
On Modelling Nonlinear Shape-and-Texture Appearance Manifolds
C. Mario Christoudias & Trevor Darrell
What
Statistical shape-and-texture appearance models (also known as deformable models) use image morphing to define a rich, compact representation of object appearance. These techniques, however, have been limited to object classes whose shape and texture manifolds are well-approximated as linear and as such they cannot be applied to many interesting object classes such as hands or mouths. In this work we propose two complementary, nonlinear deformable models that can model such object classes. To the author's knowledge, this is the first work to describe a nonlinear model of shape and appearance. We demonstrate our models using mouth images from a speaking person video sequence and compare them to a baseline linear model. A more extensive discussion of this work can be found in [1].
Why
Deformable models decompose object appearance into shape and texture representations. The shape of an object is a representation of its geometry and is typically defined by a set of feature points that lie along the object contours. The texture of an object is its "shape-free" representation and is defined by warping the image to some reference coordinate frame, typically defined by the average shape. Deformable models learn the shape and texture of an object from prototype images.
The Multidimensional Morphable Model (MMM) [6] and Active Appearance Model (AAM) [2] are probably the most well know shape-and-texture appearance models. These methods model the shape and texture of an object class using Principle Components Analysis (PCA). Linear deformable models are useful in a variety of applications including object recognition, tracking and segmentation [3, 7, 8]. By decomposing object appearance into simpler shape and texture representations, these models achieve a more rich, compact representation of object appearance over pure intensity based methods (e.g., Eigenfaces [9]). These models, however, are unable to model objects whose appearance manifolds are highly nonlinear as a result of self-occlusions or other nonlinear appearance variation.
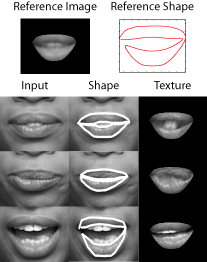 |
Figure 1 - Linear models compute a texture space by warping each example to a single reference frame. Note the stretched region present in the closed mouth textures and that the inside of the mouth is lost in the texture of the open mouth. |
Consider the linear deformable model of a speaking mouth video sequence depicted in Figure 1. In the figure, the model reference image and shape are displayed along with select prototype images and their corresponding shapes and textures. As the mouth deforms its different parts become visible, not all of which are present in the reference mouth image. Notice the streched regions in the texture of a closed mouth and the folded regions in the texture of an open mouth. These artifacts result from parts of the mouth being absent (or present) in the reference image but present (or absent) in the prototype image and they criple the constructed model. The mouth appearance manifold exhibits a varying topology, i.e., a nonlinear appearance manifold with separate regions and holes; the same parts of the mouth are visible in each region. As demonstrated by Figure 1, linear deformable models are unable to faithfully represent the appearance of the mouth. In this work we present two complementary, nonlinear deformable models that can model such object classes. The shape of object classes, such as mouths, can also exhibit a varying dimensionality, in that a mouth has shape features according to what is visible in the image (e.g., teeth shape features are present in an open mouth and absent in a closed mouth). A multidimensional shape representation allows for a more expressive and accurate deformable model. While in principle it is possible to extend both of the nonlinear approaches below to include varying shape dimensionality, the latter model lends itself more naturally to this task
How
Our first technique uses a Gaussian mixture to map out the different regions of the object appearance manifold. With this technique, a Gaussian mixture model is fit to the PCA coefficients of the prototype images. A prototype image is assigned to a mixture component if its PCA coefficients are within three standard deviations of the mean of the component's Gaussian. The overall model is defined by constructing an AAM at each component of the mixture. The shape-and-texture coefficients of a novel input image are computed by fitting the input to each local AAM and retaining the fit with the smallest error. Note this model provides a nonlinear shape-and-texture mapping that observes the varying topology of the manifold: The Gaussian mixture model maps out the different regions and holes of the manifold. Using this model, an input image is mapped to a set of local shape-and-texture coefficients associated with the region in image space that best explains the new input.
The above model offers a concise representation of the shape and texture of an object class whose appearance manifold has a varying topology. The optimal number of mixture components may be difficult to estimate, however, or can be arbitrarily large for complex manifolds whose regions are not well approximated as linear. To overcome the limitiations of a mixture model approach we propose a nearest-neighbor deformable model.
The nearest-neighbor model offers an implicit description of the object appearance manifold. It focuses on local neighborhoods of the manifold defined by k examples, computed using nearest-neighbor. It is assumed that in a given local neighborhood defined by k examples, the same parts of the object are visible. With this model, the shape and texture of a novel input is found by taking convex (or bounded) combinations of the shape and texture of its k nearest-neighbor images, an optimal combination computed with naive gradient descent. The nearest-neighbor model makes no assumptions of the global structure of the object appearance manifold and therefore generalizes well to complex manifolds. In our implementation, the nearest-neighbors of an input image are computed by comparing the input to each image of the prototype set using Euclidean distance in pixel space to measure proximity. Although we use an exhaustive search there exist fast methods for computing approximate nearest neighbors [4] that we leave for future work.
