
Learning to Trade Using "Insider" Information
Sanmay Das
The Problem
In financial markets, information is revealed by trading. Once private information is fully disseminated to the public, prices reflect all available information and reach market equilibrium. Before prices reach equilibrium, agents with superior information have opportunities to gain profits by trading. This project focuses on the design of a general algorithm that allows an agent to learn how to exploit superior or "insider" information (while the term "insider" information has certain connotations in popular belief, we use it solely to refer to superior information, however it may be obtained --- for example, paying for an analyst's report on a firm can be viewed as a way of obtaining insider information about a stock).
Suppose a trading agent receives a signal of what price a stock will trade at n trading periods from now. What is the best way to exploit this information in terms of placing trades in each of the intermediate periods? The agent has to make a tradeoff between the profit made from an immediate trade and the amount of information that trade reveals to the market. If the stock is undervalued it makes sense to buy some stock, but buying too much may reveal the insider's information too early and drive the price up, relatively disadvantaging the insider.
This problem has been studied extensively in the finance literature, initially in the context of a trader with monopolistic insider information[1], and later in the context of competing insiders with homogeneous[2] and heterogeneous[3] information. All these models derive equilibria under the assumption that traders are perfectly informed about the structure and parameters of the world in which they trade. For example, in Kyle's model, the informed trader knows two important distributions --- the ex ante distribution of the liquidation value and the distribution of other ("noise") trades that occur in each period. What if the insider does not have access to these parameters or knowledge about the structure of the market (for example, how many other insiders there are)? Can she still learn to trade in an optimal or near-optimal manner?
Importance
While the positive aspects of an algorithm that learns how to exploit information optimally are obvious, the normative aspects are also important. One of the arguments for the standard economic model of a decision-making agent as an unboundedly rational optimizer is the argument from learning. In a survey of the bounded rationality literature, John Conlisk lists this as the second among eight arguments typically used to make the case for unbounded rationality[4]. To paraphrase his description of the argument, it is all right to assume unbounded rationality because agents learn optima through practice. Commenting on this argument, Conlisk says "learning is promoted by favorable conditions such as rewards, repeated opportunities for practice, small deliberation cost at each repetition, good feedback, unchanging circumstances, and a simple context." The learning process must be analyzed in terms of these issues to see if it will indeed lead to agent behavior that is optimal and to see how differences in the environment can affect the learning process. The design of a successful learning algorithm for agents who are not necessarily aware of who else has inside information or what the price formation process is could elucidate the conditions that are necessary for agents to arrive at equilibrium, and could potentially lead to characterizations of alternative equilibria in these models.
Approach:
One way of approaching the problem of learning how to trade in this framework is to apply a standard reinforcement learning algorithm with function approximation[5]. Fundamentally, the problem posed here has continuous state and action spaces, which pose hard challenges for reinforcement learning algorithms. However, reinforcement learning has worked in various complex domains. There are two key differences between these successes and the problem studied here that make it difficult for the standard methodology to be successful. First, successful applications of reinforcement learning with continuous state and action spaces usually require the presence of an offline simulator that can give the algorithm access to many examples in a costless manner. The environment envisioned here is intrinsically online --- the agent interacts with the environment by making potentially costly trading decisions which actually affect the payoff it receives. Achieving a high flow utility from early on in the learning process is important to agents in such environments. Second, the sequential nature of the auctions complicates the learning problem. If we were to try and model the process in terms of a Markov decision problem (MDP), each state would have to be characterized not just by traditional state variables but by how many auctions in total there are, and which of these auctions is the current one. The optimal behavior of a trader at the fourth auction out of five is very different from the optimal behavior at the second auction out of ten, or even the ninth auction out of ten. While including the current auction and total number of auctions as part of the state would allow us to represent the problem as an MDP, it would not be particularly helpful because the generalization ability from one state to another would be poor.
An alternative approach is to use explicit knowledge of the domain and learn separate functions for each auction. The learning process receives feedback in terms of actual profits received for each auction from the current one onwards. The important domain facts that help in the development of a learning algorithm are based on Kyle's results. Kyle proves that in equilibrium, the expected future profits from auction i onwards are a linear function of the square difference between the liquidation value and the last traded price. He also proves that the next traded price is a linear function of the amount traded. These two results are the key to the learning algorithm, which can learn from a small amount of randomized training data and then select the optimal actions according to the trader's beliefs at every time period, without the need for explicit exploration.
Progress:
Initial experiments demonstrate that it is possible for traders to learn the optimal trading strategy using the learning model described above while maintaining a high flow utility (without the need for explicit exploration beyond initial random trading). For example, Figure 1 shows the average absolute values of quantities traded at each auction by a learning trader when there are four auctions per episode. The values converge slowly towards the optimal quantities although the trader reveals more information earlier (by trading more heavily at earlier auctions) than she would if she had full information and had solved the equilibrium equations to decide on a trading strategy. The actual profits achieved are very close to the optimal profit after about 7000 episodes, as can be seen from Figure 2.
