| Research Abstracts Home | CSAIL Digital Archive | Research Activities | CSAIL Home |
![]()
|
Research
Abstracts - 2007
|
|
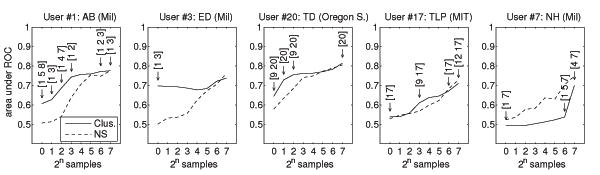
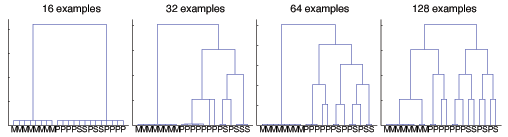
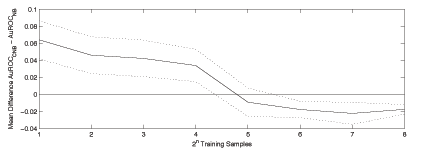
Efficient Bayesian Task-Level Transfer LearningDaniel M. Roy & Leslie Pack KaelblingAbstractWe have shown how using the Dirichlet Process mixture model as a generative model of data sets provides a simple and effective method for transfer learning. In particular, we have developed a hierarchical extension of the classic Naive Bayes classifier that couples multiple Naive Bayes classifiers by placing a Dirichlet Process prior over their parameters and have shown how recent advances in approximate inference in the Dirichlet Process mixture model enable efficient inference. We have evaluated the resulting model in a meeting domain, in which the system decides, based on a learned model of the user's behavior, whether to accept or reject the request on his or her behalf. The extended model outperforms the standard Naive Bayes model by using data from other users to influence its predictions. IntroductionIn machine learning, we are often confronted with multiple, related data sets and asked to make predictions. For example, in spam filtering, a typical data set consists of thousands of labeled emails belonging to a collection of users. In this sense, we have multiple data sets---one for each user. Should we combine the data sets and ignore the prior knowledge that different users labeled each email? If we combine the data from a group of users who roughly agree on the definition of spam, we will have increased the available training data from which to make predictions. However, if the preferences within a population of users are heterogeneous, then we should expect that simply collapsing the data into an undifferentiated collection will make our predictions worse. The process of using data from unrelated or partially related tasks is known as transfer learning or multi-task learning and has a growing literature [1,2,3,4]. While humans effortlessly use experience from related tasks to improve their performance at novel tasks, machines must be given precise instructions on how to make such connections. In this paper, we introduce such a set of instructions, based on the statistical assumption that there exists some partition of the tasks into clusters such that the data for all tasks in a cluster are identically distributed. Ultimately, any such model of sharing must be evaluated on real data, and, to that end, we evaluate the resulting model in a meeting domain. The learned system decides, based on training data for a user, whether to accept or reject the request on his or her behalf. The model that shares data outperforms its no-sharing counterpart by using data from other users to influence its predictions. When faced with a classification task on a single data set, well-studied techniques abound [5,6]. A popular classifier that works well in practice, despite its simplicity, is the Naive Bayes classifier [7]. We can extend this classifier to the multi-task setting by training one classifier for each cluster in the latent partition. To handle uncertainty in the number of clusters and their membership, we define a generative process for data sets that induces clustering. At the heart of this process is a non-parametric prior known as the Dirichlet Process. This prior couples the parameters of the Naive Bayes classifiers attached to each data set. This approach extends the applicability of the Naive Bayes classifier to the domain of multi-task learning when the tasks are defined over the same input space. Bayesian inference under this clustered Naive Bayes model combines the contribution of every partition of the data sets, weighing each by the partition's posterior probability. However, the sum over partitions is intractable and, therefore, we employ recent work by [8] to implement an approximate inference algorithm. The result is efficient, task-level transfer learning. ResultsThe utility of the type of sharing that the Clustered Naive Bayes supports can only be assessed on real data sets. To that end, we evaluated the model's predictions on a meeting classification data set collected by [9]. The data set is split across 21 users from multiple universities, an industry lab and a military training exercise. In total, there are 3966 labeled meeting requests, with 100-400 meeting requests per user. In the meeting acceptance task, we aim to predict whether a user would accept or reject an unseen meeting request based on a small set of features that describe various aspects of the meeting. To evaluate the clustered model, we assessed its predictive performance in a transfer learning setting, predicting labels for a user with sparse data, having observed all the labeled data for the remaining users. In particular, we calculated the receiver-operator