
Multi-Agent Learning: From Game Theory to Ad-hoc Networks
Yu-Han Chang & Leslie Pack Kaelbling
The Problem
In large multiagent situations, partial observability, coordination, and credit assignment persistently plague attempts to design good learning algorithms. Mobilized ad-hoc networking can be viewed as such a situation. Using tools from reinforcement learning, game theory, and signal processing, we devise general methods for learning effective behavior policies in multi-agent environemnts. We can then specialize these techniques to create useful methods for learning good routing and movement policies in mobilized ad-hoc networks.
In non-cooperative settings, we have an even greater challenge. There is no such thing as an opponent-independent, globally-optimal learning algorithm. An algorithm's performance directly depends on the type of opponent it ends up facing in practice. We introduce the idea of hedged learning, which attempts to tackle this problem by learning good response strategies against sets of possible opponent types, while ensuring that it cannot be exploited by an intelligent adversary.
Motivation
We share the world with many other human agents, many of whom are presumably intelligent. We spend many of our years learning how to adapt to this society of humans. As we create more and more systems that include artificial agents, we will begin to share our environment with these artificial agents as well. Their interactions with humans and with other artificial agents must be carefully studied and understood. The goals of our created agents may begin to conflict with one another, or we may see the potential for cooperative behaviors amongst the agents. Each agent must learn how to survive in the face of its adversaries or to cooperate in the company of its friends. In this research, we aim to investigate the nature of these multi-agent interactions and to propose algorithms that enable agents in such settings to learn effective behavior strategies.
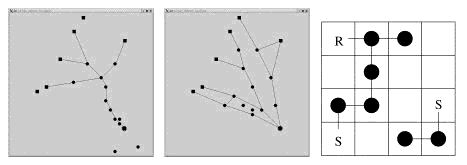
Figure 1 : (Left) Using the directional routing policy,
packets often become congested on the trunk of the network tree. (Center)
Using Q-routing on the same experimental setup, the mobile nodes in the
ad-hoc network spread out to distribute packet load. Sources are shown
as squares, mobile nodes are circles, and the receiver is an encircled
square. Both figures show the simulator after 10000 periods, using the
same initialization and movement files. (Right) The adhoc-networking domain
simplified to a 4x4 grid world. S denotes the sources, R is the receiver,
and the dots are the learning agents, which act as relay nodes. Lines
denote current connections between nodes, which have a transmission range
of one.
Progress
Our early work focused on understanding the interactions between agents in simple competitive games [4]. An agent's belief about the complexity and nature of the other players in the game was shown to play an important role in the design of multi-agent learning algorithms. More recently, we have extended this work to consider algorithms that attempt to minimize an agent's sense of regret [1]. Since a globally optimal yet opponent-independent strategy does not exist, regret-minimization seeks to measure performance by comparing the agent's actual rewards with what it could have received had it chosen a different strategy taken from a fixed set of comparison strategies. We propose the concept of hedged learning, which allows an agent to optimize its strategies by learning best responses against a set of possible opponent types, while ensuring that the agent satisfies its goal of regret-minimization. This allows us to create an algorithm that can play well against a much larger set of possible opponents, since the algorithm is able to learn about its opponents on the fly. At the same time, its regret-minimization properties prevent the algorithm from being unduly exploited by an unexpected, intelligent adversary.
In our work on cooperative multi-agent settings, we have focused on situations where each agent may only have a limited knowledge of the global state of the world. They may only be aware of their local surroundings, perhaps due to limited sensor capabilities or limited communication between the agents. Mobile ad-hoc networking is a field where many of these assumptions are true. It is also an area that is growing in importance as sensors and wireless communications become cheap and ubiquitous. Our work applies reinforcement learning techniques to the networking problem, and we show that we can learn effective routing and movement policies for the mobile nodes [3]. Figure 1 (Left and Center) shows our network simulator running two types of packet routing policies. The right-most part of the figure shows a simplification of this domain to a grid-world, where we are able to run more detailed experiments.
