
| Research Abstracts Home | CSAIL Digital Archive | Research Activities | CSAIL Home |
![]()
|
Research
Abstracts - 2007
|
|
Object Category Recognition Using Probabilistic Fusion of Speech and Image ClassifiersKate Saenko & Trevor DarrellIntroductionMultimodal recognition of object categories in situated environments is useful for robotic systems and other applications. Information about object identity can be conveyed in both speech and image. For example, if the user points at an object and says: ``This is my pen,'' the robot should be able to recognize the object as belonging to the class ``pen'', and not ``pan''. Conventional approaches to object recognition rely either on visual input or on speech input alone, and therefore are brittle in noisy conditions. Humans use multiple modalities for scene understanding, and artificial systems should be able to do the same. The conventional approach to image-based category recognition is to train a classifier for each category offline, using labeled images. Note that category-level recognition allows the system to recognize a class of objects, not just single instances. To date, image-based category recognition has only reached a fraction of human performance, especially in terms of the variety of recognized categories, which is partly due to lack of labeled data. Accurate and efficient off-the-shelf recognizers are only available for a handful of objects, such as faces and cars. In the assistant robot scenario, the user would have to collect and manually annotate a database of sample images to enable the robot to accurately recognize a variety of everyday objects. The speech-only approach is to rely on speech recognition results to
interpret the categories being referred to by the user. This approach
can be used to have the user ``train'' the robot through speech and gesture
to provide it with labeled images of objects. This is described in [1],
where the user points at objects and describes them using natural dialogue,
enabling the system to automatically extract sample images of specific
objects and to bind them to recognized words. However, this system uses
speech-only object category recognition, i.e. it uses the output of a
speech recognizer to determine object-referring words, and then maps them
directly to object categories. It does not use any prior knowledge of
object category appearance. Thus, if the spoken description is misrecognized,
there is no way to recover, and an incorrect object label may be assigned
to the input image (e.g., ``pan'' instead of ``pen''.) Also, the robot
only knows about object We propose a new approach, which combines speech and visual object category recognition. Rather than rely completely on one modality, which can be error-prone, we propose to use both speech- and image-based classifiers to help determine the category of the object. The intuition behind this approach is that, when the categories are acoustically ambiguous due to noise, or highly confusable (e.g., ``budda'' and ``gouda''), their visual characteristics may be distinct enough to allow an image-based classifier to correct the speech recognition errors. Even if the visual classifier is not accurate enough to choose the correct category from the set of all possible categories, it may be good enough to choose between a few acoustically similar categories. The same intuition applies in the other direction, with speech disambiguating confusable visual categories. For example, the Figure 1 below shows the categories that the visual classifier confused most often in our experiments. There are many cases in the human-computer interaction literature where multimodal fusion helps recognition (e.g. [2], [3]). Although visual object \emph{category} recognition is a well-studied problem, to the best of our knowledge, it has not been combined with speech-based category recognition. In the experimental section, we use real images, as well as speech waveforms from users describing objects depicted in those images, to see whether there is complementary information in the two channels. We propose a fusion algorithm based on probabilistic fusion of the speech and image classifier outputs. We show that it is feasible, using state-of-the-art recognition methods, to benefit from fusion on this task. The current implementation is limited to recognizing about one hundred objects, a limitation due to the number of categories in the labeled image database. In the future, we will explore extensions to allow arbitrary vocabularies and numbers of object categories. ApproachIn this section, we describe an algorithm for speech and image-based recognition of object categories. We assume a fixed set of C categories, and a set W of nouns (or compound nouns), where W_k corresponds to the name of the kth object category, where k=1,...,C. The inputs to the algorithm consist of a visual observation x_1, derived from the image containing