
Generating Synthetic User Data for Domain-specific Language Model Training
Chao Wang & Stephanie Seneff
Introduction
One of the major hurdles facing spoken language system deployment is the problem of acquiring adequate coverage of the possible syntactic and semantic patterns to train both the recognizer and the natural language system. Such training material typically comes in the form of an appropriate set of training utterances (e.g., for the recognizer n-gram language model) representing the distribution of typical queries within the application domain. Such utterances are normally acquired either by an intensive and expensive wizard-of-oz data collection effort, or by otherwise cajoling users to interact with a usually poorly performing early instantiation of the system. Neither of these options is attractive, and therefore we have sought an alternative solution to this problem.
Methodology
We envision that existing corpora available in one information query application can be transformed into queries appropriate for another application. Our strategy involves substantial reconstruction of out-of-domain utterances [1], followed by extensive filtering to obtain a high-quality subset of the generated material [2]. Specifically, we induce sentence templates from a large existing corpus (in the flight domain), substituting noun and prepositional phrases appropriate for a new domain (restaurant information). We then explore two distinct methods to sample from this rich over-generated corpus to form training data that would realistically reflect frequency distributions found in a corpus of interaction dialogues using the application. The first method uses user simulation technology, which obtains the probability model via an interplay between a probabilistic user model and the dialogue system. The second method synthesizes novel dialogue interactions by modeling after a small set of dialogues produced by the system developers during the course of system refinement.
Evaluation Experiments and Results
We compared the quality of various sets of language model data via speech recognition performance on a set of test data collected from naive users, who were asked to interact with the restaurant information system via telephone. The test set consists of 520 utterances collected from 72 phone calls. The data were transcribed manually to provide reference transcripts. During the course of system development, we have also collected over 3000 sentences from developers interacting with the system, either via a typed interface or in spoken mode. These data can serve both as a benchmark against which to reference our synthetic corpus performance and as templates from which to guide a further subselection process.
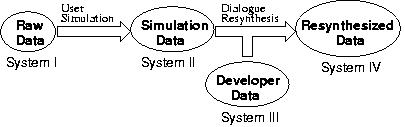
We conducted a number of recognition experiments, as illustrated in Figure 1. These experiments progress through increasingly sophisticated techniques for exploiting the simulation and developer data. System I is trained using all the original synthetic data, which totals over 130,000 utterances, and attempts to cover all combinatoric variations in sentence patterns and class values. System II is trained using a set of over 12,500 synthetic utterances obtained by user simulation. System III is a benchmark system based only on the developer data. System IV uses developer data as a user model to generate similar but novel dialogues from the synthetic data, to broaden the language coverage of the developer data while still maintaining a similar mixture of semantic contents.The resulting data were combined with the developer data in language model training.
| System | I | II | III | IV | Oracle |
| Word Error Rate (%) | 30.7 | 22.0 | 19.1 | 17.9 | 12.2 |
Table 1. Word error rates (WER) for different experimental conditions.
Our experimental results are summarized in Table 1 in terms of word error rate. We expect that the resulting data from user simulation runs are much more refined than the original data set, both in terms of the semantic content of the sentences (i.e., different types of queries) as well as the probability distribution of the within-class values (e.g., cuisine types, neighborhood names, etc.). This is verified by the experimental results: the word error rate dropped from 30.7% for System I to 22.0% for System II, a 28.3% reduction in error. System III, which uses only the developer data in language model training, achieved a word error rate of 19.1%, suggesting that the developer data provides a closer model to real user interaction than the approximation modeled by the user simulator. However, System IV is able to achieve a small but statistically significant improvement over System III by augmenting developer data with synthetic data of similar semantic contents.
An "oracle" condition, in which the language model is trained using only transcriptions of test data, yielded a word error rate of 12.2%. This represents a lower bound of word error rate achievable via language model manipulations for this test set.
Conclusions
While other work on spoken language modeling has focused on exploiting out-of-domain data via interpolation or adaptation, this paper approaches the problem by automatically over-generating domain-dependent data from out-of-domain sources followed by filtering to achieve a desired frequency distribution of the semantic content realistic for the new application. Our recognition results have shown that a partial match to usage-appropriate semantic content distribution can be achieved via user simulations. Furthermore, limited development data, if available, can be exploited to improve the selection process.
Research Support
Support for this research was provided by an industrial consortium supporting the MIT Oxygen Alliance.
References:
[1] Grace Chung, Stephanie Seneff and Chao Wang. Automatic Induction of Language Model Data for A Spoken Dialogue System. Submitted to 6th SIGdial Workshop on Discourse and Dialogue, Lisbon, Portugal, September 2005.
[2] Chao Wang, Stephanie Seneff and Grace Chung. Language Model Data Filtering via User Simulation and Dialogue Resynthesis. Submitted to 9th Eurospeech Conference, Lisbon, Portugal, September 2005.
The Stata Center, Building 32 - 32 Vassar Street - Cambridge, MA 02139 - USA tel:+1-617-253-0073 - publications@csail.mit.edu (Note: On July 1, 2003, the AI Lab and LCS merged to form CSAIL.) |