| Research Abstracts Home | CSAIL Digital Archive | Research Activities | CSAIL Home |
![]()
|
Research
Abstracts - 2007
|
|
Hierarchical Spectro-Temporal Models for Speech RecognitionJake Bouvrie, Tony Ezzat & Tomaso PoggioProblem & MotivationWe seek to explore computational approaches for audition that are inspired by computational visual neuroscience. In particular, we seek to leverage recent progress over the past few years in building a biologically-faithful hierarchical, feed-forward system for visual object recognition [13,14]. The system, which was designed to closely match the currently known feed-forward path in the ventral stream in visual cortex, processes 2-D images in a feed-forward, hierarchical way to determine the category and identity of a particular object within that image. The system is capable of recognizing the object in the image irrespective of variations in position, scale, orientation, and in the presence of clutter. Motivated by the success of our architecture for visual object recognition, we propose to explore a similar 2-D hierarchical, feed-forward architecture for auditory object recognition. In particular, we propose to explore whether such a system may be capable of achieving state-of-the-art phonetic recognition (with and without noise). In addition, since it is likely that similar cortical mechanisms are used in both vision and audition, we believe that some of these mechanisms, which are well-known in the vision community, can be used successfully in the auditory domain. Previous WorkRecent work by a number of auditory neurophysiologists [15,9] indicates that there is a secondary level of auditory analysis in the auditory cortex (AI), in which cells in AI analyze and process elements of the underlying input auditory time-frequency image. Measurements of the so-called spectro-temporal receptive fields (STRFs) of cells in AI indicate that they can be tuned to different optimal frequencies, have different spectral scales, and also respond to different temporal rates. Several researches have begun to apply these recent developments in neuroscience to automatic speech recognition. Mesgarani and Shamma [10] have filtered spectrograms of speech sgnals with spectro-temporal kernels derived from recordings in primary auditory cortex of the ferret. Kleinschmidt et al. [8,7] have borrowed the STRF idea, and extracted localized spectro-temporal patterns by convolving speech spectrograms with Gabor functions. They then applied the resulting features to speech recognition tasks involving noisy spoken digits. ApproachThe first stage of the proposed architecture for audition is a pre-processing stage that converts sound from a 1-D signal into a 2-D time-frequency representation using a narrowband short-time Fourier transform (STFT). While there are many phenomena occurring in any single spectrogram, we observe that within small 2-D local patch regions (at both the carrier and the envelope level), the important phenomena are locally stationary and usually quite simple. For example, we find that in harmonic carrier regions there is one locally dominant spectro-temporal frequency and orientation. We propose to exploit this observation and model the harmonic patterns, amplitude envelope, and noisy phonetic components with a smooth representation, and then learn discriminative relationships among the resulting features using a hierarchical model. The final output of the model will then be applied to noise-robust speech recognition tasks. The motivations behind adopting 2-D spectro-temporal patches (at a set of multiple scales and positions) as the basic unit of analysis for speech are three-fold:
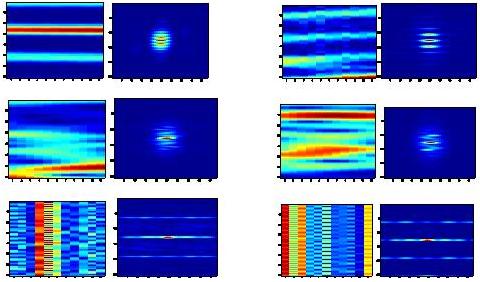
ProgressWe have begun to examine the properties of 2-D Gabor analysis of spectrogram patches, at both the carrier and the envelope levels [3,4]. Shown in Figure 1 are raw spectrogram patches on the left, along with the outputs of a 2-D complex Gabor filterbank decomposition for the corresponding raw patch on the right (magnitude components only). The filterbank outputs shown would in fact constitute the outputs of the S1 layer in the architecture described in [14]. Our initial experiments suggest that 2-D Gabor filter-bank decompositions of patches are capable of identifying the dominant spectro-temporal components in a patch. More importantly, the 2-D Gabor decompositions are themselves useful for further processing. For example, we can perform clustering on the different 2-D Gabor activations to discriminate between different types of patches. We are currently in the process of performing a more thorough analysis of 2-D Gabor decompositions for carrier and envelope patches taken from various phonemes under different noise conditions.
