
| Research Abstracts Home | CSAIL Digital Archive | Research Activities | CSAIL Home |
![]()
|
Research
Abstracts - 2007
|
|
Inference and Learning in Bayesian Logic (BLOG)Brian Milch & Leslie Pack KaelblingThe ProblemIntelligent agents must be able to make inferences about the real-world objects that underlie their observations -- for instance, the physical objects that correspond to pixels in an image, or the people, places, and things referred to by phrases in a text document. Figure 1 illustrates a particular instance of this problem, faced by automatic citation indexing systems such as Citeseer and Google Scholar. Given a set of citation strings -- in a wide range of formats, and often containing errors -- the system must determine the set of distinct publications and authors that are mentioned, and reconstruct the correct publication titles and author names. An important difficulty in such tasks is that the set of objects to be reasoned about (publications, authors, etc.) is not known in advance. Thus the standard formalisms for probabilistic reasoning, which are graphical models with fixed sets of variables and a fixed dependency structure, are no longer appropriate. 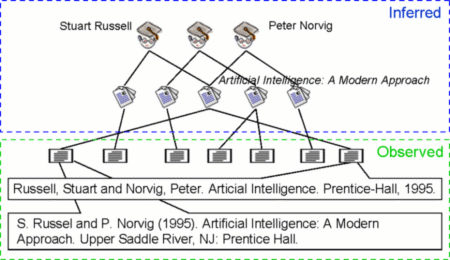
Figure 1. Observed and inferred information in a bibliographic indexing system. ApproachWe have developed a new representation language, called Bayesian logic or BLOG, that defines probability distributions over possible worlds with varying sets of objects [1]. A BLOG model for the bibliographic domain is shown in Figure 2. The model describes a hypothetical process by which researchers, publications, and citations are created: first some number of researchers are created, and their names are generated according to a specified probability distribution; then some number of publications are created, and their authors and titles are chosen; and finally, for each of the known citation strings, the publication being cited is chosen and the text is generated according to a formatting distribution. The text of a citation depends on the title and author names of the publication it refers to -- thus, the dependencies between the random variables depend on unobserved relations between the objects. Given some observed citations, the system must invert this model to make inferences about the underlying researchers and publications. 
Figure 2. A BLOG model for the citation indexing domain. ResultsWe have proven that a large class of "structurally well-defined" BLOG models are guaranteed to define unique probability distributions over possible worlds [1, 2]. We have also defined a sampling-based inference algorithm that converges to the correct posterior probability for any query on a structurally well-defined BLOG model [2]. This fully general algorithm is too slow for many practical tasks. However, we have also developed an inference framework based on Markov chain Monte Carlo (MCMC), where we execute a random walk over possible worlds in such a way that over the long run, the fraction of time spent in each possible world converges to its posterior probability [3]. This MCMC framework allows users to plug in domain-specific proposal distributions, which help the random walk to move efficiently between high-probability worlds. Using this framework, we can infer the set of publications underlying a set of citation strings with about 80-95% accuracy (depending on the data set). The run time is quite manageable: about 100 seconds for a set of a few hundred citations [3]. Current Work on InferenceAlthough our MCMC algorithm converges quickly when provided with a domain-specific proposal distribution, developing such distributions from scratch is a time-consuming task. We are currently working to reduce this burden by allowing the user to implement just small pieces of the proposal distribution, mostly operating on single variables. The system will then invoke these pieces when necessary. We are also investigating other approaches to inference, including "lifted" algorithms that operate on whole groups of variables at once; algorithms applying recent techniques for solving weighted satisfiability problems; and best-first search algorithms. Current Work on LearningIn the BLOG models we have used so far, the structure of the model is specified by hand, and the parameters of individual probability distributions -- such as the prior distributions for author names and paper titles -- are learned from separate data sets. We we would like to have algorithms that can learn the structure of BLOG models: that is, a relational specification of which variables depend on which other variables. We are looking into probabilistic extensions of inductive logic programming, which so far has involved learning deterministic dependencies among logical formulas. Moving even further in this direction, we are investigating how to get a system to automatically invent new relations and types of objects -- for instance, hypothesizing a "coauthor" relation to explain co-occurrence patterns in author lists, or inventing "conference" objects to explain recurring strings that come after paper titles in citations. Research SupportThis work is supported by the Defense Advanced Research Projects Agency (DARPA), through the Department of the Interior, NBC, Acquisition Services Division, under Contract No. NBCHD030010. References:[1] Brian Milch, Bhaskara Marthi, Stuart Russell, David Sontag, Andrey Kolobov and Daniel L. Long. "BLOG: Probabilistic Models with Unknown Objects". In Proc. 19th International Joint Conference on Artificial Intelligence (IJCAI), pp. 1352-1359, Edinburgh, UK, August 2005. [2] Brian Milch, Bhaskara Marthi, David Sontag, Stuart Russell, Andrey Kolobov and Daniel L. Ong. "Approximate Inference for Infinite Contingent Bayesian Networks". In 10th International Workshop on Artificial Intelligence and Statistics (AISTATS), Hastings, Barbados, January 2005. [2] Brian Milch and Stuart Russell. "General-Purpose MCMC Inference over Relational Structures". In Proc. 22nd Conference on Uncertainty in Artificial Intelligence (UAI), pp. 349-358, Cambridge, MA, USA, July 2006. |
|||
|