| Research Abstracts Home | CSAIL Digital Archive | Research Activities | CSAIL Home |
![]()
|
Research
Abstracts - 2007
|
|
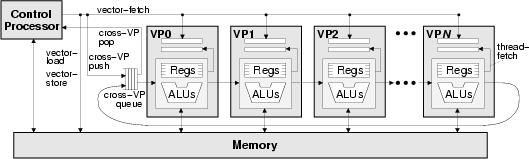
The Vector-Thread ArchitectureRonny Krashinsky, Christopher Batten & Krste AsanovicMotivationAs embedded computing applications become more sophisticated, there is a growing demand for high-performance, low-power information processing. Custom circuits always provide the optimal solution for a given processing task, but rising mask and development costs limit application-specific chips to devices that will be sold in very high volumes. Even then, hardwired circuits cannot be used if a design must rapidly adapt to changing requirements. As a more flexible alternative, programmable domain-specific processors have evolved to exploit particular forms of parallelism common to certain classes of embedded applications. Examples include digital signal processors (DSPs), media processors, network processors, and field-programmable gate arrays (FPGAs). Full systems however, often require a heterogeneous mix of these cores to be competitive on complex workloads with a variety of processing tasks. The resulting devices have multiple instruction sets with different parallel execution and synchronization models, making them difficult to program. They are also inefficient when the application workload causes load imbalance across the heterogeneous cores. Ideally, a single ``all-purpose'' programmable architecture would efficiently exploit the different types of parallelism and locality present in embedded applications. Although ``general-purpose'' processors are very flexible, they are often too large, too slow, or burn too much power for embedded computing. In particular, modern superscalars expend considerable hardware resources to dynamically extract limited parallelism from sequential encodings of unstructured applications. The goal for an all-purpose processor is very different. Embedded applications often contain abundant structured parallelism, where dependencies can be determined statically. The challenge is to develop an instruction set architecture that flexibly encodes parallel dependency graphs and to improve the performance-efficiency of processor implementations. The VT Architectural ParadigmThe vector-thread (VT) architectural paradigm [1,2] describes a class of architectures that unify the vector and multithreaded execution models. VT architectures compactly encode large amounts of structured parallelism in a form that allows simple microarchitectures to attain high performance at low power by avoiding complex control and datapath structures and by reducing activity on long wires. VT Abstract ModelThe programming model for a vector-thread architecture is a hybrid of the vector and multithreaded models. A conventional control processor interacts with a virtual processor vector (VPV), as shown in Figure 1. A virtual processor contains a set of registers and has the ability to execute groups of RISC-like instructions packaged into atomic instruction blocks (AIBs). There is no automatic program counter or implicit instruction fetch mechanism for VPs; all instruction blocks must be explicitly requested by either the control processor or the VP itself.
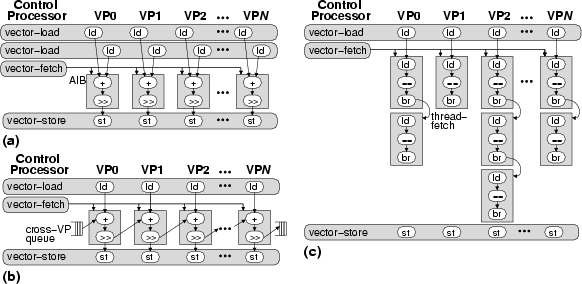
Applications can be mapped to VT in a variety of ways but it is especially well suited to executing loops; each VP executes a single iteration of the loop and the control processor stripmines the execution and factors out common bookkeeping overhead. To execute data-parallel code, the control processor uses vector-fetch commands to broadcast AIBs to all the VPs (Figure 2a). The control processor can also use vector-load and vector-store commands to efficiently move vectors of data between memory and the VP registers. To allow loop-carried dependencies to be efficiently mapped to VT, VPs are connected in a unidirectional ring topology and pairs of sending and receiving instructions can transfer data directly between VPs (Figure 2b). In contrast to software pipelining on VLIW architectures, the compiler or programmer need only schedule code for one loop iteration mapped to one VP, and the cross-VP data transfers are dynamically scheduled to resolve when the data becomes available.
