
| Research Abstracts Home | CSAIL Digital Archive | Research Activities | CSAIL Home |
![]()
|
Research
Abstracts - 2007
|
|
Speech-Based Annotation and Retrieval of PhotographsTimothy J. Hazen, Brennan Sherry & Mark AdlerIntroductionWith the incredible growth of digital photography over the last decade comes many new and interesting problems surrounding how people should organize, store, and retrieve their photos. Unlike textual data, automatic methods for describing, indexing and retrieving visual media such as photographs do not exist. Existing photograph search engines typically rely on manually generated text-based annotations of photographs. An obvious extension to existing text-based systems is to incorporate speech. Towards this goal, we have developed a prototype speech-based annotation and retrieval system for repositories of digital photographs [1]. As an input modality, speech has several advantages over text. First, speech is more efficient than text. A vast majority of people can speak faster than they can type or write, which can make the process of annotating photos faster. Second, speech input does not require a keyboard or pen-based tablet. Thus, annotations could be recorded on small devices, such as digital cameras, at the time and in the setting that a photograph is taken. Some existing commercial digital cameras already possess this audio annotation capability. Finally, speech is more efficient that graphical interfaces for conveying complex properties. Thus, when retrieving a photograph, it is much easier to specify a set of constraints (e.g., when a photo was taken, who took it, where was it taken, what is in the photograph, etc.) within a spoken utterance than within a series of graphical pull-down menus, check-boxes, or text-based search bars. System OverviewOur photo annotation and retrieval system is currently comprised of two basic subsystems, one for annotating photos and one for retrieving. For this work, we assume a scenario in which a person uses a mobile device, such as a digital camera or camera phone, to both take a photograph and record a personalized spoken annotation. The photographs could then be retrieved at a later time from a repository using a spoken query. In our experiments, a Nokia N80 mobile camera phone was used as the mobile device for annotating photographs. To create a initial database of photographs with annotations, test users were provided with the N80 camera phones and given two options for generating photographs. They could either download existing photographs from their personal collection onto the device or they could use the device to take new photographs. 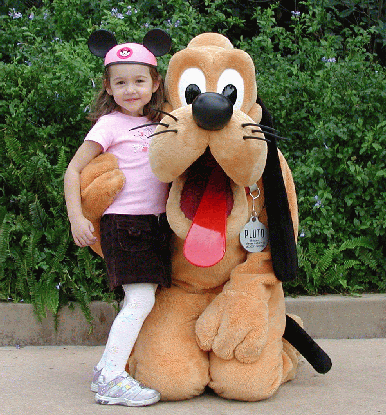 Figure 1: Example photograph from the photo annotation database. Given a set of photos, users record verbal annotations for each photograph
in the set using an annotation application that is run on the phone.
Annotations are recorded using an 8kHz sampling rate. For maximum
flexibility, the user is not restricted in any way when they provide
these free-form annotations. As an example, the photograph shown in
Figure 1 above could be annotated by the user as: Julia and Pluto at Disney World.
When using the retrieval subsystem, the user can speak a verbal
query to specify the attributes of the photographs they wish to
retrieve. The system must handle queries that contain information
related to either the metadata and/or the free-form annotations.
For example, the user could refer back to the photo shown in Figure
1 with a query such as: Show me John Doe's photo of Julia with Pluto
at Disney World from December of 2005.
