| Research Abstracts Home | CSAIL Digital Archive | Research Activities | CSAIL Home |
![]()
|
Research
Abstracts - 2007
|
|
Unsupervised Topic Segmentation Over Acoustic InputIgor Malioutov, Alex Park, Regina Barzilay & James GlassIntroductionWe address the task of unsupervised topic segmentation of speech data relying only on raw acoustic information. In contrast to existing algorithms for topic segmentation of speech, our approach does not require input transcripts. Our method predicts topic changes by analyzing the distribution of reoccurring acoustic patterns in the speech signal corresponding to a single speaker. The algorithm robustly handles noise inherent in matching based on acoustic similarity by intelligently aggregating information about distributional similarity from multiple local comparisons. Our experiments show that audio-based segmentation compares favorably with transcript-based segmentation computed over noisy transcripts. These results demonstrate the utility of our method for applications where a speech recognizer is not available, or its output has a high word error rate. Related WorkA variety of supervised and unsupervised methods have been employed to segment speech input. Some of these algorithms have been originally developed for processing written text [1,17]. Others are specifically adapted for processing speech input by adding relevant acoustic features such as pause length and speaker change [4,5]. Researchers have extensively studied the relationship between discourse structure and intonational variation [7,16]. However, all of the existing segmentation methods require as input a speech transcript of reasonable quality. Our work is also related to unsupervised approaches for text segmentation. The central assumption here is that sharp changes in lexical distribution signal the presence of topic boundaries [3,6]. These approaches determine segment boundaries by identifying homogeneous regions within a similarity matrix that encodes pairwise similarity between textual units, such as sentences. Our segmentation algorithm operates over a distortion matrix, but the unit of comparison is the speech signal over a time interval. This change in representation gives rise to multiple challenges related to the inherent noise of acoustic matching, and requires the development of new methods for signal discretization, interval comparison and matrix analysis. Finally, our work is related to research on unsupervised lexical acquisition from continuous speech. These methods aim to infer vocabulary from unsegmented audio streams by analyzing regularities in pattern distribution [2,11,18]. Traditionally, the speech signal is first converted into a string-like representation such as phonemes and syllables using a phonetic recognizer. Park & Glass [12] have recently shown the feasibility of an audio-based approach. The vocabulary is induced from the audio stream directly, avoiding the need for phonetic transcription. Their method can accurately discover words which appear with high frequency in the audio stream. AlgorithmThe audio-based segmentation algorithm identifies topic boundaries by analyzing changes in the distribution of acoustic patterns. The analysis is performed in three steps. First, we identify recurring patterns in the audio stream and compute distortion between them. These acoustic patterns correspond to high-frequency words and phrases, but they only cover a fraction of the words that appear in the input. As a result, the distributional profile obtained during this process is too sparse to deliver robust topic analysis. Second, we generate an acoustic comparison matrix that aggregates information from multiple pattern matches. Additional matrix transformations during this step reduce the noise and irregularities inherent in acoustic matching. Third, we partition the matrix to identify segments with a homogeneous distribution of acoustic patterns.
Given a raw acoustic waveform, we extract a set of acoustic patterns that occur frequently in the speech document. The patterns may not be repeated exactly, but will most likely reoccur in varied forms. We identify acoustically most similar pairs of patterns with a sequence alignment algorithm. The alignment algorithm operates on the audio waveform represented by a list of silence-free utterances. Each utterance is represented as a time series of MFCC vectors. Given a pair of input utterances the algorithm outputs a set of alignments between the corresponding MFCC vectors. The alignment distortion score is computed by summing the Euclidean distances of matching vectors. To compute the optimal alignment we use a variant of the Dynamic time warping algorithm [8]. Alignments with a distortion exceeding a prespecified threshold are pruned away to ensure that the aligned phrasal units are close acoustic matches. Table 1 shows examples of alignments automatically computed by our algorithm. The corresponding phonetic transcriptions demonstrate that the matching procedure can robustly handle variations in pronunciations. For example, two instances of the word ``direction'' are matched to one another despite different pronunciations, (``d ay'' vs. ``d ax'' in the first syllable). At the same time, some aligned pairs form erroneous matches, such as ``my prediction'' matching ``y direction'' due to their high acoustic similarity.
