
| Research Abstracts Home | CSAIL Digital Archive | Research Activities | CSAIL Home |
![]()
|
Research
Abstracts - 2007
|
|
StreamIt: A Common Machine Language for Multicore ArchitecturesMichael I. Gordon, William Thies, Qiuyuan J. Li, Phil Sung, David Zhang, Weng Fai Wong & Saman AmarasingheIntroductionTo continue performance scalability and to manage design complexity, commodity processor architectures are now relying on multicore designs. These designs replicate processing elements to expose coarse-grained parallelism. For general purpose processors and graphics processors (GPUs), multicore designs are now standard and are quickly scaling in the number of cores. However, easing the programming burden for these explicitly parallel machines is still a largely unsolved problem. We are developing high-level programming idioms, compiler technologies, and runtime systems for multicore architectures. We seek to enable high programmer productivity coupled with high application performance, portability, and scalability. The algorithms we develop will be applicable across the spectrum of multicore architectures, from general purpose processors to emerging flexible graphics hardware. Unfortunately, parallel programming is notoriously difficult. Traditional programming models such as C, C++ and FORTRAN are ill-suited to multicore architectures because they assume a single instruction stream and a monolithic memory. The stream programming paradigm offers a promising high-level approach for application development targeting multicore architectures. Our research focuses on language, compiler, and runtime technologies for the StreamIt programming language [5], a streaming language we are developing in the Compilers Group at MIT (COMMIT). BackgroundThe common properties across multicore architectures are multiple flows of control and multiple local memories. StreamIt directly exposes these common properties. In the StreamIt language, a program is represented as a set of autonomous filters that communicate through FIFO data channels. During program execution, filters fire repeatedly in a periodic schedule. As each filter has a separate program counter and an independent address space, all dependences between filters are made explicit by the communication channels. Compilers or runtime systems can leverage this dependence information to orchestrate parallel execution.
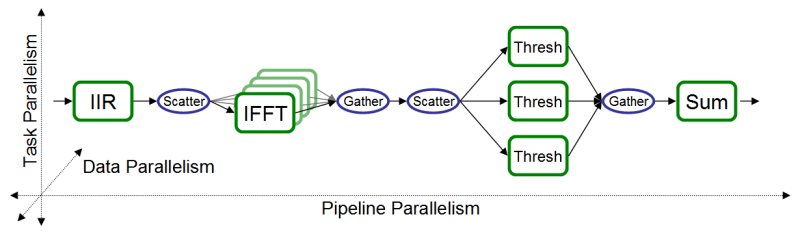
StreamIt directly exposes three types of coarse-grained parallelism: task, data, and pipeline. Conceptually, each type of parallelism can be expressed on an independent axis of a stream graph (see Figure 1). Task parallelism refers to groups of filters that are on different parallel branches of the original stream graph, as written by the programmer (e.g., three Thresh filters in Figure 1). That is, the output of each filter never reaches the input of the other. In stream programs, task parallelism reflects logical parallelism in the underlying algorithm. Data parallelism refers to any filter that has no dependences between one execution and the next. Such "stateless" filters offer unlimited data parallelism, as different instances of the filter can be spread across any number of computation units (e.g., IFFT in Figure 1). StreamIt, unlike many other streaming languages, naturally supports pipeline parallelism [1]. Pipeline parallelism applies to chains of producers and consumers that are directly connected in the stream graph (e.g., IIR and IFFT in Figure 1). Each type of parallelism has advantages and disadvantages. For example, exploiting data parallelism is straightforward and produces a load-balanced mapping. However, by itself, data parallelism requires global communication and synchronization. A stream-aware system can determine the correct granularity and combination of parallelism for high efficiency.
