data publishing framework that produces rich visualizations (maps, timelines, scatter plots, pivot tables, etc.) and offers sophisticated browsing features (sorting, filtering) while requiring only knowledge of HTML (see screenshot below). By baiting these information producers with rich user interfaces at very low cost, we get in return structured data published on many topics that have never appealed the large information producers. It is in the Long Tail [5] that we will find the diversity so representative of the Web, and it is in enabling and cherishing this diversity that we will make the Semantic Web the universal medium where anyone can publish structured data, not just the large information producers. 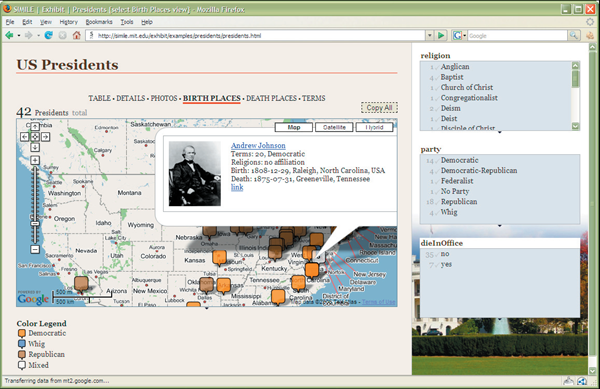
Millions of individuals and small groups publishing through Exhibit do not immediately contribute to a usable Semantic Web. Data from different sources might fit into the same data model, but the schemas from those sources will not readily align. We are in the process of designing user interfaces that allow naive users, not programmers or data modeling experts, to recombine data from disparate sources and get value out of the aggregate. AcknowledgementsThis work is being done in the Haystack group [6], the User Interface Design group [7], and the Simile project [8]. It has been supported by the National Science Foundation, the Biomedical Informatics Research Network, and Nokia. References[1] W3C Semantic Web Activity. http://www.w3.org/2001/sw/. [2] David F. Huynh, Stefano Mazzocchi, David R. Karger. Piggy Bank: Experience the Semantic Web Inside Your Web Browser. In The Proceedings of the International Semantic Web Conference, Galway, Ireland, November 2005. [pdf] [3] David F. Huynh, Robert C. Miller, David R. Karger. Enabling Web Browsers to Augment Web Sites' Filtering and Sorting Functionality. In The Proceedings of the User Interface Software Technology Conference, Montreux, Switzerland, October 2006. [screencast, pdf] [4] David F. Huynh, David R. Karger, Robert C. Miller. Exhibit: Lightweight Structured Publishing Framework. In The Proceedings of the World Wide Web Conference, Banff, Canada, May 2007. [pdf] [5] The Long Tail. http://en.wikipedia.org/wiki/Long_tail. [6] Haystack project. http://haystack.csail.mit.edu/. [7] User Interface Design group. http://groups.csail.mit.edu/uid/. [8] Simile project. http://simile.mit.edu/. |
|||
|