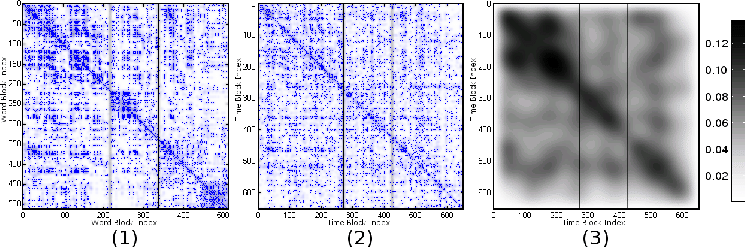
Next, we construct an acoustic comparison matrix that encodes variations in the distribution of acoustic patterns for a given speech data file. We discretize the acoustic signal into constant-length time blocks and then compute the distortion between pairs of blocks. Subsequently, we smooth the acoustic comparison matrix using anisotropic diffusion. This technique has been developed for enhancing edge detection accuracy in image processing [13], and has been shown to be an effective smoothing method in text segmentation [9]. When applied to a comparison matrix, anisotropic diffusion reduces score variability within homogeneous regions of the matrix and makes edges between these regions more pronounced. Consequently, this transformation facilitates boundary detection, potentially increasing segmentation accuracy. In Figure 1 (3), we can observe that the boundary structure in the diffused comparison matrix becomes more salient and corresponds more closely to the reference segmentation. Finally, given a target number of segments k, the goal of the partitioning step is to divide a matrix into k square submatrices along the diagonal. This process is guided by an optimization function that maximizes the homogeneity within a segment or minimizes the homogeneity across segments. This optimization problem can be solved using one of many unsupervised segmentation approaches [3,9,10]. In our implementation, we employ the minimum-cut segmentation algorithm [14,10]. In this graph-theoretic framework, segmentation is cast as a problem of partitioning a weighted undirected graph that minimizes the normalized-cut criterion. ExperimentsWe use a publicly available corpus of 33 introductory Physics lectures to test our system. To evaluate the performance of traditional transcript-based segmentation algorithms on this corpus, we also use several types of transcripts at different levels of recognition accuracy. In addition to manual transcripts, our corpus contains two types of automatic transcripts, one obtained using speaker-dependent (SD) models and the other obtained using speaker-independent (SI) models. The speaker-independent model was trained on 85 hours of out-of-domain general lecture material and contained no speech from the speaker in the test set. The speaker-dependent model was trained by using 38 hours of audio data from other lectures given by the speaker. Both recognizers incorporated word statistics from the accompanying class textbook into the language model. The word error rates for the speaker-independent and speaker-dependent models are 44.9% and 19.4%, respectively. We use the Pk and WindowDiff measures to evaluate our system [1,14]. The Pk measure estimates the probability that a randomly chosen pair of words within a window of length k words is inconsistently classified. The WindowDiff metric is a variant of the Pk measure, which penalizes false positives and near misses equally. For both of these metrics, lower scores indicate better segmentation accuracy. For the baseline comparison system, we use the state-of-the-art mincut text segmentation system by Malioutov & Barzilay [10] . As additional points of comparison, we test the uniform and random baselines. These correspond to segmentations obtained by uniformly placing boundaries along the span of the lecture and selecting random boundaries, respectively.