Progress
 |
 |
(a) |
(b) |
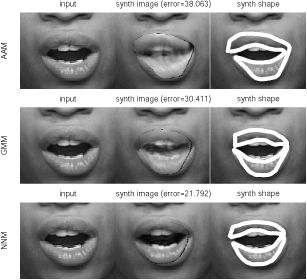
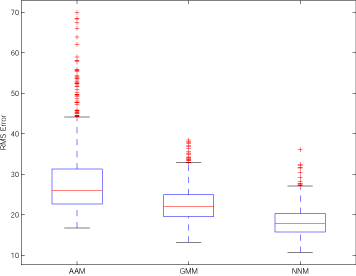
Figure 2 - Comparison of nonlinear deformable models to baseline linear method (the AAM): (a) an example where the AAM fails and the nonlinear methods succeed, (b) an RMS-error box plot of each method fit to 540 test images. In the plot, the horizontal lines of each box represent the top quartile, median and bottom quartile values, the whiskers give the extent of the rest of the data and the red crosses label data outliers. Of the three methods, the AAM displays the worst performance and the nearestneighbor model performs the best. |
|
A video sequence of a speaking person from the AVTIMIT database [5] was used to train and test our models. From this video sequence 100 frames were randomly selected and labelled with shape feature points that outline the lips (see Figure 1). These images and shapes were used to construct a Guassian mixture deformable model of the mouth. An AAM was also constructed for comparison. Multidimensional shape features were defined for these images that included shape features for the teeth. A nearest-neighbor model was defined using the 100 training images along with their multidimensional shapes.
To evaluate the performance of each approach, each model was fit to 540 test frames, outside of the training set taken from the same video sequence. Figure 2 provides a qualitative and quantitative summary of these results. In the figure, an example test image is shown where the AAM fails and the nonlinear methods succeed. A Root-Mean-Square error box plot is also provided for each approach computed over the 540-image test set. Both the Gaussian mixture and nearest-neighbor deformable models outperform the baseline linear method and of the three methods the nearest-neighbor method performs the best. The noteworthy performance of the nearest-neighbor model is expected since it makes the fewest assumptions about the underlying structure of the appearance manifold. The poor performance of the AAM on the mouth dataset is explained by the simplicity of the model. The AAM does not take into account the varying topology of the mouth appearance manifold and therefore is unable to faithfully model its appearance.
Future
In this work we have presented two nonlinear techniques for modelling the shape-and-texture appearance manifolds of complex objects whose appearance manifold has a varying topology consisting of parts and holes. We evaluated the performance of these methods using mouth images take from a speaking person video sequence and compared them to a baseline linear deformable model. Interesting avenues of future work include the construction of a person-independent mouth deformable model, the use of Locality Sensitive Hashing [4] as an alternative, more efficient method for computing nearest neighbors and the consideration of different distance metrics that are less sensitive to lighting, location, orientation and scale.
Research Support
This research was carried out in the Vision Interface Group, which is supported in part by DARPA, Project Oxygen, NTT, Ford, CMI, and ITRI. This project was supported by one or more of these sponsors, and/or by external fellowships.
References
[1] C. Mario Christoudias and Trevor Darrell. On Modelling Nonlinear Shape-and-Texture Appearance Manifolds. To appear in CVPR, San Diego, California, June 2005.
[2] T. F. Cootes, G. J. Edwards, and C. J. Taylor. Active appearance models. Lecture Notes in Computer Science, 1407:484– 98, 1998.
[3] G. Edwards, C. Taylor, and T. Cootes. Interpreting face images using active appearance models. In 3rd International Conference on Automatic Face and Gesture Recognition, pages 300–305, 1998.
[4] A. Gionis, P. Indyk, and R. Motwani. Similiarity search in high dimensions via hashing. In 25th International Conference on Very Large Data Bases, pages 518–529, 1999.
[5] T. J. Hazen, K. Saenko C. H. La, and J. Glass. A segment-based audio-visual speech recognizer: Data collection, development, and initial experiments. In Proc. ICMI, 2005.
[6] Michael J. Jones and Tomaso Poggio. Multidimensional morphable models. In ICCV, pages 683–688, 1998.
[7] Stan Sclaroff and John Isidoro. Active blobs. In ICCV, Mumbai, India, 1998.
[8] M. B. Stegmann. Analysis and segmentation of face images using point annotations and linear subspace techniques. Technical report, DTU, 2002.
[9] M. Turk and A. Pentland. Eigen faces for recognition. Journal of Cognitive Neuroscience, 3(1), 1991.
The Stata Center, Building 32 - 32 Vassar Street - Cambridge, MA 02139 - USA tel:+1-617-253-0073 - publications@csail.mit.edu (Note: On July 1, 2003, the AI Lab and LCS merged to form CSAIL.) |