| Research Abstracts Home | CSAIL Digital Archive | Research Activities | CSAIL Home |
![]()
|
Research
Abstracts - 2007
|
|
Predicting Partial Paths from Planning Problem ParametersSarah Finney, Tomas Lozano-Perez & Leslie Pack KaelblingIntroductionModern sample-based single-query robot-motion planners are highly effective in a wide variety of planning tasks. When they do encounter difficulty, it is usually because the path must go through a part of the configuration space that is constricted, or otherwise hard to sample [1]. One set of strategies for solving this problem is to approach it generically, and to develop general methods for seeking and sampling in constricted parts of the space. Because these planning problems are ultimately intractable in the worst case, the completely general strategy cannot be made efficient. However, it may be that a rich set of classes of more specific cases can be solved efficiently by learning from experience.
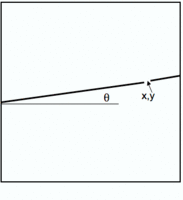
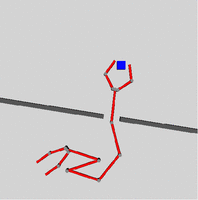
The basic question addressed by our current research is whether it is possible to learn a function that maps directly from parameters describing an arrangement of obstacles in the workspace, to some information about the configuration space that can be used effectively by a sample-based planner. Our approach is based on task templates, which are parametric descriptions (in the workspace) of the robot's planning problem. Task templates can be used to describe broad classes of situations. Examples include: moving (all or part of) the robot through an opening and grasping something; moving through a door carrying a large object; arriving at a pre-grasp configuration with fingers "straddling" an object. The figure to the right shows a simple task template for a door Given such task templates, the goal is to learn a function that, given a new planning problem, described as an instance of the template, generates a small set of suggested partial paths in the constricted part of the configuration space. These suggested partial paths can then be used to "seed" a sample-based planner, giving it guidance about paths that are likely to be successful. At first glance, this seems like a relatively straightforward non-linear regression problem, learning from function f from an m-dimensional vector x (an instantiated task template) to a vector y which represents a path segment, so that the average distance between the actual output and the predicted output is minimized. However, although it would be useful to learn a single-valued function that generates on predicted y vector given an input x, our source of data does not necessarily have that form.
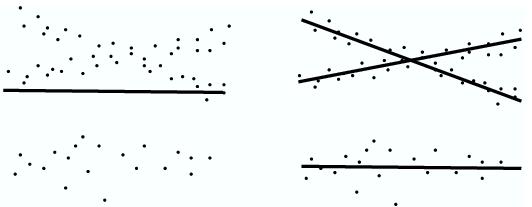
For instance, consider a mobile robot going around an obstacle. It could choose either to go around to the left of the obstacle, or to the right of it. In calling a probabilistic planner to solve such problems, there is no general way to bias it toward one solution or the other; and in some problems there may be many such solutions. If we simply took the partial paths from all of these plans and tried to solve for a single regression function f from x to y, it would have the effect of "averaging" the outputs, and potentially end up suggesting partial paths that go through the obstacle. To handle this problem, we have to construct a more sophisticated regression model, in which we assume that data are actually drawn from a mixture of regression functions, representing qualitatively different "strategies" for negotiating the environment. We learn a generative model for the selection of strategies and for the regression function given the strategy, in the form of a probabilistic mixture of regression models: where the x's are the task template parameters, the y's are vectors corresponding to path segments, and k ranges over the various strategies. Once we have trained our model and we are presented with a new planning problem, we can use our estimate for Pr(s=k|x) to determine which strategy or strategies would be best for this particular problem, and then generate a suggested path segment according to each applicable strategy using the maximum likelihood y according to Pr(y|x,s=k). Our model, and the EM algorithm used to estimate its parameters, is essentially identical to one used for clustering trajectories in video streams [2], though their objective is primarily clustering, where ours is primarily regression. Progress
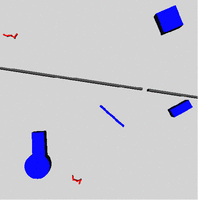
We have applied our model to several simple domains (pictured at right) to show that it can appropriately distinguish between the possible strategies presented by a probabilistic planner, and learn several functions for generating useful path segments given a task template instantiation. In the first three domains, the robot platform is a mobile planar arm, and in the last domain it is a simple gripper with a fixed base. Each picture shows one start and one goal location. The task template for the "hole-in-wall" domains includes the x,y-position of the hole, and its orientation. The task template for the zig-zag corridor is simply the y-position of the corridor. Each of these parameters is chosen randomly for a given planning problem. We use Stanford's single-query bi-directional lazy (SBL) planner [3] to generate the data used to train our model. We have also modified this planner so that it can take in path segment suggestions along with the usual desired start and goal configurations for a planning task. We then compared the planning time required by the SBL planner to the time required by the modified planner when supplied with path segment suggestions generated by our trained model. Future WorkWhile our preliminary results are somewhat encouraging, there are several areas for future work. First, our model makes a number of assumptions that we need to examine closely, and possibly relax. For mathematical convenience, we assume that the probability of a particular strategy was independent of the particular task template instantiation. While this was a reasonable assumption in the first two of our domains, it is likely one of the reasons we met with less success in the more complicated domains. Another area where more work is needed is in extracting the appropriate path segment from the whole SBL path to use as training data. We may also want to consider whether there is some other space in which to embed our path segments so that the learning problem from input parameters to path segments is more learn-able. These are intermediate areas of interest In the long run, we must also consider what types of problems we should attempt to solve via task templates and what these templates should look like. We would like to find a set of templates that can be combined to allow an agent to solve many real-world problems. Once a set of templates has been found, we must address the question of how to apply the templates to a particular planning environment. References:[1] D. Hsu, L. Kavraki, J.-C. Latombe, R. Motwani, and S. Sorkin. On Finding Narrow Passages with Probabilistic Roadmap Planners. In Proc. Int. Workshop on Algorithmic Foundations of Robotics (WAFR), 1998. [2] S. Gaffney and P. Smyth. Trajectory Clustering with Mixtures of Regression Models. In Conference in Knowledge Discovery and Data Mining, pages 63-72, 1999. [3] G. Sanchez & J. C. Latombe. A Single-Query Bi-Directional Probabilistic Roadmap Planner with Lazy Collision Checking. In Int. Symposium on Robotics Research (ISRR '01). Lorne, Victoria, Australia, November 2001. |
|||||||||||||||
|
||||||||||||||||