
The Borealis Stream Processing Engine
Yanif Ahmad 2, Hari Balakrishnan 3, Magdalena
Balazinska 3, Ugur Cetintemel 2, Mitch Cherniack
1, Jeong-Hyon Hwang 2, Wolfgang Lindner 3,
Samuel Madden3, Anurag S. Maskey 1, Alexander
Rasin 2, Esther Ryvkina 1, Michael Stonebraker
3, Nesime Tatbul 2, Ying Xing 2 &
Stan Zdonik 2
1Brandeis University, 2Brown University, 3MIT
Introduction
In recent years, a new class of data-intensive applications requiring near real-time processing of large volumes of streaming data has emerged. These stream processing applications arise in several different domains, including computer networks (e.g., intrusion detection), financial services (e.g., market feed processing), medical information systems (e.g., sensor-based patient monitoring), civil engineering (e.g., highway monitoring, pipeline health monitoring), and military systems (e.g., platoon tracking, target detection).
In all these domains, stream processing entails the composition of a relatively small set of operators (e.g., filters, aggregates, and correlations) that perform their computations on windows of data that move with time. Most stream processing applications require results to be continually produced at low latency, even in the face of high and variable input data rates. As has been widely noted [1, 4, 6], traditional data base management systems (DBMSs) based on the ``store-then-process'' model are inadequate for such high-rate, low-latency stream processing.
Stream processing engines (SPEs) (also known as data stream managers [1, 7] or continuous query processors [6]) are a class of software systems that handle the data processing requirements mentioned above. Over the last several years, a great deal of progress has been made in the area of SPEs. Several groups have developed working prototypes (e.g., Aurora, STREAM, TelegraphCQ) and many papers have been published on detailed aspects of the technology such as stream-oriented languages, resource-constrained one-pass query processing, load shedding, and distributed processing. While this work is an important first step, fundamental mismatches remain between the requirements of many streaming applications and the capabilities of first-generation systems.
Goals of the Borealis Project
In the Borealis project [2], we build on our previous projects in the area of stream processing: Aurora, and Medusa. We identify and address the following shortcomings of current stream processing techniques:
- Dynamic revision of query results: In many real-world streams, corrections or updates to previously processed data are available only after the fact. For instance, many popular data streams, such as the Reuters stock market feed, often include so-called revision records, which allow the feed originator to correct errors in previously reported data. Furthermore, stream sources (such as sensors), as well as their connectivity, can be highly volatile and unpredictable. As a result, data may arrive late and miss its processing window, or may be ignored temporarily due to an overload situation. In all these cases, applications are forced to live with imperfect results, unless the system has means to revise its processing and results to take into account newly available data or updates.
- Dynamic query modification: In many stream processing applications,
it is desirable to change certain attributes of the query at run time.
For example, in the financial services domain, traders typically wish
to be alerted of interesting events, where the definition of
``interesting'' (i.e., the corresponding filter predicate) varies based
on current context and results. In network monitoring, the system may
want to obtain more precise results on a specific subnetwork, if there
are signs of a potential Denial-of-Service attack. Finally, in a military
stream application that Mitre explained to us, they wish to switch to
a ``cheaper'' query when the system is overloaded. For the first two
applications, it is sufficient to simply alter the operator parameters
(e.g., window size, filter predicate), whereas the last one calls for
altering the operators that compose the running query.
Another motivating application comes again from the financial services community. Universally, people working on trading engines wish to test out new trading strategies as well as debug their applications on historical data before they go live. As such, they wish to perform ``time travel'' on input streams. Although this last example can be supported in most current SPE prototypes (i.e., by attaching the engine to previously stored data), a more user-friendly and efficient solution would obviously be desirable.
