
Probabilistic Tracking with Likelihood Modes
David Demirdjian, Leonid Taycher, Gregory Shakhnarovich, Kristen Grauman & Trevor Darrell
Introduction
Classic methods for Bayesian inference effectively constrain search to lie within regions of significant probability of the instantaneous temporal prior. This is efficient with an accurate dynamics model, but otherwise is prone to ignore significant peaks in the true posterior. A more accurate posterior can be obtained by explicitly finding modes of the likelihood function and combining them with an approximate temporal prior. In our approach modes are found using efficient example-based matching followed by local refinement to find peaks and estimate peak bandwidth. By reweighting these peaks according to the temporal prior we obtain an estimate of the full posterior model. We show comparative results on real and synthetic images in a high d.o.f. articulated tracking task.
Approach
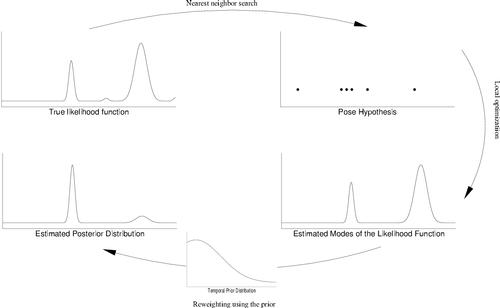
The core of our algorithm is the exploration of pose space by finding modes of the likelihood function, and weighting them by the prior to form an estimate of the posterior. Modes are estimated by initializing a model-based gradient-ascent algorithm at poses returned by a view-based regression or nearest neighbor matching algorithm. We approach online pose estimation in video sequences as filtering in a probabilistic framework. The philosophy of our algorithm is based on two observations regarding the articulated tracking task. On the one hand, body dynamics are often uncertain so the temporal pose prior is wide -- it assigns relatively large probability to large regions in the pose space. On the other hand, common likelihood functions (the compatibility between a rendered model and an observed image) are sharp, but multi-modal. A reasonable approximation to a sharply peaked multi-modal likelihood function is a weighted sum of Gaussians with small covariances. Our algorithm, ELMO (Exploration of Likelihood Modes), proceeds as follows: we estimate modes of the likelihood function by selecting a set of initial pose hypotheses and refining them using a gradient-based technique which is able to both locate the mode of the likelihood and estimate its covariance. The set of initial pose hypotheses is estimated using a parameter-sensitive hashing technique [3]. The gradient-based technique is derived from the algorithm described in [2]. We obtain the temporal prior by propagating modes of the posterior computed at the previous time step through approximate dynamics. Finally, we compute an estimate of the posterior distribution by reweighting the likelihood modes according to the temporal prior. An overview of the algorithm is shown in the figure below. In order for local optimization to succeed, it is important to select starting pose hypotheses that are sufficiently close to the modes. While it is possible to generate initial hypothesis from the wide temporal prior [1,4,5], or by uniformly sampling the pose space, in both of these methods a large number of samples would need to be drawn in order to obtain an hypothesis adequately close to the mode. We use a learning-based search method which, after being trained on a suitable number of image/pose examples, is able to quickly extract pose hypotheses that with high probability correspond to the observed image. In contrast to particle filtering approaches, in our approach repeated instances of the same hypothesis do not imply a greater probability of that hypothesis. We do assume that at least one pose hypothesis would be extracted for each peak in the likelihood function. Thus a mode with low likelihood would have low weight even if the gradient ascent algorithm converged to it from multiple starting hypothesis. The ELMO algorithm has very low computational complexity, and should be implementable in real time. The search of poses using PSH (typically 50) and the linearized local optimization for each hypothesis (usually between 50 and 60) each takes about 1 sec. per frame. Since the number of modes estimated at every time step is small, the temporal integration cost is negligible.
Experiments
In order to validate our approach, we collected real sequences of people moving in front of a stereo camera and used them as input for the ELMO algorithm. In the sequence below, a person is performing dance moves; This sequence was recorded at a slow frame rate (less than 4Hz), producing large image motions between consecutive images. The reconstruction of the 3D articulated model shows the quality of pose estimation provided by ELMO, in spite of the difficulty of the sequences (e.g. large motions, complex poses).












References
[1] K. Choo and D.J. Fleet. Fleet. Stochastic People tracking using hybrid monte carlo filtering. In the Proceedings of the International Conference on Computer Vision , 2001.
[2] D. Demirdjian, T. Ko and T. Darrell. Constraining human body tracking. In the Proceedings of the IEEE International Conference on Computer Vision, pp. 1071--1078, Nice, France, October 2003.
[3] K. Grauman, G. Shakhnarovich, and T. Darrell. Inferring 3d structure with a statistical image-based shape model. In the Proceedings of the IEEE International Conference on Computer Vision, Nice, France, October 2003.
[4] H. Sidenbladh, M. Black, and D.J. Fleet. Stochastic tracking of 3d human figures using 2d image motion. In the Proceedings of the European Conference on Computer Vision , 2000.
[5] C. Sminchiesescu and B. Triggs. Estimating articulated human motion with covariance scaled sampling. In Int. J. Robotics Research, vol. 22, pp. 371--391, June 2003.
The Stata Center, Building 32 - 32 Vassar Street - Cambridge, MA 02139 - USA tel:+1-617-253-0073 - publications@csail.mit.edu (Note: On July 1, 2003, the AI Lab and LCS merged to form CSAIL.) |