
Operand Clustering to Improve Scalability in Superscalar Microprocessors
Jessica Tseng & Krste Asanovic
Introduction
The growing trend of exploiting instruction-level parallelism (ILP) in simultaneous multithreading (SMT) architectures leads to ever greater issue widths. Previous studies [1] have shown that centralized structures such as issue queues and register files scale poorly to accommodate increased issue width. The issue queue holds instructions in check until the appropriate operands are ready while the register file provides buffered communication of operand values between producer and consumer instructions. This lack of scalability is exacerbated as feature size decreases because latency and performance are dominated by the interconnect. The long broadcasting busses and bitlines of these structures make increasing the number of ports and entries difficult.
Many techniques have been previously proposed to solve these challenges. Some approaches split the microarchitecture into distributed clusters, each containing a subset of the issue queue, register file, and functional units. These schemes have the potential to scale to larger issues widths but require complex control logic to map instructions to clusters and to handle inter-cluster dependencies. Alternatively, other approaches retain a centralized microarchitecture, but divide the physical structure into smaller sub-structures. We would like to propose a centralized structure that clusters the operands in a way that effectively partitions the issue queue and register file while still maintaining a centralized structure and enabling higher levels of scalability.
Approach
Our overall approach is to work within the constraints of a centralized architecture while also incorporating the benefits of a cluster design. As shown in Figure 1, we divide the physical register file structure into interleaved banks with fewer ports per bank to reduce the area, latency, and energy consumption. Provided that the number of simultaneous accesses to any bank is less than the number of ports on each bank, this structure can provide the aggregate bandwidth. Unlike the traditional monolithic fully ported design, additional entries and ports can be easily accommodated by adding supplemental banks to the existing banked register file.
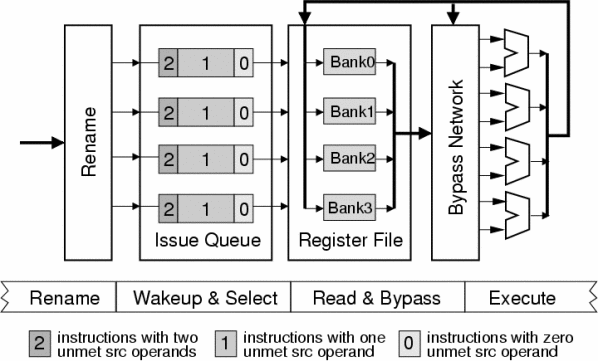
To scale the issue queues, we propose a two dimensional design where the queue is partitioned into a number of banks that are further grouped into sub-banks. During the dispatch stage, we place an instruction into the issue queue grid according to its operands. In each row, the instructions are sorted by the number of their unmet src operands and the regfile bank where the unmet src operand resides. We reduce the number of tag comparators and the length of tag-match busses in our design because we don't need to broadcast all the tags to all the instructions. In each column, the instructions are sorted by their destination operand. All the instructions in the same issue queue row would write to the same register file bank. Since we only issue one instruction per issue queue row per cycle, we simplify the select arbitration logic and minimize register file write port conflicts.
To evaluate the effectiveness of our schemes, we modified the SMTSIM [3] simulator, a cycle-accurate simulator that models an out-of-order superscalar processor with simultaneous multithreading. The SPEC CINT2000 benchmarks compiled with optimization for the Alpha instruction set were used to evaluate performance. We use Magic and HSpice to determine the area, delay, and energy consumptions of various circuitries.
Progress and Future Work
We have proposed an energy efficient banked regfile design together with a speculative control scheme suitable for a high-performance superscalar processor [2]. In our scheme, the processor speculatively issue potentially conflicting instructions but then quickly repairs the pipeline if conflicts occur. For a four-issue superscalar processor with 64 physical registers, we show that we can reduce area by a factor of three, access time by 25%, and energy by 40%, while decreasing IPC by less than 5%. For an eight-issue SMT processor with 512 physical registers, area is reduced by a factor of seven, access time by 30%, and energy by 60%, while decreasing IPC by less than 2%.
We are still evaluating our operand-clustered issue queue design with some promising initial results. We plan to extend our operand-clustering scheme beyond the issue queue and register file to include the bypass network. Combining an operand-clustered issue queue with instruction chaining can reduce the number of bypass paths to the functional units.
Research Support
This work was funded in part by NSF graduate fellowship, NSF CAREER award CCR-0093354, and DARPA HPCS project with IBM.
References
[1] S. Palacharla, N. Jouppi, and J. Smith. Complexity-Effective Superscalar Processors. In 24st International Symposium on Computer Architecture, Denver, CO, June 1997.
[2] J. Tseng and K. Asanovic. Banked multiported register files for high-frequency superscalar microprocessors. In 30st International Symposium on Computer Architecture, San Diego, CA, June 2003.
[3] D. Tullsen, S. Eggers, and H. Levy. Simultaneous multithreading: Maximizing on-chip parallelism. In 22nd International Symposium on Computer Architecture, Santa Margherita Ligure, Italy, June 1995.
The Stata Center, Building 32 - 32 Vassar Street - Cambridge, MA 02139 - USA tel:+1-617-253-0073 - publications@csail.mit.edu (Note: On July 1, 2003, the AI Lab and LCS merged to form CSAIL.) |