| Research Abstracts Home | CSAIL Digital Archive | Research Activities | CSAIL Home |
![]()
|
Research
Abstracts - 2007
|
|
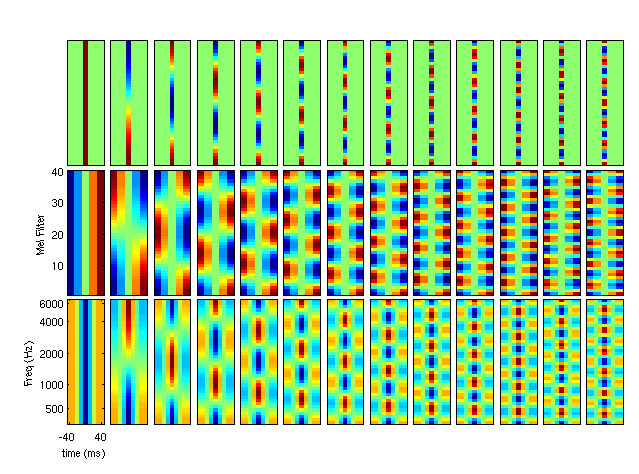
Features and Classifiers for Robust Automatic Speech RecognitionKen Schutte & James GlassAbstractWhile automatic speech recognition (ASR) performance has been steadily improving, there are numerous indications that at the low-levels of acoustic modeling and phonetic recognition, the best ASR systems are still substantially worse than humans [15]. Despite a considerable amount of research in this area, the signal representations and acoustic models typically used in ASR have changed very little over the past several decades [13]. This work attempts to describe currently used signal representations as special cases of a more general framework of detecting relevant spectro-temporal patterns within a time-freqeuncy image (e.g. a spectrogram). By working within this framework to explore new signal representations, and by utilizing discriminitive classifiers, we seek to improve ASR performance, particularly in the presence of noise. Time-Frequency RepresentationsOne of the dominant signal representations currently used in ASR are Mel-frequency cepstral coefficients (MFCCs) [5]. In this representation, a Fourier-based short-time spectral analysis is converted to the Mel-Frequency scale to roughly approximate the frequency sensitivity of the inner ear. The log energies in the warped spectral coefficients are then processed via a discrete cosine transform (DCT) into a low dimensionality feature vector. A common ASR analysis is to generate a 13 dimensional MFCC vector every 10 ms [13]. This feature vector is often augmented with first and second order derivatives, resulting in a 39 dimensional feature vector. Alternative low-dimensionality representations of short-time spectra, such as perceptual linear prediction (PLP) coefficients [6] have also commonly been used. MFCC (and other similarly-derived feature sets) can be viewed as a special case of linear transforms of an underlying two-dimensional time-frequency (T-F) representation. For the case of 39-MFCC features, the initial T-F representation would be a series of Mel-frequency spectral coefficients (MFSC) (essentially a Mel-warped spectrogram). The additional steps (the DCT and two derivatives) are both linear and can thus be described with a single linear operation. With this interpretation, the 39-dimensional vector can be viewed as a set of 39 "patches" which are to be convolved with the MFSC time series. These patches are shown in Figure 1.
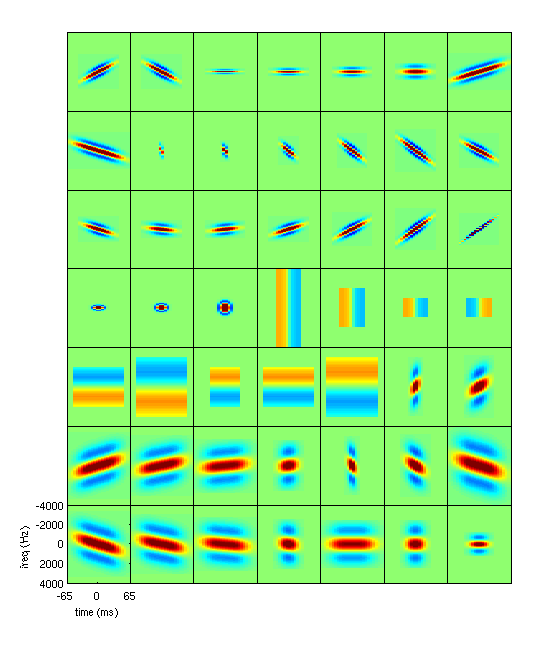
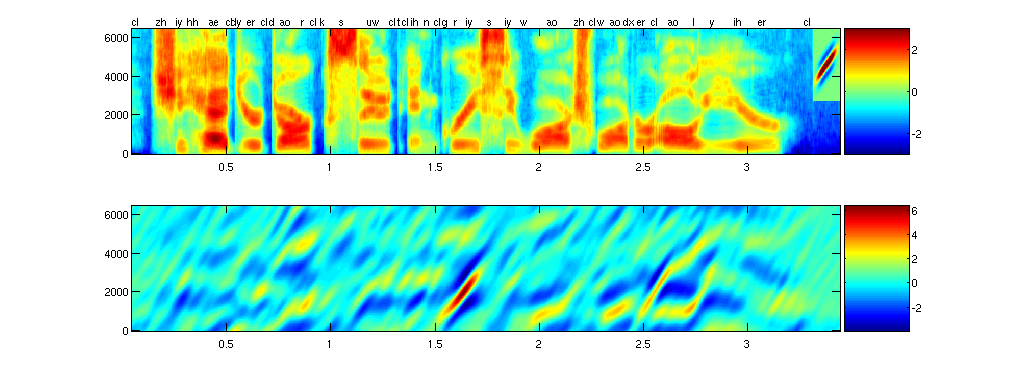
Subjectively, the patterns that these patches are "looking for" (in a matched-filter sense) do not correspond well to known acoustic phonetic phenomena [14]. However, taken as a whole, their outputs do a fair job in representing phonetic units, which makes subsequent classification possible. However, they are not very robust to background noise, channel noise, speaker variations, etc. [1], and could likely be improved. Proposed FeaturesBy adopting the more general view of features being extracted from a T-F image (by convolving patches), it would appear unlikely that those in Figure 1 would be the optimal set. There are many possibilities for designing such filters, but one possible approach for designing a set of patches is to utilize knowledge of acoustic phonetics. One can create a hand-designed set of detectors, each matching specific T-F time-frequency patterns which are known to be crucial for phonetic identification (or more importantly, phonetic discrimination). Such patterns will include, for example, formant locations, trajectories and bandwidths; burst locations; frication cutoff frequencies, etc [12]. An example set of possible filters is shown in Figure 2. Figure 3 shows an example of using one such filter, which is tuned to a distinct formant transition. This figure shows the result of convolving the filter with a wideband spectrogram, highlighting closely matching T-F regions.
