| Research Abstracts Home | CSAIL Digital Archive | Research Activities | CSAIL Home |
![]()
|
Research
Abstracts - 2007
|
|
Dynamic Dependency Tests for Audio-Visual Speaker AssociationMichael R. Siracusa & John W. Fisher IIIProblemGiven a single audio recording of the scene and a separate video stream (or more commonly a region of a single video) for each individual in the scene, we wish to determine who, if anyone, is speaking at each point in time. The solution to this problem has wide applicability to tasks such as automatic meeting transcription, social interaction analysis, and control of human-computer dialog systems. Figure 1 shows a single video frame from a typical meeting scenario.
ApproachWe view audio-visual speaker association as a particular example from a general class of problems we call dynamic dependency tests. A dynamic dependency test answers the following question: given multiple data streams, how does their interaction evolve over time? Here, interaction is defined in terms of changing graphical structures, i.e., the presence or absence of edges in a graphical model. In the audio-visual speaker association problem each possible dependency structure has a simple semantic interpretation. Specifically, when video stream k and the audio stream are dependent we say "person k is speaking" and when all streams are independent we assume "the speaker is off camera or no one is speaking." We cast a dynamic dependency test as a problem of inference on a special class of probabilistic models in which a latent state variable indexes a discrete set of possible dependency structures on measurements. We refer to this class of models as dynamic dependence models and introduce a specific implementation via a hidden factorization Markov model (HFactMM). This model allows us to take advantage of both structural and parametric changes associated with changes in speaker. This is in contrast with standard sliding window based dependence analysis [1,2,3,4]. Such techniques process data using a sliding window over time assuming a single audio source within that window. As such, they do not take advantage of the past or future to learn a audio-visual appearance model of the potential audio sources. Our method can take advantage of the voice and potential user pose and appearance changes associated with changes in speaker.
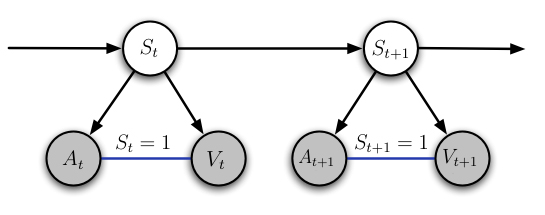
Figure 2 shows an HFactMM designed for audio-visual speaker detection of a single person/video source. In this simple model the hidden state is binary random variable. When the state is 1 the audio and video observations are dependent indicating the person associated with the video is speaking. Conversely, the audio and video are independent when the state is 0, indicating the person is not the audio source. Given a stream of audio and video observations, our goal is to infer the hidden state. We consider situations in which the model parameters are not known a priori. This necessitates both a learning and inference step. The Baum-Welch/EM algorithm can be used with a slight modification for learning the parameters of an HFactMM, subsequently Viterbi decoding can be used for exact inference. Note that we assume no training data and perform learning and inference on the data being analyzed. ProgressWe have achieved state-of-the-art performance on the standard audio-visual CUAVE[6] dataset. This is achieved without any window parameters to set, without a silence detector or lip tracker and without any labeled training data [7]. The CUAVE groups dataset consists of multiple videos of two individuals taking turns speaking digit strings. We achieve 88% accuracy in detecting who is speaking (chance performance is 33%). See [7] for more details. Future work will continue to evaluate our approach on larger audio-visual datasets and focus on developing simple, tractable and efficient algorithms and models for the general class of dynamic dependency test. References:[1] J. Hershey and J. Movellan, Audio-vision: Using audio-visual synchrony to locate sounds. In NIPS, 1999. [2] M. Slaney and M. Covell, Facesync: A linear operator for measuring synchronization of video facial images and audio tracks," in NIPS 2000. [3] J.W. Fisher III, T. Darrell, W.T. Freeman, and P.A. Viola, Learning joint statistical models for audio-visual fusion and segregation. In NIPS 2000, pp. 772-778. [4] J.W. Fisher III and T. Darrell. Speaker association with signal-level audiovisual fusion. In IEEE Transactions on Multimedia, 6 (3):406-413, Jun 2004. [5] B. Milch, B. Marthi, D. Sontag, S. Russell, D.L. Ong, and A. Kolobov, Approximate inference for infinite contingent bayesian networks. In AIStats, 2005. [6] E.K. Patterson, S. Gurbuz, Z. Tufecki, and J.N. Gowdy, CUAVE: A new audio-visual database for multimodal human-computer interface research. In Tech. Rep. Department of ECE, Clemson University, 2001. [7] M.R. Siracusa and J.W. Fisher III, Dynamic Dependency Tests: Analysis and Applications to Multi-modal Data Association. In AIStats 2007. |
|||
|