- Flexible and highly-scalable optimization: Currently, commercial
stream processing applications are popular in industrial process control
(e.g., monitoring oil refineries and cereal plants), financial services
(e.g., feed processing, trading engine support and compliance), and
network monitoring (e.g., intrusion detection, fraud detection). Here
we see a server heavy optimization problem --- the key challenge
is to process high-volume data streams on a collection of resource-rich
``beefy'' servers. Over the horizon, we see a very large number of applications
of wireless sensor technology (e.g., RFID in retail applications, cell
phone services). Here, we see a sensor heavy optimization problem
--- the key challenges revolve around extracting and processing sensor
data from a network of resource-constrained ``tiny'' devices. Further
over the horizon, we expect sensor networks to become faster and increase
in processing power. In this case the optimization problem becomes more
balanced, becoming sensor heavy, server heavy. To date, systems
have exclusively focused on either a server-heavy environment or sensor-heavy
environment. Off into the future, there will be a need for a more flexible
optimization structure that can deal with a very large number of devices
and perform cross-network sensor-heavy server-heavy resource management
and optimization. The two main challenges of such an optimization framework
are the ability to simultaneously optimize different QoS metrics such
as processing latency, throughput, or sensor lifetime and the ability
to perform optimizations at different levels of granularity: a node,
a sensor network, a cluster of sensors and servers, etc.
Such new integrated environments also require the system to tolerate various and possibly frequent failures in input sources, network connections, and processing nodes. If a system favors consistency then partial failures, where some inputs are missing, may appear as a complete failure to some applications. Therefore, Borealis provides a flexible fault-tolerance mechanism that provides the user with explicit control over the trade-off between consistency and availability [5].
Borealis Design Overview
Adding the advanced capabilities outlined above requires significant changes to the architecture of an SPE. As a result, we have designed a second-generation SPE, appropriately called Borealis. Borealis inherits core stream processing functionality from Aurora and distribution capabilities from Medusa. Borealis does, however, radically modify and extend both systems with an innovative set of features and mechanisms. We now overview the Borealis design.
One of the key changes in Borealis, is the introduction of a new data model. Traditionally, tuples (i.e., data items) are simply appended to a stream. In Borealis, tuples have different types. A tuple can be an insertion to a stream but they can also be a deletion or a replacement of a previously inserted tuple. Borealis inherits the boxes-and-arrows model of Aurora for specifying continuous queries. Boxes represent query operators and arrows represent the data flow between boxes. Figure 1 illustrates a Borealis query network spread across three processing nodes. Queries are composed of extended versions of Aurora operators that support revision messages (insertions, deletions, and replacements). Each operator processes revision messages based on its available message history and emits other revision messages as output. Aurora's connection points (CPs) buffer stream messages that compose the message history required by operators.
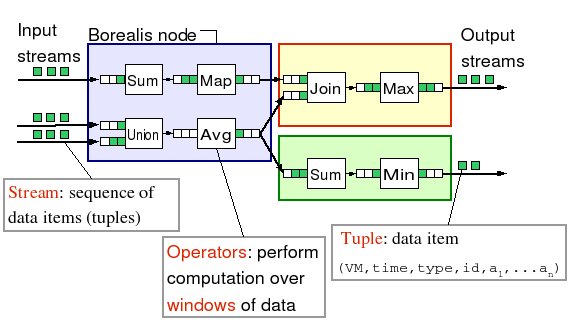
Figure 1 : Borealis Query Model.
An important addition to the Aurora query model is the ability to change box semantics on the fly. Borealis boxes are provided with special control lines in addition to their standard data input lines. These lines carry control messages that include revised box parameters and functions to change box behavior.
As in Aurora, a Quality of Service model forms the basis of resource management decisions in Borealis. Unlike Aurora, where each query output is provided with QoS functions, Borealis allows QoS to be predicted at any point in a data flow. For this purpose, messages are supplied with a Vector of Metrics (VM). These metrics include content-related properties (e.g., message importance) or performance-related properties (e.g., message arrival time, total resources consumed for processing the message up to the current point in the query diagram, number of dropped messages preceding this message). The attributes of the VM are predefined and identical on all streams. As a message flows through a box, some fields of the VM can be updated by the box code. A diagram administrator (DA) can also place special Map boxes into the query diagram to change VM.
The collection of continuous queries submitted to Borealis can be seen as one giant network of operators (aka query diagram) whose processing is distributed to multiple sites. Sensor networks can also participate in query processing behind a sensor proxy interface [3], which acts as another Borealis site. Each site runs a Borealis server whose major components are shown in Figure 2. The Query Processor (QP) forms the core piece where actual query execution takes place. The QP is composed of a Priority Scheduler, which determines the order of box execution based on tuple priorities; Box Processors, one for each different type of box, that can change behavior on the fly based on control messages from the Local Optimizer; a Load Shedder, which discards low-priority tuples when the node is overloaded; and a Storage Manager, which stores and retrieves data that flows through the arcs of the local query diagram. The Admin module controls the QP. It sets up locally running queries and takes care of moving query diagram fragments to and from remote Borealis nodes, when instructed to do so by another module.