the object of category k, and the acoustic observation x_2, derived from the speech waveform corresponding to W_k. In this paper, we assume that the user always uses the same name for an object category (e.g., ``car'' and not ``automobile''.) Future work will address an extension to multiple object names. A simple extension would involve mapping each category to a list of synonyms using a dictionary or an ontology such as WordNet. The disambiguation algorithm consists of decision-level fusion of the outputs of the visual and speech category classifiers. In this work, the speech classifier is a general-purpose recognizer, but its vocabulary is limited to the set of phrases defined by W. Decision-level fusion means that, rather than fusing information at the observation level and training a new classifier on the fused features x = {x_1, x_2}, the observations are kept separate and the decision of the visual-only classifier, f_1(x_1), is fused with the decision of the speech-only classifier, f_2(x_2). In general, decisions can be in the form of the class label k, posterior probabilities p(c=k|x_i), or a ranked list of the top N hypotheses. There are several methods for fusing multiple classifiers at the decision level, such as letting the classifiers vote on the best class. We propose to use the probabilistic method of combining the posterior class probabilities output by each classifier. We investigate two combination rules. The first one, the weighted mean rule, is specified as a sum of p(c|x_i) * lambda_i, i=1,...,m, where m is the number of modalities, and the weights lambda_i sum to 1 and indicate the ``reliability'' of each modality. This rule can be thought of as a mixture of experts. The second rule is the weighted version of the product rule or the product p(c|x_i)^lambda_i, which assumes that the observations are independent given the class, which is a valid assumption in our case. The weights are estimated experimentally by enumerating a range of values and choosing the one that gives the best performance on a held-out dataset. Using one of the above combination rules, we compute new probabilities for all categories, and pick the one with the maximum score as the final category output by the classifier. Note that our visual classifier is a multi-class SVM, which returns margin scores rather than probabilities. To obtain posterior probabilities p(c=k|x_2) from decision values, a logistic function is trained using cross-validation on the training set. Further details can be found in [4]. ExperimentsThe goal of the following experiments is to use real images and speech from users describing objects depicted in those images to see whether there is complementary information in the two channels. If so, then fusing the classifiers should give us better recognition performance than using either one in isolation. We are not aware of any publicly available databases that contain paired images and spoken descriptions. For these experiments, we used a subset of a standard image-only object category database, and augmented the images with speech by asking subjects to view each image and speak the name of the object category. We evaluate the proposed fusion algorithm and compare the mean and the product rules. Most publicly available image databases suitable for category-level recognition contain either cars or faces, and very few other object categories. We chose to use the Caltech101 database [7], because it contains a large variety of categories, and because it is a standard benchmark in the object recognition field. The database has a total of 101 categories, with about about 50 images per category. Although the categories are challenging, the task is made somewhat easier by the fact that most images have little or no clutter, and the objects tend to be centered in each image, presented in a stereotypical pose. To train the image-based classifier, we use a standard training set, consisting of the first 15 images from each category. We also select a test set consisting of the next 12 images from each category, for a total of 1212 test samples. Each image in the test set was paired with a waveform of a subject speaking the name W_k of the corresponding category. All experiments were done averaging the performance over 20 trials of randomly selecting subsets of 50% of the test data. We chose the set W based on the words provided with the image database, changing a few of the names to more familiar words. For example, instead of ``gerenuk'' we used the word ``gazelle''. Six subjects participated in the data collection, four male and two female, all native speakers of American English. Each subject was presented with 2 images from each category in the image test set, and asked to say the object name, resulting in 12 utterances for each category. The images were shown, as opposed to just prompting the subject with the text string, because some names have ambiguous