|
Biologically Inspired Machine Learning
Michael H. Coen
Motivation
Animals routinely solve extremely difficult, nonparametric learning problems
during development. How do they do this? Can we formalize their learning
in a computational model? What insights would this model provide about
learning in both biological and computational systems? The goal of this
work is to develop biologically-inspired approaches to machine learning
and reciprocally, to use these approaches to better understand learning
in biological systems.
Approach
This work presents a new model of self-supervised machine learning.
It is inspired by the notion that the sensory information gathered by
animals is inherently redundant. This redundancy can enable learning without
requiring explicit teaching (as in supervised learning) or statistical
modeling (as in unsupervised learning). In Nature, these are frequently
unavailable and yet animals learn anyway. In other words, redundancy allows
animals to supervise their own learning, hence the designation of self-supervised
learning. It also enables a powerful computational framework to provide
this ability to machines.
Specifically, we present a new mathematical framework called cross-modal
clustering [2,4] for understanding learning in both animals and
machines based upon unsupervised interactions with the world. This approach
draws upon evidence gathered by the brain and cognitive sciences demonstrating
the extraordinary degree of interaction between sensory modalities during
the course of ordinary perception.
This work provides evidence these interactions are fundamental to solving
some of the difficult developmental learning problems faced by both animals
and artificial systems. It further demonstrates that a biologically-inspired
approach can help answer what are historically challenging computational
problems. These include, for example, how to cluster non-parametric data
corresponding to an unknown number of categories and how to learn motor
control through observation.
Results
We have applied this framework to problems in a wide variety of domains.
These include:
-
Separating unknown mixture distributions based on their co-occurrences
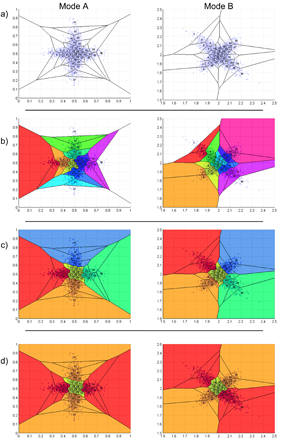
with other mixture distributions [2,4]. The figure below shows the
progression of the cross-modal clustering algorithm. (A)
shows the initial randomized Voronoi partitioning of mixture models
in two independent but co-occurring modalities. Our algorithm reconstructs
the actual distributions by combining Voronoi regions based on co-occurrence
information. Figures (B) and (C) show intermediate region formation.
(D) shows the correctly clustered outputs, with the confusion region
between the categories indicated by the yellow region in the center.
Notably, the algorithm is entirely non-parametric and knows neither
the number of clusters nor the distributions from which they are drawn.
-
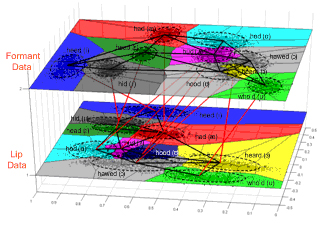
Learning the vowel structure of American English &ndash the number
of vowels and their formant structures &ndash simply by watching and
listening to someone speak [3]. This approach is entirely non-parametric
and has no a priori knowledge of the number of categories
(vowels) nor the distributions of their individual presentations;
it also has no prior linguistic knowledge. This work is the first
example of unsupervised phonetic acquisition of which we are aware,
outside of that done by human infants, who solve this problem easily.
We plan to extend this result to cover a complete set of phonemes
in English to develop a deeper understanding of protolanguage - the
poorly studied prelexical states through which infants pass as they
acquire word usage. In particular, we would like to construct a system
that babbles in English, using the framework provided in
(iii) below.
-
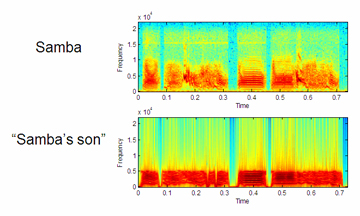
Acquiring sensorimotor control. We have constructed a system that
learns to sing like a real zebra finch looking for a mate, following
the developmental stages of a fledgling zebra finch [1]. It first
learns the song of an adult male corresponding to its "father" and
then listens to its own initially nascent attempts at mimicry through
an articulatory synthesizer. By recursively reapplying the cross-modal
clustering framework described in [2], the system demonstrates the
acquisition of sensorimotor control through what was initially a perceptual
framework. Spectrograms displaying the vocalizations of the real bird
used to train this system and the resulting learned output of its
artificial "son" are shown below. (The data for this experiment was
provided by Ofer Tchernichovski, CCNY.)
-
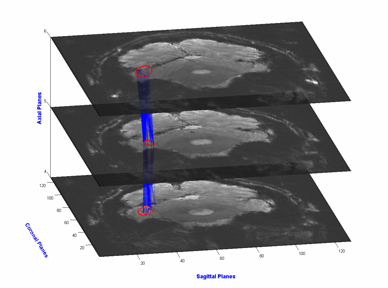
Unsupervised segmentation of human functional MRI (fMRI) data. The
cross-modal clustering framework offers a new way to identify functional
regions in the brain without knowing of their existence in advance.
This is an especially attractive approach to this problem, because
we lack any detailed functional models of modular brain structure.
Not having such models makes it difficult to apply standard machine
learning techniques to elucidate functional regions within the brain,
which are almost entirely unknown.
The figure below presents very recent results demonstrating the
automatic detection of the fusiform face area (FFA) via this approach,
which only uses fMRI data and not the actual experimental inputs describing
the images or their categories. (The data is this experiment was provided
by N. Kanwisher and L. Reddy, Department of Brain and Cognitive Sciences,
MIT, and C. Baker, NIH.)
Among our future research goals is the generation of a distributed,
geographic atlas of modular brain functions, using self-supervised
learning techniques. We are currently locating other functional areas
within human brains, such as the parahippocampal place area (PPA).
We are also clustering fMRI data from rats looking for similar functional
regions. Most importantly, this work demonstrates that a biologically-inspired
theory of machine learning can symbiotically help us understand the
very systems providing its inspiration.
Support
This work has been funded through the AFOSR under contract #F49610-03-1-0213
and through the AFRL under contract #FA8750-05-2-0274.
References:
[1] Michael Coen. Learning to sing like a bird: An architecture for self-supervised
sensorimotor learning. In submission. 2007.
[2] Michael Coen. Multimodal Dynamics: Self-Supervised Learning in Perceptual
and Motor Systems. Ph.D. Dissertation. Massachusetts Institute of Technology.
2006.
[3] Michael Coen. Self-Supervised Acquisition of Vowels in American English.
In Proceedings of the Twentieth National Conference on Artificial
Intelligence (AAAI'06). Boston, MA. 2006.
[4] Michael Coen. Cross-Modal Clustering. In Proceedings of the Twentieth
National Conference on Artificial Intelligence(AAAI'05),
pp. 932-937. Pittsburgh, PA. 2005.
|
|