Other than the QP, a Borealis node has modules which communicate with their peers on other Borealis nodes to take collaborative actions, such as handling failures, optimizing operator placement, load balancing, updating the catalog, starting and stopping queries. The Neighborhood Optimizer (NH Optimizer) uses local load information as well as information from other Neighborhood Optimizers to improve load balance between nodes. A single node can run several optimization algorithms that make load management decisions at different levels of granularity. The High Availability (HA) modules on different nodes monitor each other and take over processing for one another in case of failure. The Global Catalog, which may be either centralized or distributed across a subset of processing nodes, holds information about the complete query network and the location of all query fragments.
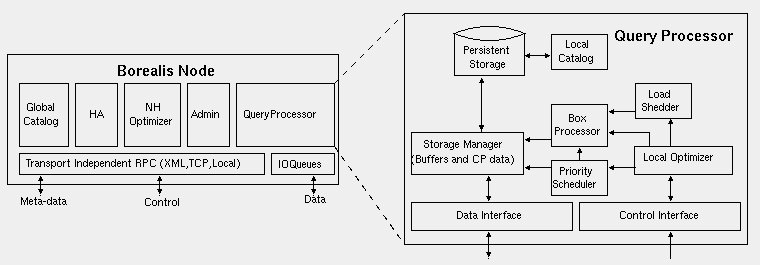
Figure 2 : Borealis Architecture
We are currently building Borealis. As Borealis inherits much of its core stream processing functionality from Aurora, we can effectively borrow many of the Aurora modules, including the GUI, the XML representation for query diagrams, portions of the run-time system, and much of the logic for boxes. Similarly, we are borrowing some networking and distribution logic from Medusa. We already have an early prototype available on our project website. We are using this prototype to develop and experiment with many of the capabilities outlined above. We study these capabilities in separate sub-projects (e.g., [3, 5, 8]).
Research Support
The Borealis project is supported by the National Science Foundation under Grants No. 0205445, IIS-0325838, IIS-0325525, IIS-0325703, and IIS-0086057. Any opinions, findings, and conclusions or recommendations expressed in this material are those of the author(s) and do not necessarily reflect the views of the National Science Foundation. Magdalena Balazinska is supported by a Microsoft Graduate Fellowship.
References:
[1] Abadi et al. Aurora: A New Model and Architecture for Data Stream Management. In VLDB Journal, 12(2), September 2003.
[2] Abadi et al. The Design of the Borealis Stream Processing Engine. In Proceeding of the Second CIDR Conference. January 2005.
[3] Daniel J. Abadi, Wolfgang Lindner, Samuel Madden, and Joerg Schuler. An Integration Framework for Sensor Networks and Data Stream Management Systems (short paper). In Proceeding of the 30th VLDB Conference, August 2004.
[4] Brian Babcock, Shivnath Babu, Mayur Datar, Rajeev Motwani, and Jennifer Widom. Models and Issues in Data Stream Systems. In Proceeding of the 2002 ACM PODS Conference. June 2002.
[5] Magdalena Balazinska, Hari Balakrishnan, Samuel Madden, and Michael Stonebraker. Fault-Tolerance in the Borealis Distributed Stream Processing System. In Proceeding of the 2005 ACM SIGMOD Conference. June 2005.
[6] Chandrasekaran et al. TelegraphCQ: Continuous Dataflow Processing for an Uncertain World. In Proceeding of the First CIDR Conference. January 2003.
[7] Motwani et al. Query Processing, Approximation, and Resource Management in a Data Stream Management System. In Proceeding of the First CIDR Conference. January 2003.
[8] Ying Xing, Stan Zdonik, and Jeong-Hyon Hwang. Dynamic Load Distribution in the Borealis Stream Processor In Proceeding of the 21st ICDE Conference. April 2005.
The Stata Center, Building 32 - 32 Vassar Street - Cambridge, MA 02139 - USA tel:+1-617-253-0073 - publications@csail.mit.edu (Note: On July 1, 2003, the AI Lab and LCS merged to form CSAIL.) |