Table 2 shows the segmentation accuracy of the audio-based segmentation algorithm and three transcript-based segmentors on the set of 30 Physics lectures. Our algorithm yields an average Pk measure of 0.358 and an average Pk measure of 0.370. This result is markedly better than the scores attained by uniform and random segmentations. As expected, the best segmentation results are obtained using manual transcripts. However, the gap between audio-based segmentation and transcript-based segmentation narrows when the recognition accuracy decreases. In fact, performance of the audio-based segmentation beats the transcript-based segmentation baseline obtained using speaker-independent (SI) models (0.358 for AUDIO versus Pk measurements of 0.378 for SI). Future WorkOur segmentation algorithm focuses on one source of linguistic information for discourse analysis -- lexical cohesion. Multiple studies of discourse structure, however, have shown that prosodic cues are highly predictive of changes in topic structure [7,16] In a supervised framework, we can hope to further enhance audio-based segmentation by combining features derived from pattern analysis with prosodic information. We can also explore an unsupervised fusion of these two sources of information; for instance, we can induce informative prosodic cues by using distributional evidence. Another interesting direction for future research lies in combining the results of noisy recognition with information obtained from distribution of acoustic patterns. We hypothesize that these two sources provide complementary information about the audio stream, and therefore can compensate for each other's mistakes. This combination can be particularly fruitful when processing speech documents with multiple speakers or background noise. SupportThis material is based upon work supported under a National Science Foundation Graduate Research Fellowship. Any opinions, findings, conclusions or recommendations expressed in this publication are those of the author(s) and do not necessarily reflect the views of the National Science Foundation. References:[1] D. Beeferman, A. Berger, and J. Lafferty. 1999. Statistical models for text segmentation. Machine Learning, 34(1-3):177210. [2] M. R. Brent. 1999. An efficient, probabilistically sound algorithm for segmentation and word discovery. Machine Learning, 34(1-3):71105. [3] F. Choi. 2000. Advances in domain independent linear text segmentation. In Proceedings of the NAACL, 2633. [4] A. Dielmann, S. Renals. 2005. Multistream dynamic Bayesian network for meeting segmentation. In Proceedings Multimodal Interaction and Related Machine Learning Algorithms Workshop, 7686. [5] M. Galley, K. McKeown, E. Fosler-Lussier, and H. Jing. 2003. Discourse segmentation of multiparty conversation. In Proceedings of the ACL, 562--569. [6] M. Hearst. Multi-paragraph segmentation of expository text. In Proceedings of the ACL , pages 916, 1994. [7] J. Hirschberg, C. H. Nakatani. 1996. A prosodic analysis of discourse segments in direction-giving monologues. In Proceedings of the ACL, 286293. [8] X. Huang, A. Acero, H.-W. Hon. 2001. Spoken Language Processing. Prentice Hall. [9] X. Ji, H. Zha. 2003. Domain-independent text segmentation using anisotropic diffusion and dynamic programming. In Proceedings of SIGIR, 322329. [10] I. Malioutov, R. Barzilay. 2006. Minimum cut model for spoken lecture segmentation. In Proceedings of the COLING/ACL, 2532.
[11] C. G. de Marcken. 1996. Unsupervised Language Acquisition. Ph.D. thesis, Massachusetts Institute of Technology. [12] A. Park, J. R. Glass. 2006. Unsupervised word acquisition from speech using pattern discovery. In Proceedings of ICASSP. [13] P. Perona, J. Malik. 1990. Scale-space and edge detection using anisotropic diffusion. IEEE Transactions on Pattern Analysis and Machine Intelligence, 12(7):629639. [14] L. Pevzner, M. Hearst. 2002. A critique and improvement of an evaluation metric for text segmentation. Computational Linguistics, 28(1):1936.
[15] J. Shi and J. Malik. 2000. Normalized cuts and image segmentation. IEEE Transactions on Pattern Analysis and Machine Intelligence , 22(8):888905. [16] E. Shriberg, A. Stolcke, D. Hakkani-Tur, G. Tur. 2000. Prosody-based automatic segmentation of speech into sentences and topics. Speech Communication, 32(1-2):127154. [17] M. Utiyama and H. Isahara. 2001. A statistical model for domain-independent text segmentation. In Proceedings of the ACL, 499-506. [18] A. Venkataraman. 2001. A statistical model for word discovery in transcribed speech. Computational Linguistics, 27(3):353372. |
|||||||||||||||||||||||||||||||||||||||||||
|