
Using Unlabeled Data for Segmentation Tasks in Natural Language Processing
Percy Liang & Michael Collins
What
In this project, we investigate two ways to take advantage of unlabeled data to improve performance on segmentation tasks: using unlabeled data in creating new features, which are then used in a supervised model, and using active learning. We consider two segmentation tasks: Chinese word segmentation (CWS) and named-entity recognition (NER).
Why
Statistical supervised machine learning techniques have been successful in many natural language processing problems, but require labeled datasets which can be expensive to obtain. On the other hand, unlabeled data (raw text) is often available "for free" in large quantities. Unlabeled data has shown promise in improving the performance of many natural language tasks (e.g. word sense disambiguation [1], information extraction [2, 3], and parsing [4]). Our focus is not necessarily to improve performance over existing methods, but rather to significantly reduce the amount of labeled data necessary to achieve the same performance as existing methods.
How
Model: Our baseline supervised model is a discriminative tagging sequence model trained using the Perceptron algorithm [5]. In training, we learn the parameters w of a linear classifier F that maps a sequence of tokens x to a sequence of tags y.
These tags encode a (labeled) segmentation, which is a partitioning of the tokens into segments and an optional labeling of these segments. In Chinese word segmentation (CWS), the tokens are the characters and the segments are the words. In named-entity recognition (NER), then tokens are the words, the segments are the entities, and the labels are the entity types. In NER, the tag "B-X" marks the beginning of an entity X (segment with label X), "I-X" represents the continuation of entity X, and "O" means the current token is not part of an entity. We consider four types of entities X: person, organization, location, and miscellaneous. In CWS, the segments are not labeled, and the only two tags are "B" and "I".
The classifier F returns the maximum scoring output tag sequence
y given an input token sequence x, where the score of (x,
y) is simply the dot product between a feature vector 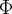 (x, y) and the parameters w. The "summarizes" (x, y) as a set of features, and the
parameters assign a weight to each feature in that set. Intuitively, a
large positive weight would suggest that the feature contributes strongly
to the fact that y is the right output for x, a large negative
weight would suggest that y is wrong, and a zero weight would mean
that the feature is irrelevant. Moreover, in our model, the (global) feature
vector decomposes into a sum over K local features
(x, y) and the parameters w. The "summarizes" (x, y) as a set of features, and the
parameters assign a weight to each feature in that set. Intuitively, a
large positive weight would suggest that the feature contributes strongly
to the fact that y is the right output for x, a large negative
weight would suggest that y is wrong, and a zero weight would mean
that the feature is irrelevant. Moreover, in our model, the (global) feature
vector decomposes into a sum over K local features
 applied to each of the n positions in the input
sequence, so F can be computed efficiently (see [5]
for details).
applied to each of the n positions in the input
sequence, so F can be computed efficiently (see [5]
for details).
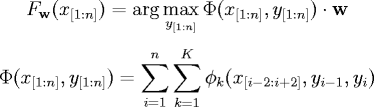
Features from unlabeled data: For CWS, we estimate the mutual information between every pair of characters, which roughly measures how likely two characters are to occur next to each other. These statistics can be computed from unlabeled data alone (unsegmented Chinese newswire text). For NER, we use a bottom-up hierarchical word clustering algorithm [6] to assign every word to a nested sequence of word classes. The algorithm initially assigns each word to its own class and then iteratively chooses two classes to merge that maximizes the likelihood of the text (with respect to the maximum likelihood class-based bigram model based on the resulting assignment of words to classes). The clustering also only requires raw text.
Two sample features are given below. Feature 10
is the mutual information between two characters in the same word. Feature
38 is an indicator of whether the word before a person's name is one of
"president", "chairman", "CEO", etc (cluster 25). Intuitively, both of
these features are likely to be positive for the correct tag sequence
(meaning that their corresponding weights 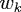 should be
high).
should be
high).
Active learning: The goal of active learning is to cut down the amount of labeled data necessary by choosing from a large pool of unlabeled examples the best examples to label next, that is, the ones that would potentially provide the most utility to the learning process. In our approach, we train an initial classifier on a randomly picked sample of 100 labeled examples. We then use this classifier to measure the certainty of each unlabeled example, which we define as the difference in scores between the best and the second best outputs [3]. We select the next batch of examples to label by sampling the unlabeled examples based on inverse certainty. Then we train on the augmented dataset and repeat.
Semi-Markov models versus Markov models: The baseline (Markov) model learns a classifier that maps an input sequence of tokens to a segmentation, where the segmentation is encoded as a sequence of tags. A more natural (semi-Markov) model [7] would map the input sequence directly to a segmentation. In the semi-Markov model, features can be defined on entire segments, rather than on a constant-size neighborhood of tags.
Progress
We have experimented with these methods on four datasets from the 2003 Chinese word segmentation Bakeoff and the 2003 CoNLL named-entity recognition English and German datasets. We have found so far that the features from unlabeled data help substantially, active learning helps only on named-entity recognition, and semi-Markov models only give a modest improvement. Results on the HK dataset for Chinese word segmentation are given below.
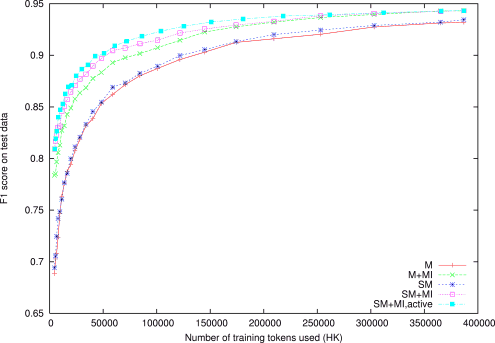
Learning curves on the HK dataset for Chinese word segmentation. M:
baseline Markov model; SM: semi-Markov model; MI: with mutual information
features; active: with active learning. learning.
Future Work
In future work, we would like to exploit the power of semi-Markov models over Markov models by using unlabeled data to create expressive features over segments, which would be difficult to incorporate into Markov models. For example, we can generalize mutual information to multi-character sequences or extend clustering to both words and multi-word sequences. By decoupling the learning algorithm from the process of generating features, we have the flexibility of using any technique to create word clusters, mutual information statistics, or other features that might be useful, of which there are many to explore.
Research Support
This work is funded by the DARPA CALO project, grant #6896567.
References
[1] David Yarowsky. Unsupervised Word Sense Disambiguation Rivaling Supervised Methods. In Proceedings of ACL 1995.
[2] Avrim Blum and Tom Mitchell. Combining Labeled and Unlabeled Data with Co-training. In Proceedings of COLT 1998.
[3] Scott Miller and Jethran Guinness and Alex Zamanian. Name Tagging with Word Clusters and Discriminative Training. In Proceedings of HLT-NAACL 2004.
[4] S. Anoop. Applying Cotraining Methods to Statistical Parsing. In Proceedings of NAACL 2001.
[5] Michael Collins. Discriminative Training Methods for Hidden Markov Models: Theory and Experiments with Perceptron Algorithms. In Proceedings of EMNLP 2002.
[6] Peter F. Brown and Vincent J. Della Pietra and Peter V. deSouza and Jennifer C. Lai and Robert L. Mercer. Class-Based n-gram Models of Natural Language. In Computational Linguistics 1992.
[7] Sunita Sarawagi and William Cohen. Semi-Markov Conditional Random Fields for Information Extraction. In Proceedings of NIPS 2004.
The Stata Center, Building 32 - 32 Vassar Street - Cambridge, MA 02139 - USA tel:+1-617-253-0073 - publications@csail.mit.edu (Note: On July 1, 2003, the AI Lab and LCS merged to form CSAIL.) |