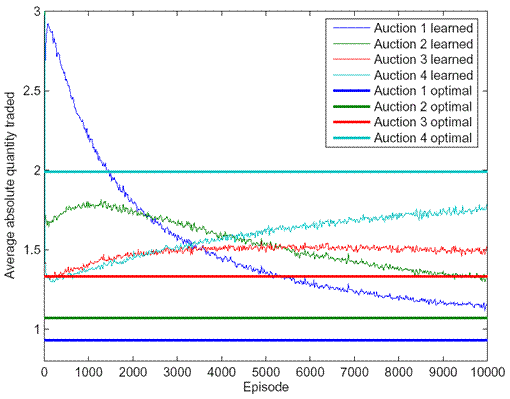
Fig. 1: Average value of quantity traded at each auction by
a learning trader as the number of episodes increases. The graph
also shows what the average value would have been for an optimal equilibrium
trader.
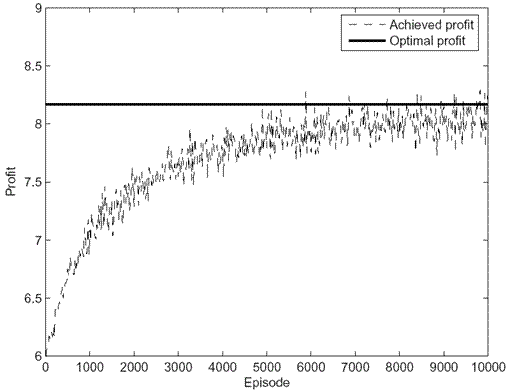
Fig. 2: Profits achieved by a learning trader when there are
4 auctions. The average profit comes very close to the optimal as
the trader learns.
An interesting fact is that the scale of time required to reach the optimum is high and initial experiments demonstrate that it appears to increase dramatically with the number of auctions. It is also likely to be a function of the variance of noise trading. It is thus probably impractical to assume that agents will learn this equilibrium over time in most settings.
Future Work:
We are interested in understanding and characterizing the time scale necessary to reach equilibrium under the model presented here. The number of auctions per episode and the level of noise trading in the system are probably key factors that need to be investigated in this regard.
It is possible that our algorithm does not scale well in terms of total utility achieved over the trading life of an agent, especially with a large number of auctions. In this case, it might be better for agents to use an approximation algorithm, perhaps treating the price change at each auction as similar to other auctions (this should continue to become a better model as the total number of auctions per episode increases, and it should allow for quicker learning).
Another possible direction for this work is the multi-agent learning problem. First, what if more than one insider is learning? They could potentially enter or leave the market at different times, but we are no longer guaranteed that everyone other than the learning agent is playing the equilibrium strategy. What are the learning dynamics? What does this imply for the system as a whole? Further, the presence of suboptimal insiders ought to create incentives for the market-makers to deviate from the complete-information equilibrium strategy in order to make profits. What can we say about the learning process when both market-makers and insiders may be learning?
Acknowledgments:
This report describes research done at the Center for Biological & Computational Learning, which is in the McGovern Institute for Brain Research at MIT, as well as in the Dept. of Brain & Cognitive Sciences, and which is affiliated with the Computer Sciences & Artificial Intelligence Laboratory (CSAIL).
This research was sponsored by grants from: Office of Naval Research (DARPA) Contract No. MDA972-04-1-0037, Office of Naval Research (DARPA) Contract No. N00014-02-1-0915, National Science Foundation (ITR/SYS) Contract No. IIS-0112991, National Science Foundation (ITR) Contract No. IIS-0209289, National Science Foundation-NIH (CRCNS) Contract No. EIA-0218693, National Science Foundation-NIH (CRCNS) Contract No. EIA-0218506, and National Institutes of Health (Conte) Contract No. 1 P20 MH66239-01A1.
Additional support was provided by: Central Research Institute of Electric Power Industry (CRIEPI), Daimler-Chrysler AG, Compaq/Digital Equipment Corporation, Eastman Kodak Company, Honda R&D Co., Ltd., Industrial Technology Research Institute (ITRI), Komatsu Ltd., Eugene McDermott Foundation, Merrill-Lynch, NEC Fund, Oxygen, Siemens Corporate Research, Inc., Sony, Sumitomo Metal Industries, and Toyota Motor Corporation.
References:
[1] Albert S. Kyle. Continuous auctions and insider trading. Econometrica, 53(6):1315-1336, 1985.
[2] C. W. Holden and A. Subrahmanyam. Long-lived private information and imperfect competition. The Journal of Finance, 47:247-270, 1992.
[3] F. D. Foster and S. Viswanathan. Strategic trading when agents forecast the forecasts of others. The Journal of Finance, 51:1437-1478, 1996.
[4] John Conlisk. Why bounded rationality? Journal of Economic Literature, 34(2):669-700, 1996.
[5] R. S. Sutton and A. G. Barto. Reinforcement Learning: An Introduction. MIT Press, Cambridge, MA, 1998.
The Stata Center, Building 32 - 32 Vassar Street - Cambridge, MA 02139 - USA tel:+1-617-253-0073 - publications@csail.mit.edu (Note: On July 1, 2003, the AI Lab and LCS merged to form CSAIL.) |