Clearly, the proposed filter set of Figure 2 is quite different in nature than the standard representations (Figures 1 and 2). Several possible benefits over standard methods include,
Related WorkThere has been other work attempting to move away from frame-based features and utilizing more general T-F regions. One example which has shown benefits is the use of so-called TRAP features [7], which are features computed across a single frequency band over wide time ranges (up to 500ms or more). This is a case of using long verizontal patches as opposed to the tall vertical patches of MFCCs. The TRAP parameters are different for each frequency band and are learned from training data. The considerable work in sub-band ASR [2,9] can also be considered as a special case in which patches like Figure 1 are used, but modified to only cover a portion of the total frequency range. Recent work in auditory neuroscience suggests that a major function of the primary auditory cortex may be computing ``features'' very similar to convolving ``patches'' over the T-F image generated in the cochlea [3,4]. A computational model of the auditory cortex has been proposed [4] which is essentially a 2D wavelet transform over an auditory spectrogram. Individual neurons are tuned to detect very specific patterns (referred to as a spectro-temporal receptive fields, or STRFs) tuned to particular modultion rates in both time and frequency. The work of [8] was an initial attempt to incorporate these ideas into ASR features, using STRFs modeled as 2-D Gabor filters. We believe that the T-F patches we plan to explore have interesting parallels with these biologically motivated features. Research DirectionsThe ideas mentioned above can lead to a variety of related experiments. The areas we plan to focus on can roughly be divided into features and classifiers.
Evaluation with ASRSome preliminary results suggest that phonetically-inspired features can achieve competitive results with baseline MFCC-based features on phonetic classification tasks. However, we feel that working on full recognition tasks will be a better way to continue this line of research. A baseline HMM recognizer on the Aurora corpus of noisy digits has been set up, which offers a good task for evaluating ASR front-ends. Our current goal consists of trying to improve ASR performance on the Aurora dataset by incorporating novel features and discriminitive classifiers into an existing ASR system. References[1] H. Bourlard, H. Hermansky, and N. Morgan. Towards increasing speech recognition error rates. Speech Communication, 18:205-231, 1996. [2] H. Bourlard and S. Dupont. A new ASR approach based on independent processing and recombination of partial frequency bands. In International Conference on Spoken Language Processing, pages 426-429, 1996. [3] B. Calhoun and C. Schreiner. Spectral envelope coding in cat primary auditory cortex. J. Aud. Neuroscience, 1:39-61, 1995. [4] T. Chi, P. Ru, and S. Shamma. Multiresolution spectrotemporal analysis of complex sounds. Journal of the Acoustical Society of America, 118:887-906, 2005. [5] S. Davis and P. Mermelstein. Comparison of parametric representation for monosyllable word recognition in continuously spoken sentences. IEEE Transactions on Acoustics, Speech, and Signal Processing, 28:357-366, Aug 1980. [6] H. Hermansky. Perceptual linear predictive (PLP) analysis of speech. Journal of the Acoustical Society of America 87(4):1738-1752, April 1990. [7] H. Hermansky and S. Sharma. Temporal patterns (TRAPS) in ASR of noisy speech. In International Conference on Acoustics, Speech, and Signal Processing, 1997. [8] M. Kleinschmidt. Localized spectro-temporal features for automatic speech recognition. In Eurospeech, 2003. [9] J. McAuley, J. Ming, D. Stewart, and P. Hanna. Subband correlation and robust speech recognition. IEEE Transactions on Speech and Audio Processing, 13:956-964, 2005. [10] R. M. Rifkin. Everything Old Is New Again: A Fresh Look at Historical Approaches to Machine Learning. PhD thesis, Massachusetts Institute of Technology, 2002. [11] R. Rifkin, K. Schutte, M. Saad, J. Bourvie, and J. Glass. Noise robust phonetic classification with linear regularized least squares and second-order features. To appear in ICASSP 2006. [12] K. N. Stevens. Acoustic Phonetics. The MIT Press, Cambridge, MA, 1998. [13] S. Young. Large vocabulary continuous speech recognition. Signal Processing Magazine, IEEE, 13:45-57, 1996. [14] Victor W. Zue. The use of speech knowledge in automatic speech recognition. In Proceedings of the IEEE, volume 73, pages 1602-1615, Nov 1985. [15] R. P. Lippmann. Speech recognition by machines and humans. Speech Communication, 22:1-15, 1997. |
||||||
|