Compiler TechniquesIn our most recent work, we present automatic compiler techniques for bridging the gap between the granularity of a stream program and the underlying granularity of the target architecture [2]. We present a unified static approach that leverages the correct combination of task, data, and pipeline parallelism. To reduce the communication overhead typical of data parallelism, we first increase the granularity of the stream graph by fusing filters so long as the result is data-parallel. To further reduce communication costs, we data-parallelize the application while maintaining task parallelism being careful to load-balance each data-parallel stage. To parallelize filters with loop-carried dependencies, we employ software-pipelining techniques to execute filters from different iterations in parallel, increasing scheduling flexibility. Targeting the 16-core Raw Architecture [4], we achieve a mean speedup of 11.2x over a single core baseline; 7 out of 12 benchmarks speedup by over 12x. In comparison, a traditional data-parallel approach that does not attempt to match the granularity achieves a speedup of only 1.4x over the sequential baseline. Our research suggests that two specific features of StreamIt are a good match for multicore architectures: exposing producer-consumer relationships and exposing the outer loop around the entire stream graph. Current and Future WorkWe wish to demonstrate that, for the class of streaming applications, StreamIt programs are portable, scalable and efficient across multicore architectures. Toward this end, we are in the process of developing backends and runtime systems for emerging industry and research multicore architectures. Each separate architecture tests the portability of the language, generality of our current mapping algorithms, and reveals further opportunities for research. We are currently working on a compiler backend with an associated runtime system for the Cell processor [3]. This development effort is interesting for multiple reasons. For high-performance, Cell requires the exploitation of fine-grained data parallelism in the form of SIMD instructions. We have developed an infrastructure that will map a "copy" of a suitable stateless filter onto each SIMD lane. Furthermore, Cell is an example of a heterogeneous multicore architecture. We must extend our mapping algorithms to make informed mapping decisions given the differing capabilities of the processing cores. Finally, we are developing a system for Cell where we can vary the mapping and scheduling of the stream program between static (compiler) and dynamic (runtime) control. We wish to investigate points on the continuum between static and dynamic mappings, e.g., whether it is useful to compute the mapping and schedule at compile time. Data parallelism often requires global communication and data reorganization. Another question we seek to investigate is whether data parallelism scales indefinitely. We wish to determine the points at which data parallelism ceases to scale as we vary the architectural parameters (e.g., number and capability of processing elements, network parameters, memory bandwidth). When data parallelism no longer scales, what architectural, language, and compiler techniques will be necessary to continue performance scaling? Finally, we will demonstrate that StreamIt can effectively target GPUs. In parallel with the evolution of general purpose processors, graphics processors (GPUs) have evolved from the fixed pipeline allocations of the past to multicore designs. These designs replicate simple processing elements achieving massive coarse-grained data parallelism for specialized rendering data-types and operations. Coarse-grained data parallelism can be discovered in StreamIt and should be relatively easy to exploit. A more difficult task is to generate efficient code for the processing elements themselves, code that exploits the dense instruction encoding of the processing elements. As GPUs become more programmable and more tightly coupled with the CPU, one can think of the coupling as a heterogeneous multicore processor where segments of an application are offloaded to the GPU for processing. With StreamIt, one can write an application in a single high-level programming language and let the compiler or runtime decide the partitioning between CPU and GPU. We plan to extend our mapping algorithms for this problem. References:[1] Michael Gordon, William Thies, Michal Karczmarek, Jasper Lin, Ali S. Meli, Andrew A. Lamb, Chris Leger, Jeremy Wong, Henry Hoffmann, David Maze, and Saman Amarasinghe. A Stream Compiler for Communication-Exposed Architectures. In ASPLOS, 2002. [2] Michael Gordon, William Thies, and Saman Amarasinghe. Exploiting Coarse-Grained Task, Data, and Pipeline Parallelism in Stream Programs. In ASPLOS, 2006. [3] H. Peter Hofstee. Power Efficient Processor Architecture and The Cell Processor. In HPCA, 2005. [4] Michael Taylor, Walter Lee, Jason Miller, David Wentzlaff, et. al. Evaluation of the Raw Microprocessor: An Exposed-Wire-Delay Architecture for ILP and Streams. In ISCA, 2004. [5] William Thies, Michal Karczmarek, and Saman Amarasinghe. StreamIt: A Language for Streaming Applications. In Proc. of the International Conference of Compiler Construction, 2002. |
|||
|