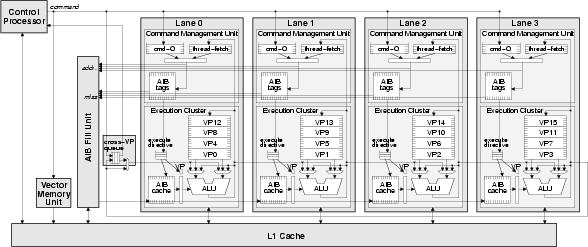
To execute loop iterations with conditionals or even inner-loops, each VP directs its own control flow using thread-fetches to fetch its AIBs (Figure 2c). The ability to freely intermingle vector-fetches and thread-fetches allows a VT architecture to combine the best attributes of the vector and multithreaded execution paradigms. The control processor can issue a vector-fetch command to launch a vector of VP threads, each of which continues to execute as long as it issues thread-fetches. Thread-fetches break the rigid control flow of traditional vector machines, allowing the VPs to follow independent control paths. By allowing VPs to conditionally branch, VT provides more efficient execution of large conditionals compared to traditional vector masking. Thread-fetches also allow outer-loop parallelism to map naturally to VT, as VPs can execute inner-loop iterations which have little or no available parallelism. Apart from executing loop iterations, the VPs can also be used as free-running threads where they operate independently from the control processor and retrieve tasks from a shared work queue. VT Physical ModelA VT machine contains a conventional control processor together with a vector-thread unit (VTU) that executes the VP code (Figure 3). To exploit the parallelism exposed by the VT abstract model, the VTU contains a parallel array of processing lanes. Each lane contains physical registers, which hold the state of VPs mapped to the lane, and functional units, which are time-multiplexed across the VPs.
In contrast to traditional vector machines, the lanes in a VT machine execute decoupled from each other, and each lane has a small AIB cache. A lane's command management unit (CMU) buffers commands from the control processor in a queue (cmd-Q) and holds pending thread-fetch addresses for the lane's VPs. The CMU chooses a vector-fetch or thread-fetch command to process, and looks up its address in the AIB cache tags. After an AIB cache hit or after a miss refill has been processed, the CMU generates an execute directive which contains an index into the AIB cache. For a vector-fetch command, the execute directive indicates that the AIB should be executed by all VPs, while for a thread-fetch command it identifies a single VP to execute the AIB. Execute directives are sent to a queue, and the CMU is able to overlap the AIB cache refill for new fetch commands with the execution of previous ones. To process an execute directive, the execution cluster reads VP instructions one by one from the AIB cache and executes them for the appropriate VP. When processing an execute-directive from a vector-fetch command, all of the instructions in the AIB are executed for one VP before moving on to the next. The Scale VT ProcessorThe Scale architecture, an instantiation of the VT paradigm, aims to provide high performance at low power for a wide range of embedded applications while using only a small area. To optimize area and energy, Scale partitions lanes (and VPs) into multiple execution clusters which each contain only a subset of all possible functional units and a small register file with few ports. The atomic execution of AIBs allows Scale to expose shared temporary state that is only valid within an AIB---chain registers at each ALU input reduce register file energy, and shared VP registers reduce the register file size needed to support a large number of VPs. Each cluster has independent control, and inter-cluster register dependencies are statically partitioned into transport and writeback micro-ops enabling decoupled cluster execution. Additionally, the memory access cluster uses load-data and store-address queues to enable access/execute decoupling. Decoupling allows each in-order cluster to be executing code for different VPs on the same cycle, providing a very cheap form of simultaneous multithreading to hide large functional unit or memory latencies. The Scale memory system uses cache refill/access decoupling [3] to pre-execute vector-loads and issue any needed cache line refills ahead of regular execution. Additionally, Scale provides segment vector loads and stores which efficiently pack and unpack multi-field records into VP registers. These mechanisms allow Scale to use a conventional cache to amplify memory bandwidth and tolerate long memory latencies, and avoid complicating the software interface with a hierarchical vector (or stream) register file. To evaluate the performance and flexibility of Scale, we have mapped a diverse selection of embedded benchmarks---including examples from image processing,audio processing, cryptography, and network processing---from EEMBC and other suites. Overall, the results show that Scale can flexibly provide competitive performance on a wide range of codes from different domains.
