
Implementing Aggregation and Broadcast over Distributed Hash Tables
Ji Li, Karen Sollins & Dah-Yoh Lim
Introduction
As P2P networks grow in popularity, there is an emerging need to collect aggregate information from such systems on the parts of both administrators and application users, such as available network storage, computation capabilities, and network size estimation for randomized DHTs. Our goal is to enable a P2P network to compute an aggregation function (MIN, MAX, COUNT, SUM, AVG) over data residing at nodes or over the network itself.
We propose a bottom-up approach to build a robust tree in a P2P environment to implement aggregation. Our approach uses a parent function to help a node determine its parent dynamically, and maintain it using soft-state. Compared with previous systems on constructing trees in P2P networks which are tightly coupled with their underlying P2P networks, our approach is independent of the underlying P2P topology and thus more flexible in constructing different trees.
A Bottom-up Tree Building Algorithm
We assume that there is an efficient and robust DHT available as the underlying infrastructure. In general, any efficient DHT that performs a lookup in O(log n) steps, where n is the network size, will suffice.
Parent Function
A key part in our bottom-up tree-building algorithm is a many-to-one function, P(x), to map each node to a parent node in the tree based on its id x. , the parent node for a node x is the node which owns the id P(x). If node x owns Pi(x) for i = 1,..,&infin, then x is the root of the tree. If we consider nodes in a DHT as nodes in a graph and the child-parent relations determined by P(x) to be directed edges, the resulting graph is a directed tree converging at the root.
Generally, P(x), which we call a Parent Function, is a function that satisfies the following conditions:
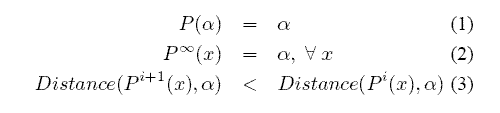
where &alpha is an id owned by the root of the tree, x is a node id, and Distance(x, &alpha) is the distance between x and the root &alpha. If a function P(x) satisfies the above conditions, there is a directed path from all nodes to the root.
A Sample Parent Function
Parent functions play a central role in determining tree properties. The following is an example adopted in this work.
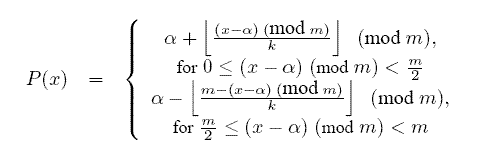
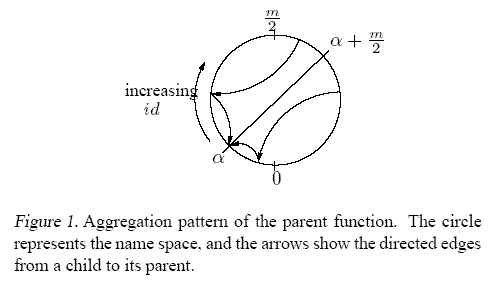
where k is a parameter that determines the branching factor of a tree, and m = 2 address space bits. As shown in Figure 1, a tree resulting from this function is rooted at a node owning the id &alpha . The expected height of a spanning tree constructed with this function is O(logk n), where n is the network size. The expected branching factor is approximately k if the nodes are uniformly distributed in the namespace (except for the root).
Tree Building Protocol
A parent function determines the properties of a tree, but it is the tree building protocol that maintains the tree. We design a bottom-up building protocol as follows:
(1) When a node x joins the network, it learns about the parent function, P(x), from an existing node. It determines Pi(x) (i > 0) and performs a lookup to locate the node responsible for Pi(x), say node y, as its parent. Then x sends a message to y to register itself as a child in terms of Pi(x), and y adds x to its list of child nodes.
(2) It is henceforth the responsibility of x to contact y periodically to refresh its status as a child node; if y fails to hear from x after a specified expiry duration, x will be deleted from y¡¯s children list. Meanwhile, x should always register at a node that owns Pi(x) with the minimum i.
(3) If y fails, x will discover it when trying to refresh its status with y. x will then use P(x) to find a new parent.
(4) Node y may find itself not responsible for the id Pi(x) any more, when a new node joins between Pi(x) and y, and becomes responsible for Pi(x). y will then inform x about it, and x will search for its new parent.
(5) Node x may discover that it should change the parent. This happens when x¡¯s current parent is found in terms of Pi(x)(i > 1), which implies that Pj(x), j = 0, 1, .., i, are covered in x¡¯s own id range. If x notices that a new node joins as its neighbor and is responsible for Pk(x)(0 < k < i), x will register at the new node and stop refreshing its status at its old parent.
There are several advantages of our algorithm. First, in this bottom-up fashion, a parent only needs to passively maintain a list of children without any active detection of their status. Each node is only responsible for refresh its status with one node, i.e., its parent. Second, a node¡¯s parent is determined by the parent function, so each node can find its parent independently and simultaneously. Without any centralized management, the tree can be repaired instantly. Third, parent changes can be detected easily by observing neighbor changes. Therefore, tree structure maintenance cost on detecting parent changes is very cheap. Please refer to [1] for details of the protocol and analysis.
Performance Evaluation
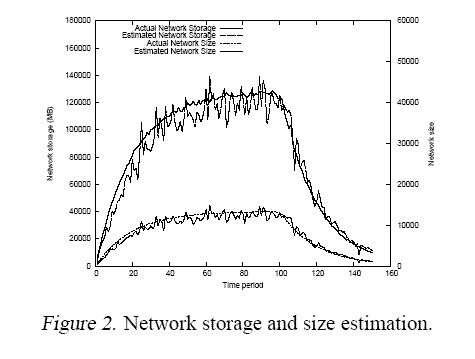
In simulation, we evaluated the properties of the constructed tree and the estimation accuracy. Specifically, as an example of usage, we estimate the available network storage in a P2P network. The parent function is the sample one and the parameters are: a = m/2, k = 4. Figure 2 shows the evolution of the network storage and the network size, and their estimates aggregated at the tree root with a node failure rate of 10%. The storage on each node keeps changing according to an exponential distribution. There are spikes which are probably caused by the failure of intermediate nodes high up in the tree. The results demonstrate however that our algorithm recovers rapidly from failures, and the average estimation is very close to the true value. Please refer to [1] for a compelete evaluation.
Conclusion
The aggregation problem is complicated by the scale and dynamics of P2P networks. We propose to build a robust tree over DHTs as a general light-weighted utility and as a base to construct trees for special usage. The reason for separating solution to tree construction from the underlying P2P topologies is to concentrate on a general purpose capability independent of but needed in many DHTs. The major advantage of our bottom-up algorithm is its relatively low overhead, resilience to node failures, and flexibility. We are currently improving our approach by designing parent functions with different properties, and methods to overcome single points of failure in a tree.
References
[1] Ji Li, Karen Sollins, and Dah-Yoh Lim. Implementing Aggregation and Broadcast over Distributed Hash Tables. In ACM Computer Communication Review (To appear in 2005).
The Stata Center, Building 32 - 32 Vassar Street - Cambridge, MA 02139 - USA tel:+1-617-253-0073 - publications@csail.mit.edu (Note: On July 1, 2003, the AI Lab and LCS merged to form CSAIL.) |