characteristic (ROC) curve having trained on 1, 2, 4, 8, 16, 32, 64, and 128 training examples for each user (conditioned on knowledge of all labels for the remaining users). Each curve was generated according to results from twenty random partitions of the users' data into training and testing sets. Figure 1 plots the area under the ROC curve as a measure of classification performance versus the number of training examples. From the 21 users, we have selected five representative samples. The first three examples (users 1, 3 and 20) show how the model performs when it is able to use related user's data to make predictions. With a single labeled data point, the model groups user 1 with two other military personnel (users 5 and 8). While at each step the model makes predictions by averaging over all tree-consistent partitions, the MAP partition listed in the figure has the largest contribution. For user 1, the MAP partition changes at each step, providing superior predictive performance. However, for the third user in the second figure, the model chooses and sticks with the MAP partition that groups the first and third user. In the third example, User 20 is grouped with user 9 initially, and then again later on. Roughly one third of the users witnessed improved initial performance that tapered off as the number of examples grew. The fourth example (user 17) illustrates that, in some cases, the initial performance for a user with very few samples is not improved because there are no good candidate related users with which to cluster. Finally, the last example shows one of the four cases where predictions using the clustered model leads to worse performance. In this specific case, the model groups the user 7 with user 1. It is not until 128 samples that the model recovers from this mistake and achieves equal performance. Figure 2 shows the trees and corresponding partitions recovered by the BHC algorithm as the number of training examples for each user is increased. Inspecting the partitions, they fall along understandable lines; military personnel are most often grouped with other military personnel, and professors and SRI researchers are grouped together until there is enough data to warrant splitting them apart. Figure 3 shows the relative performance of the clustered versus standard Naive Bayes model. The clustered variant outperforms the standard model when faced with very few examples. After 32 examples, the models perform roughly equivalently, although the standard model enjoys a slight advantage that does not grow with more examples. DiscussionThe central goal of this work was to evaluate the Clustered Naive Bayes model in a transfer-learning setting. We measured its performance on a real-world meeting acceptance task, and showed that the clustered model can use related users' data to provide better prediction even with very few examples. The Clustered Naive Bayes model uses a Dirichlet Process prior to couple the parameters of several models applied to separate tasks. This approach is immediately applicable to any collection of tasks whose data are modelled by the same parameterized family of distributions, whether those models are generative or discriminative. This paper suggests that clustering parameters with the Dirichlet Process is worthwhile and can improve prediction performance in situations where we are presented with multiple, related tasks. A theoretical question that deserves attention is whether we can get improved generalization bounds using this technique. A logical next step is to investigate this model of sharing on more sophisticated base models and to relax the assumption that users are exactly identical. More InformationSee Daniel Roy's website. Research SupportThis material is based upon work supported by the Defense Advanced Research Projects Agency (DARPA), through the Department of the Interior, NBC, Acquisition Services Division, under Contract No. NBCHD030010. References:[1] S. Thrun. Is learning the n-th thing any easier than learning the first? NIPS, 1996. [2] J. Baxter. A model of inductive bias learning. JAIR, 12, 2000. [3] C. Guestrin, D. Koller, C. Gearhart, and N. Kanodia. Generalizing Plans to New Environments in Relational MDPs. IJCAI, 2003. [4] Y. Xue, X. Liao, L. Carin, and B. Krishnapuram. Learning multiple classifiers with Dirichlet process mixture priors. NIPS, 2005. [5] B. E. Boser, I. M. Guyon, and V. N. Vapnik. A training algorithm for optimal margin classifiers. COLT, 1992. [6] J. Lafferty, A. McCallum, and F. Pereira. Conditional Random Fields: Probabilistic Models for Segmenting and Labeling Sequence Data. ICML, 2001. [7] M. E. Maron. Automatic indexing: An experimental inquiry. JACM, 8(3), 1961. [8] K. Heller and Z. Ghahramani. Bayesian Hierarchical Clustering. ICML, 2005a. [9] M. Rosenstein, Z. Marx, L. P. Kaelbling, and T. G. Dietterich. Transfer Learning with an Ensemble of Background Tasks. NIPS Workshop on Inductive Transfer , 2005. |
|||
|