We have implemented the Scale design in silicon to prove the plausibility of the vector-thread architecture; to demonstrate the performance, power, and area efficiency of the design; and to provide a platform for future research on software for the architecture. The Scale chip includes a scalar RISC control processor, a four-lane vector-thread unit with 16 decoupled execution clusters together with instruction fetch, load/store, and command management units; a vector-memory access unit with support for unit-stride, strided, and segment loads and stores; and a four-port, non-blocking, 32-way set-associative, 32 KB cache. The VTU supports up to 128 simultaneously active virtual processor threads. We built the Scale chip in 0.18μm technology using standard cells and generated RAM blocks. Figure 4 shows a plot of the final chip layout. We recently received chips back from fabrication, and initial testing has verified correct functionality. Advantages of VTVT draws from earlier vector architectures and like vector microprocessors the Scale VT implementation provides high throughput at low complexity. Vector-fetch commands issue many parallel instructions simultaneously, while vector-load and vector-store commands encode data locality and enable optimized memory access. A vector-fetch broadcasts an AIB address to all lanes which each perform only a single tag-check. Instructions within the AIB are then read using a short index into the small AIB cache, and the vector-fetch ensures an AIB will be reused by each VP in a lane before any eviction is possible. Vector-memory commands improve performance and save memory system energy by avoiding the additional arbitration, tag-checks, and bank conflicts that would occur if each VP requested elements individually. In executing loops with cross-iteration dependencies, VT has many advantages over VLIW architectures. Loop iterations map to VPs on parallel lanes, and the dynamic hardware scheduling of explicit cross-VP data transfers allows execution to automatically adapt to the software critical path. Furthermore, within a lane, Scale's cluster decoupling allows execution to dynamically adjust to functional unit and memory latencies. These features alleviate the need for loop unrolling, software pipelining, and static scheduling, enabling more portable and compact code. VT provides extremely fine-grain multithreading with very low overhead; a single vector-fetch command can launch 100 threads which each execute 10 instructions. This granularity allows VT to parallelize code more effectively than conventional simultaneous multithreading (SMT) and chip multiprocessor (CMP) architectures. VT factors out bookkeeping code to the control thread, and vector-fetch and vector-memory commands efficiently distribute instructions and data to the VP threads. Additionally, vector-fetches and the cross-VP network provide low-overhead fine-grain synchronization, and a shared first-level cache enables low-overhead memory coherence. VT seamlessly combines vector and threaded execution. In comparison to polymorphic architectures which must explicitly switch modes, Scale can exploit fine-grain data, thread, and instruction-level parallelism simultaneously. Although some architectures can extract fine-grain parallelism from a wider range of loops, VT handles many common parallel loop types efficiently. In comparison to exposed architectures, VT provides a high-level virtual processor abstraction which allows parallelism to be encoded without exposing machine details such as the number of physical registers and processing units. Research SupportThis work was funded in part by DARPA PAC/C award F30602-00-2-0562, NSF CAREER award CCR-0093354, an NSF graduate fellowship, the Cambridge-MIT Institute, donations from Infineon Corporation, and an equipment donation from Intel Corporation. References[1] Ronny Krashinsky, Christopher Batten, Mark Hampton, Steve Gerding, Brian Pharris, Jared Casper, and Krste Asanovic. The Vector-Thread Architecture. In 31st International Symposium on Computer Architecture, Munich, Germany, June 2004. [ PDF ] [2] Ronny Krashinsky, Christopher Batten, Mark Hampton, Steve Gerding, Brian Pharris, Jared Casper, and Krste Asanovic. The Vector-Thread Architecture. In IEEE Micro Special Issue: Micro's Top Picks from Computer Architecture Conferences, Vol. 24, No. 6, November/December 2004. [ PDF ] [3] Christopher Batten, Ronny Krashinsky, Steve Gerding, and Krste Asanovic. Cache Refill/Access Decoupling for Vector Machines. In 37th International Symposium on Microarchitecture, Portland, OR, December 2004. [ PDF ] |
|||||||
|