Research SupportThis abstract describes research done at the Center for Biological & Computational Learning, which is in the McGovern Institute for Brain Research at MIT, as well as in the Dept. of Brain & Cognitive Sciences, and which is affiliated with the Computer Science & Artificial Intelligence Laboratory (CSAIL). This research was sponsored by grants from: Office of Naval Research (DARPA) Contract No. MDA972-04-1-0037, Office of Naval Research (DARPA) Contract No. N00014-02-1-0915, National Science Foundation-NIH (CRCNS) Contract No. EIA-0218506, and National Institutes of Health (Conte) Contract No. 1 P20 MH66239-01A1. Additional support was provided by: Central Research Institute of Electric Power Industry (CRIEPI), Daimler-Chrysler AG, Eastman Kodak Company, Honda Research Institute USA, Inc., Komatsu Ltd., Merrill-Lynch, NEC Fund, Oxygen, Siemens Corporate Research, Inc., Sony, Sumitomo Metal Industries, Toyota Motor Corporation, and the Eugene McDermott Foundation. References:[1] Bourlard, H. and S. Dupont (1997). Subband-Based Speech Recognition. Proc. ICASSP, Munich, Germany. . [2] Cooke, M. (2006). "A glimpsing model of speech perception in noise." Journal of the Acoustical Society of America 119: 1562--1573. . [3] Ezzat, T., J. Bouvrie, et al. (2006). Max-Gabor Analysis and Synthesis of Spectrograms. Proc. ICSLP, Pittsburgh, PA. . [4] Ezzat, T., J. Bouvrie, et al. (2007). AM-FM Demodulation of Spectrograms using Localized 2D Max-Gabor Analysis. to appear, ICASSP 2007. [5] Glass, J. R., J. Chang, et al. (1996). A probabilistic framework for feature-based speech recognition. Proc. ICSLP. [6] Hermansky, H. (2003). Data-driven Extraction of Temporal Features from Speech. Proc. ASRU Worshop. . [7] Kleinschmidt, M. (2003). Localized Spectro-temporal Features for Automatic Speech Recognition. Proc. Eurospeech. . [8] Kleinschmidt, M. and D. Gelbart (2002). Improving Word Accuracy with Gabor Feature Extraction. Proc. ICSLP. . [9] Linden, J. F., R.C.Liu, et al. (2003). "Spectrotemporal Structure of Receptive Fields in Areas AI and AAF of Mouse Auditory Cortex." Journal of Neurophysiology 2660. . [10] Mesgarani N., M. Slaney and S. A. Shamma, Content-based audio classification based on multiscale spectro-temporal features, IEEE Transaction on Speech and Audio processing, Volume 14, Issue 3, May 2006 Page(s):920 930.. [11] Morris, A., A. Hagen, et al. (1999). The Full Combination Sub-bands Approach to Noise Robust HMM/ANN-based ASR. Proc. Eurospeech 99. . [12] Rabiner, L. and B. H. Juang (1993). Fundamentals of Speech Recognition. Englewood Cliffs, NJ. . [13] Riesenhuber, M. and T. Poggio (1999). "Hierachical models of object recognition in cortex." Nature Neuroscience 2: 1019--1025. . [14] Serre, T., L. Wolf, et al. (2006). "Object Recognition with Cortex-Like Mechanisms." IEEE Trans. on Pattern Analysis and Machine Intelligence . [15] Theunissen, F., K. Sen, et al. (2000). "Spectral-Temporal Receptive Fields of Nonlinear Auditory Neurons Obtained Using Natural Sounds." Journal of Neuroscience 20(6 ): 2315. . |
|||
|