| Research Abstracts Home | CSAIL Digital Archive | Research Activities | CSAIL Home |
![]()
|
Research
Abstracts - 2007
|
|
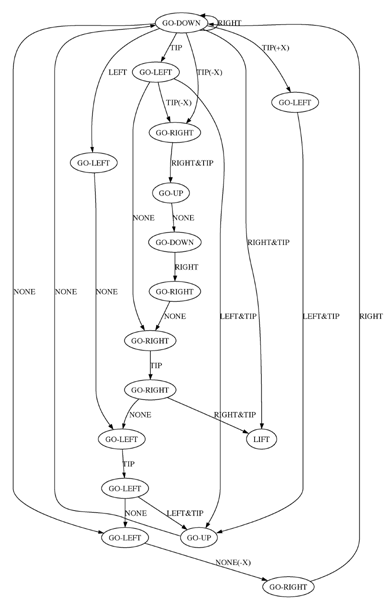
Grasping POMDPsKaijen Hsiao & Leslie Pack Kaelbling & Tomás Lozano-PerézThe ProblemGrasping objects with robots in real life involves a great deal of uncertainty. Cameras can tell you roughly where an object is, but not exactly. You may have a model of the object you see, but your model may be off somewhat. Contact sensors can be noisy, and your actions may not have the results you hoped for. One typical method for dealing with all this uncertainty could be termed the 'grab and hope' method, which uses the best current estimates for all of the above to create a plan for grasping. However, plans generated in this way are often brittle--if the object isn't quite where you thought it was, attempting to grasp can result in catastropic failure. Another way to deal with the uncertainty is to use a worst-case model of sensor and motion error, and to compute plans that will always work under these assumptions [2]. However, this forces you to be overconservative. Instead, we'd like to deal with the uncertainty probabilistically, generating robust plans that are likely to succeed even when your actions don't quite do what you wanted them to, your contact sensors are feeding you noisy information, and the object isn't quite where you expected. Current ApproachWe model the grasping problem as a partially observable Markov decision process (POMDP). As long as we can provide reasonable probabilistic models of the sensor and action noise, we can generate 'optimal' control policies that have a fair chance of succeeding even in the face of large uncertainty. However, modeling systems as POMDPs requires the state, action, and observation spaces to be quite small in order for planning to be tractable. Thus, we choose actions that 'funnel' large portions of the state space into smaller ones. Our actions are guarded, compliant moves that move in a direction until the observed contacts change (move until contact/workspace boundary hit if in free space, or slide until new contact/contact breaks/workspace boundary hit if already touching something). This choice of action space allows us to partition our world into a small set of discrete states, since parts of the configuration space that have the same reward and observations and that result in the same next state under any action can be grouped together. If we assume temporarily that our actions always have the expected funnelling results, we can use a deterministic (geometry-based) simulation of our world to record the expected state transitions and observations under our selected actions and generate our state space. Because actions don't actually always lead to expected results, we model the action and sensor noise by adding a small amount of stochasticity to our expected transitions and observations. Finally, we feed our POMDP model, which is still infeasible to solve exactly, into HSVI [4], which uses point-based value iteration to generate a reasonable policy, and test it in a physics-based simulation using Open Dynamics Engine (ODE) [3]. Current ResultsOur current results are all in 2-D worlds. In one scenario, we have a one-fingered hand trying to position its fingertip at the left middle corner of a stepped block, as in Figure 3. From there, one could swing a thumb into position to grasp the top part of the block, to insert the bottom part into a hole. Figure 1 shows the deterministic policy for this scenario created by solving the POMDP with no stochasticity added in. Figure 2 shows the policy for the noisy POMDP with stochasticity added in. Rewards are +15 for reaching the goal and lifting, -50 for lifting anywhere else, -1 for each move, and -5 for hitting a workspace boundary. In the simulation, the actions and observations are extremely noisy--sliding actions can get stuck, the finger falls off the corner sometimes, and the sensors give incorrect information some of the time (the probabilities are modeled after experiments with a real-world Barrett Arm/Hand). Thus, even a hand-designed, cautious fixed policy consisting of moving left, down, right, right, up, right, right, right (LDRRURRR) succeeds in only 154 out of 190 trials (81%), with an average reward of -10.632. The stochastic POMDP policy, on the other hand, succeeded in 466 out of 506 trials (92%), with an average reward of -1.59. This is despite the fact that the nominal behavior of actions in the deterministic (geometry-based) simulation that was used to generate the action and observation model is significantly different than the nominal behavior of actions in the physics-based simulation, suggesting that even a small amount of stochasticity is enough to deal with a large amount of uncertainty. A sample sequence of actions is shown in Figure 3.
In a second scenario, a two-fingered hand is trying to grasp and lift a block. The rewards, action model, and observation model are the same as in the previous scenario. In this case, a hand-designed, cautious fixed policy of LDRRURRDDDG succeeded in 86 of 113 trials (76%), with an average reward of -17.24, as opposed to the POMDP policy, which succeeded in 115 of 115 trials (100%), with an average reward of 4.0. A sample sequence of actions is shown in Figure 4. For more details about our approach and results, see [1].
What's NextHere's a list of the directions we are trying to go in now:
-Using information from proprioception/vision -Generating more accurate sensor/motion models from limited experimentation (sampling) -Dealing with incorrect or incomplete geometric models of objects Research SupportThis research was supported in part by DARPA IPTO Contract FA8750- 05-2-0249, Effective Bayesian Transfer Learning, and in part by the Singapore-MIT Alliance agreement dated 11/6/98. References:[1] Kaijen Hsiao & Leslie Pack Kaelbling & Tomás Lozano-Peréz. Grasping POMDPs. To appear in Proceedings of ICRA, Rome, Italy, April 2007. [2] Tomás Lozano-Peréz, Matthew Mason, and Russell H. Taylor. Automatic synthesis of fine-motion strategies for robots. International Journal of Robotics Research, 3(1), 1984. [3] Russell Smith. Open Dynamics Engine, www.ode.org, 2007. [4] Trey Smith and Reid Simmons. Heuristic search value iteration for pomdps. In AUAI 04: Proceedings of the 20th Conference on Uncertainty in Artificial Intelligence, pp. 520527, Arlington, Virginia, United States, 2004. |
|||
|