
Efficient Neighbor Selection in Self-Reorganizing P2P Networks
Robert Beverly, Mike Afergan & Karen Sollins
Introduction
Self-reorganization and community formation in Peer-to-Peer (P2P) overlays offers the potential to address diverse outstanding research problems including scalability, incentives and lookup efficiency [1,2]. The premise of nodes reorganizing by adding and removing peer connections to find a desirable set of neighbors is intuitively appealing. However, such distributed reorganization often requires prohibitively expensive or intractable communication between a large number of nodes. In this work, we investigate machine learning techniques to address two specific problems nodes face during reorganization: i) minimizing induced load and ii) finding nodes most likely to answer future queries.
In determining the network topology, nodes effectively make a per-neighbor classification decision: to connect or not to connect. Minimizing the induced load on other nodes maps well to a feature selection problem. Our initial analysis, based on a 72-hour trace of actual live Gnutella data, examines two questions: what machine learning models are most applicable to our problem and given each, how one should perform feature selection. We also investigate how the number and complexion of the training samples affects success rates.
We show, using live Gnutella traces, the ability to find a small number of queries with high discrimination power and build an effective classification model using these features.
Approach:
Our previous research investigated self-reorganizing networks where selfish, utility-maximizing nodes connect only to those nodes for which the benefit (derived from obtaining files) exceeds the cost (experienced when satisfying queries). This presents a decision problem. Figure 1. shows node k with potential connections to i and j. k derives benefit from connecting to i but not in connecting to j. Further, the query load from i is low while the load from j is high. Thus, k will prefer to connect to i.
Figure 1. A Decision Problem. Our previous research defines a utility function for a node k connecting to a neighbor i: uk(i). uk(i) is is a function of successful query matches minus the load induced. Positive utility indicates the two nodes wish to connect. Here k will decide to connect to i but not to j.
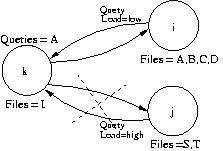
Since a link is formed only if both nodes benefit from maintaining that link, this presents a paradox. The only way to learn about another node is to issue queries, but issuing queries makes a node less desirable. Further, during this learning period, nodes may have undesirable links.
We formulate this problem as one of feature selection. Feature selection is traditionally used to reduce the computational complexity of performing classification. We however use feature selection in a novel way. In particular, we are attempting to use feature selection to minimize the number of queries, which equates to network traffic and induced query load.
As depicted in Figure 2, we view each potential Gnutella query as a feature whose value is the answer (yes or no) to the query. For example, "Dave Matthews" is a feature which is yes for node i iff node i has Dave Matthews files. As such, answering the question, "How should node k efficiently query potential neighbors?" reduces to a problem of feature selection. We seek to select a small number of queries such that we can still efficiently determine to whom the node should connect.
Figure 2. The Problem: In a self-reorganizing Peer-to-Peer network, node k must efficiently find suitable attachment point(s). Using feature selection, can k determine a small set of queries to issue to each candidate neighbor?
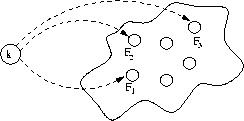
We use the utility function in conjunction with our data set to train our classifiers and then to evaluate test decisions from the classifier.
Results
The major findings of our work thus far are:
- We are able to successfully predict node type with over 80% accuracy using only 2% of features. This is a surprisingly good result.
- Forward fitting outperforms mutual information for feature selection.
- SVMs outperform Naive Bayes models by a difference of approximately 10 percentage points (which is approximately a 50% reduction in error rate).
- SVMs are relatively insensitive to the mixture of positive and negative training samples.
Consequently, we hope this work serves as a step forward for research in the space of practical self-reorganization systems and algorithms.
References
[1] K. Sripanidkulchai, B. Maggs and H. Zhang. Efficient Content Location Using Interest-Based Locality in Peer-to-Peer Systems. In Proceedings of IEEE INFOCOM, 2003.
[2] Y. Chawathe, N. Lanham, S. Ratnasamy, S. Shenker and L. Breslau. Making Gnutella-like P2P systems scalable. In Proceedings of ACM SIGCOMM, 2003.
The Stata Center, Building 32 - 32 Vassar Street - Cambridge, MA 02139 - USA tel:+1-617-253-0073 - publications@csail.mit.edu (Note: On July 1, 2003, the AI Lab and LCS merged to form CSAIL.) |