spellings (e.g., the spelling ``bass'' refers to the fish, not the musial instrument), and also to make the experience more natural. Our goal is to simulate the scenario where the user speaks the name of the object and points to it, with the robot interpreting the gesture and thus obtaining an image of the object. The speech data collection took place in a quiet office, on a laptop computer, using its built-in microphone. The nature of the category names in the Caltech101 database, the controlled environment, and the small vocabulary makes this an easy speech recognition task. In realistic human-robot interaction scenarios, the environment can be noisy, interfering with speech recognition. Also, the category names for everyday objects are more common words (e.g. ``pen'' or ``pan'' instead of ``trilobyte'' or ``mandolin'') and the their vocabulary is much larger, resulting in more acoustic confusion. To simulate a more realistic speech task, we added ``cocktail party'' noise to the original waveforms, using increasingly lower signal-to-noise ratios: 10db, 4db, 0db, and -4db. For these expriments, we used the Nuance speech recognizer, a commercial, state-of-the-art, large-vocabulary speech recognizer. The recognizer returns an N-best list, i.e. a list of N most likely hypotheses k=k_1,...,k_N, sorted by their confidence score. We use normalized confidence scores as an estimate of the posterior probability p(c=k|x_1) in the combination rule. For values of k not in the N-best list, we set the probability to 0. The size of the N-best was set to 101, however, due to pruning, most lists were much shorter. The total 1-best accuracy on the entire test set obtained by the recognizer in the clean audio condition was 91.5%. The accuracy is measured as the percentage of waveforms assigned the correct category label. The N-best accuracy, i.e. the accuracy that would be obtained if we could choose the best hypothesis by hand from the N-best list, was 99.2% for clean audio. We use the method of [5] for image-based category classification. The algorithm first extracts a set of interest points from the image, and then performs vector quantization on the feature space [6]. Classification is done with a multi-class support vector machine (SVM) using the pyramid match kernel [5]. The implementation uses an all-vs-one SVM, with a total of C classifiers, each of which outputs posterior probabilities of each class given the test image. The classification accuracy obtained on the entire test set by the image-based classifier, measured as the percentage of correctly labeled images, was 50.7%. The results of the fusion experiments show that the weighted combination rule is better than not having weights (i.e. setting each weight to 0.5). The optimal weight can be estimated automatically based on a held-out dataset not used in testing. Our results show that, for any noise condition, setting the speech model weight to 0.8 seems like the best choice, even when the speech modality performance is much worse than visual performance. The absolute gains in classification accuracy at that weight for each noise condition are plotted in the figure below. The mean rule does slightly better than the product rule on a number of noise conditions. Overall, combined speech and image-based categorization outperforms single-modality categorization for all noise conditions. 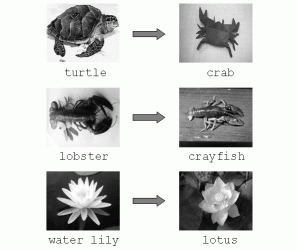
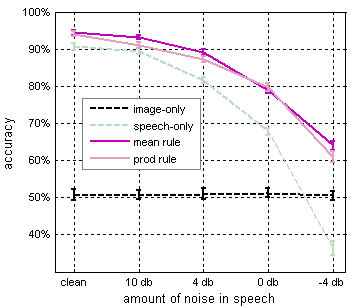 Figure 1: confusable visual categories. Figure 2: Absolute improvement using
fusion.
Figure 1: confusable visual categories. Figure 2: Absolute improvement using
fusion.
References:[1] A. Haasch, N. Hofemann, J. Fritsch, and G. Sagerer: A multi-modal object attention system for a mobile robot, In Intelligent Robots and Systems, 2005. [2] G. Potamianos, C. Neti, G. Gravier, A. Garg, and A. Senior. Recent Advances in the Automatic Recognition of Audio-Visual Speech, in Proc. IEEE, 2003. [3] E. Kaiser, Olwal, A., McGee, D., Benko, H., Corradini, A., Li, X., Cohen, P., and Feiner, S. Mutual disambiguation of 3D multimodal interaction in augmented and virtual reality. In Proceedings of the 5th International Conference on Multimodal Interfaces (ICMI), 2003. [4] C. Chang and C. Lin. LIBSVM : a library for support
vector machines, 2001. [5] K. Grauman and T. Darrell. The Pyramid Match
Kernel: Discriminative Classification with Sets of Image Features. In
Proceedings of the IEEE International Conference on Computer Vision
(ICCV), Beijing, China, October 2005. [6] K. Grauman and T. Darrell. Approximate Correspondences in High Dimensions. In Proceedings of Advances in Neural Information Processing Systems (NIPS), 2006. [7] L. Fei-Fei, R. Fergus and P. Perona. Learning generative visual models from few training examples: an incremental Bayesian approach tested on 101 object categories. In IEEE. CVPR, Workshop on Generative-Model Based Vision, 2004. |
|||
|