| Research Abstracts Home | CSAIL Digital Archive | Research Activities | CSAIL Home |
![]()
|
Research
Abstracts - 2007
|
|
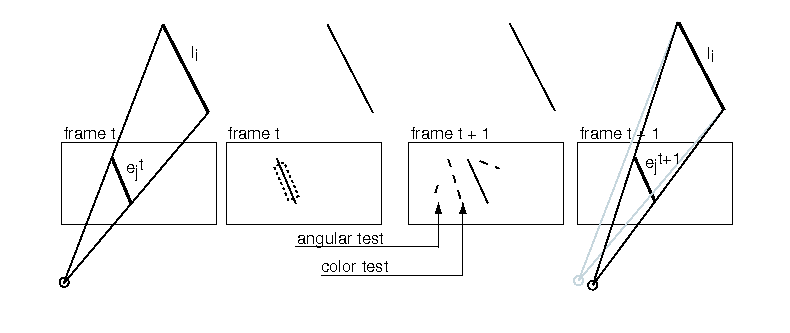
Wide-Area Egomotion From Omnidirectional Video and Coarse 3D StructureOlivier Koch & Seth TellerIntroductionLarge-scale localization is still a challenge today. With applications in mobile robotics and pervasive computing, the problem is to recover the 3D motion of a camera (rotation and translation) within an extended, cluttered environment. Existing SLAM approaches (Simultaneous Localization and Mapping) attempt to reconstruct both the camera motion and the 3D structure of the environment at the same time. Although the results are promising, these methods usually suffer from drift and unbounded computation time (as the size of the exploration space grows) and are unable to deal with large environments. Our method takes as input a coarse 3D model of the environment and an omnidirectional video sequence and produces as output a 6-DOF reconstruction of the camera motion in the model coordinates. Our method makes three major assumptions. First, the camera is calibrated. Second, the motion of the camera is smooth. Third, the environment contains prominent straight line segments. Our method handles extended, cluttered environment and shows a localization accuracy of approximately 15 cm in translation and two degrees in rotation. ContributionOur method is novel in the following aspects. First, it uses an offline visibility precomputation based on GPU to dramatically accelerate the image-to-model matching process. Second, it uses omnidirectional images in order to support full view freedom. Third, the method scales to large, real-world environments. Fourth, it solves for the initialization problem given a three-meter wide uncertainty seed provided by the user. And finally, the method is robust to significant clutter and transient motion. Our approach
Maintenance phase
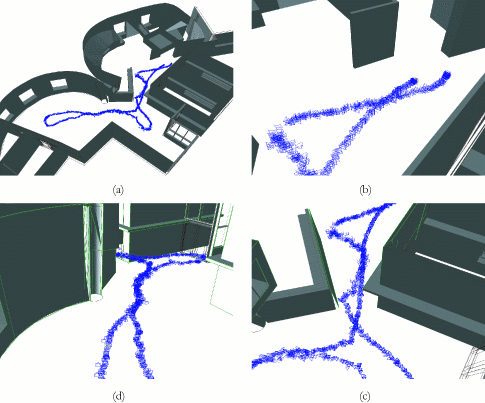
ResultsWe demonstrate our method on several real-world sequences.
Future workWe are currently following several promising directions. First, a geometric signature-based initialization would enable the method to quickly eliminate inconsistent locations and cut down the number of regions in which to run the initialization algorithm. Second, integration of an inertial sensor and a camera motion model would increase the robustness of the maintenance phase. Third, we will investigate tracking of points in addition to line segments. Finally, an online update of the model combined with occlusion processing would further decrease the occurrence of false matches. References:[1] A. Ansar and K. Daniilidis. Linear pose estimation from points or lines. ECCV, edited by A. Heyden et al., Copenhagen, Denmark, 4:282--296, May 2002. [2] Adrien Bartoli and Peter Sturm. Structure from motion using lines: Repre- sentation, triangulation and bundle adjustment. Computer Vision and Image Understanding, 100(3):416--441, December 2005. [3] P. A. Beardsley, A. Zisserman, and D. W. Murray. Sequential updating of pro- jective and a±ne structure from motion. Int. J. Comput. Vision, 23(3):235--259, 1997. [4] A. Davison, Real-Time Simultaneous Localisation and Mapping with a Single Camera, Proc. International Conference on Computer Vision, Nice, Oct 2003. [5] M. Dhome, M. Richetin, and J.-T. Lapreste. Determination of the attitude of 3D objects from a single perspective view. IEEE Trans. Pattern Anal. Mach. Intell., 11(12):1265--1278, 1989. [6] T. Drummond and R. Cipolla. Real-time visual tracking of complex structures. IEEE Trans. Pattern Anal. Mach. Intell., 24(7):932--946, 2002. [7] Olivier Faugeras, Quang-Tuan Luong, and T. Papadopoulou. The Geometry of Multiple Images: The Laws That Govern The Formation of Images of A Scene and Some of Their Applications. MIT Press, Cambridge, MA, USA, 2001. [8] B.K.P. Horn. Closed form solutions of absolute orientation using unit quater- nions. Journal of the Optical Society of America, 4(4):629--642, April 1987. [9] D. G. Lowe. Distinctive image features from scale-invariant keypoints. In- ternational Journal of Computer Vision, 60(2):91--110, 2004. [10] E. Rosten and T. Drummond. Fusing points and lines for high performance tracking. IEEE International Conference on Computer Vision, 2:1508--1515, 2005. [11] Sim, R. and Elinas, P. and Griffin, M. and Shyr, A. and Little, J.J., Design and analysis of a framework for real-time vision-based SLAM using Rao-Blackwellised particle filters, CRV06, p. 21, 2006. [12] C. J. Taylor and D. J. Kriegman. Structure and motion from line seg- ments in multiple images. IEEE Transactions on Pattern Analysis and Machine Intelligence, 17(11):1021--1032, 1995. |
|||||||||||||||||||
|