
Transductive Information Regularization
Adrian Corduneanu & Tommi Jaakkola
What
We study a principle for semi-supervised learning based on optimizing the rate of communicating the labels for unlabeled points with side information, where the side information is expressed in terms of identities of sets of points (regions) with the purpose of biasing the labels in each region to be the same. We analyze the semi-supervised principle on categorization of web pages.
Why
In traditional supervised learning classification algorithms are estimated from a set of examples that are labeled with the correct category. Unfortunately, labeling examples is expensive as it must involve human annotators, while unlabeled examples of unknown category are typically readily available. As an extreme example, it takes months of experimental effort by skilled experts to label a single protein with its shape for the purpose of protein shape classification. Semi-supervised methods, that use a combination of a few labeled and large amounts of unlabeled examples to estimate classifiers, have the potential of revolutionizing classification.
How
Given a training set that includes a few labeled and many unlabeled data, we represent a priori biases that certain points have similar labels through a set of regions, where points in each region are related. The set of regions may come from proximity in a distance metric relevant to classification, or from side information such as the way webpages are linked with each other.
The topology of these regions that covers the data expresses our a priori bias on how labels should be distributed in space. We formalize this bias as a regularizer defined on the set of regions, which is the average local mutual information between the identity of the point and its label. The objective is convex and can be optimized exactly and efficiently by a variant of the Blahut-Arimoto algorithm [8].
Progress
We demonstrated that transductive information regularization is able to improve classification performance on both synthetic data and the WebKB classification task in comparison to the standard naive Bayes + expectation maximization semi-supervised algorithm [9]. To illustrate the potential of information regularization, in the following example initially only two data points are labeled, and we are able to label everything correctly with information regularization:
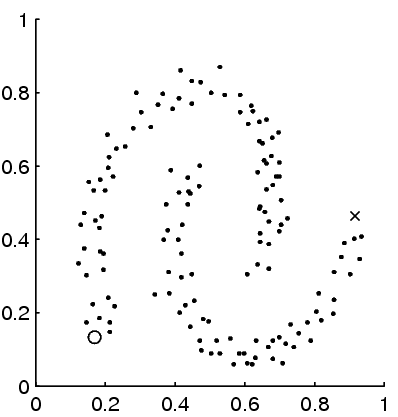 |
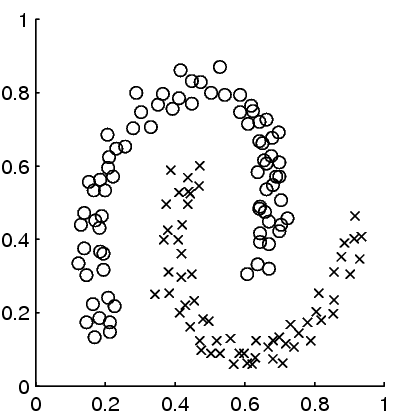 |
Future
The framework of information regularization is quite flexible and admits various important extensions that must be studied. When the meaning of the region topology is be modified to represent proximity in the model generating the labels, rather than in the identity of the labels themselves, many machine learning concepts can be represented in terms of information regularization. For example, the expectation maximization algorithm for optimizing latent variables can be seen as information regularization. One extension that is particularly important and needs to be studied closely is a variant that runs an algorithm similar to co-training [1], where two independent classification algorithms reinforce each other across points on which they are confident.
References
[1] A. Blum and T. Mitchell. Combining labeled and unlabeled data with co-training. In Proceedings of the 1998 Conference on Computational Learning Theory, 1998.
[2] X. Zhu, Z. Ghahramani, and J. Lafferty. Semi-supervised learning using gaussian fields and harmonic functions. In Machine Learning: Proceedings of the Twentieth International Conference, 2003.
[3] M. Szummer and T. Jaakkola. Partially labeled classification with markov random walks. In Advances in Neural Information Processing Systems 14, 2001.
[4] O. Chapelle, J. Weston, and B. Schoelkopf. Cluster kernels for semi-supervised learning. In Advances in Neural Information Processing Systems 15, 2002.
[5] M. Szummer and T. Jaakkola. Information regularization with partially labeled data. In Advances in Neural Information Processing Systems 15, 2003.
[6] A. Corduneanu and T. Jaakkola. On information regularization. In Proceedings of the 19th UAI, 2003.
[7] T. M. Cover and J. A. Thomas. Elements of Information Theory. Wiley & Sons, New York, 1991.
[8] R. E. Blahut. Computation of channel capacity and rate distortion functions. In IEEE Trans. Inform. Theory, volume 18, pages 460473, July 1972.
[9] K. Nigam, A.K. McCallum, S. Thrun, and T. Mitchell. Text classification from labeled and unlabeled documents using EM. Machine Learning, 39:103134, 2000.
The Stata Center, Building 32 - 32 Vassar Street - Cambridge, MA 02139 - USA tel:+1-617-253-0073 - publications@csail.mit.edu (Note: On July 1, 2003, the AI Lab and LCS merged to form CSAIL.) |