Annotation ProcessingSpoken annotations are automatically transcribed by a general purpose large vocabulary speech recognition system. In our experiment, the MIT SUMMIT system was used for recognition. A trigram language model was trained from data obtained from two sources: the Switchboard corpus and a collection of photo captions scraped from an online repository of digital photographs with accompanying text annotations (i.e., www.webshots.com). The language model training set contained roughly 3.1M total words from 262K Switchboard utterances and 5.3M words from 1.3M Webshots captions. A vocabulary of 37665 words was selected from the most common words in the training corpus. The acoustic model was trained from over 100 hours of speech collected by telephone-based dialogue systems at MIT. Because of the nature of the task, photo annotations are very likely to contain proper names of people, places or things that are not covered by the recognizers modestly sized vocabulary. In addition to these out-of-vocabulary words, potential mismatches between the training materials and the actual data collected by the system would also be expected to cause speech recognition errors. To compensate for potential misrecognitions, alternate hypotheses can be generated by the recognition system, either through an n-best list or a word lattice. The resulting recognition hypotheses are indexed in a term database for future look-up by the retrieval process. Query ProcessingTo handle photograph retrieval queries, such as the one shown above, we need to be able to recognize and parse queries that may contain several different constituent parts. For examples queries may contain initial carrier phrases (e.g. "Show me photos of..."), constraint phrases about metadata information (e.g."...taken in December of 2005"), or open ended phrases referring to content in the annotations (e.g., "Julia and Pluto at Disney World"). To handle such phrases, the system must both recognize the words in the utterances and be able to parse them into their constituent parts. To perform this task we have developed a mixed-grammar recognition approach which simultaneously recognizes and parses the utterance. In our approach the system integrates both context-free grammars and statistical n-gram models into a single search network. The speech recognition network uses constrained context-free grammars for handling the initial carrier phrases and the phrases for specifying metadata. A large vocabulary statistical n-gram model is used to recognize the free form annotation terms. The context-free grammars and n-gram model are converted into finite-state networks and combined within a single search network which allows the system to move between the grammars when analyzing the spoken utterance. Figure 2 below shows the network configuration that the system currently uses. For the query utterance introduced above, the words "Show me John Doe's photo of" would be handled by the initial context-free grammar subnetwork, the words "Julia and Pluto at Disney World" would be handled by the free-form n-gram model, and the words "from December of 2005" would be handled by the final context free grammar. 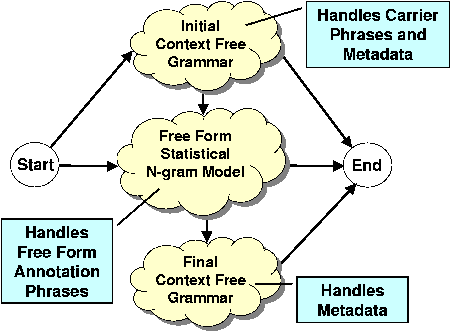 Figure 2: Overview of the flow of subnetworks combined to form the full mixed-grammar finite state network used by the query recognizer. The structure of the final network represented in Figure 2 provides the user with a large degree of freedom in specifying their query. For example, the user could forego the use of an carrier or metadata phrase, and just speak a phrase contain free-form annotation search terms (e.g. "Julia and Pluto at Disney World"), or they could forego the use of free-form annotation terms and speak only about metadata (e.g. "Show me John Doe's photos from December 2005."). In the worst case, if a user speaks a carrier phrase or metadata expression that is not covered by the context-free grammar, this expression would simply be handled by the n-gram model and treated as free-form search terms.
The query recognizer uses the annotation recognizer as
it's initial starting point. The statistical n-gram model
used by the query recognizer as well as the acoustic models
are identical to those of the annotation recognizer. As
with the annotation recognizer, the query recognizer can
also produce an N-best list of utterance hypotheses to
help compensate for recognition errors and hence improve
recall when misrecognitions in the top-choice utterance
occur. The SUMMIT speech recognition system uses a finite-state
transducer (FST) representation which allows it to transduce
the parse structure and lexical content contained in the
recognizer's network into a structured output format.
In our case, recognized queries are automatically transduced
and into an output XML format by the recognizer. For example,
the XML representation which would be generated for the
example query discussed above is as follows: Photo RetrievalPhotos are retrieved using an or-based word search sorted by a weighted TF-IDF (term frequency-inverse document frequency) score. First, all stop words (i.e., non-content words such as articles, prepositions, etc.) are removed from the search term list of the query's N-best list. Then, for each word remaining in the list of search terms, the database is queried and a list of photos containing that term is returned. Each search term yields a TF-IDF score for each photo calculated from information in the database. The TF-IDF score for an annotation term in a particular photo is based on the term's frequency in the entire annotation N-best list, and not just the recognizer's top-choice answer. The returned TF-IDF score for a term for a particular photo is further weighted by the number of occurrences of the term in the query N-best list. This weighting scheme inherently prefers words which exhibit less confusion in the recognition N-best lists. The weighted TF-IDF scores from each term are then summed to produce the total score for each photo, and all retrieved photos are sorted by their final summed score. The returned list of photos from the search term retrieval can be further intersected with the list of photos returned by a standard relational database search for the requested metadata constraints. SummaryAll of the functionality discussed above has been implemented within a client/server architecture in which photographs are first taken and annotated on a client camera phone. The photographs and audio annotations are sent over a data connection to the photo annotation server for transcription and indexing into a photo database. The photos can then be retrieved at a later time from the server via a spoken request from the phone. This audio request is processed by the photo retrieval server and relevant photographs are returned to the user's client phone for browsing. A web-based version of the retrieval system has also been implemented.Acknowledgements This research was supported by Nokia as part of a joint MIT-Nokia collaboration. References[1] S. Seneff, M. Adler, J. Glass, B. Sherry, T. Hazen, C. Wang, and T. Wu. Exploiting Context Information in Spoken Dialogue Interaction with Mobile Devices Accepted for presentation. In International Workshop on Improved Mobile User Experience, Toronto, Canada, May 2003. |
|||
|