Using this simplification, we explore the issues involved with having
a large number of agents learning in a partially observable environment.
One method for implementing such learning assumes that the effect of the
unobservable elements of the world, including the effect of the other
agents, can be encapsulated by an unobservable state variable [2].
We then try to estimate this variable. Each agent models the effect of
these unobservable state variables on the global reward as an additive
noise process ![]() that evolves according to
that evolves according to
![]() , where
, where ![]() is a zero-mean Gaussian random variable with variance
is a zero-mean Gaussian random variable with variance ![]() . The global reward that it observes if it is in state
. The global reward that it observes if it is in state ![]() at time
at time ![]() is
is
![]() , where
, where ![]() is a vector containing the ideal training rewards
is a vector containing the ideal training rewards ![]() received by the agent at state
received by the agent at state ![]() . Figure 2 (Left and Center) shows the advantage
of using this method over traditional
. Figure 2 (Left and Center) shows the advantage
of using this method over traditional ![]() -learning in a simple grid-world domain. The right-most part of the
figure shows the benefit of using this method in the ad-hoc networking
domain.
-learning in a simple grid-world domain. The right-most part of the
figure shows the benefit of using this method in the ad-hoc networking
domain.

Figure 2: (Left) Simple game: Filtering agents are
able to distinguish their personal rewards from the global reward noise,
and thus able to learn optimal policies and maximize their average reward
over time. (Center) Simple game: In contrast, ordinary Q-learning
agents do not process the global reward signal and can become confused
as the environment changes around them. Graphs show average rewards (y-axis)
within 1000-period windows for each of the 10 agents in a typical run
of 10000 time periods (x-axis). (Right) Grid-world ad-hoc network: Graph
shows average rewards (y-axis) in 1000-period windows as filtering (bold
line) and ordinary (thin line) agents try to learn good policies for acting
as network nodes. The filtering agent is able to learn a better policy,
resulting in higher network performance (global reward). Graph shows the
average for each type of agent over 10 trial runs of 100000 time periods
(x-axis) each.
Future
We have demonstrated that hedged learning is a useful technique by applying the algorithm to small repeated matrix games. Our next step is to scale this method up to larger stochastic games. Using richer opponent models will also help our algorithm's descriptive power, and surprisingly, may also improve the algorithm's efficiency.
We are also continuing to explore further methods for improving the performance of learning techniques for both routing and movement policies in the cooperative ad-hoc networking domain. We are considering the performance improvements that might be possible if we added limited inter-agent communication that is separate from the network packets being transmitted. The eventual goal is to develop a set of methods that allows us to robustly train a system of mobilized ad-hoc agents to behave in a way that optimizes network performance. These results would hopefully translate well to other multi-agent, global-reward settings, and we may explore such a domain in order to exhibit the generality of these methods.
References
[1] P. Auer, N. Cesa-Bianchi, Y. Freund, and R. Schapire, Gambling in a rigged casino: the adversarial multi-armed bandit problem, in Proceedings of the 36th Annual Symposium on Foundations of Computer Science, 1995.
[2] Y. Chang, T. Ho, and L. Kaelbling. All learning is local: Multi-agent learning in global reward games. InAdvances in Neural Information Processing Systems (NIPS) 16, 2004.
[3] Y. Chang, T. Ho, and L. Kaelbling. Mobilized ad-hoc networks: A reinforcement learning approach. In International Conference on Autonomic Computing (ICAC), 2004.
[4] Y. Chang and L. Kaelbling. Playing is believing: The role of beliefs in multi-agent learning. In Advances in Neural Information Processing Systems (NIPS) 14, 2002.
The Stata Center, Building 32 - 32 Vassar Street - Cambridge, MA 02139 - USA tel:+1-617-253-0073 - publications@csail.mit.edu (Note: On July 1, 2003, the AI Lab and LCS merged to form CSAIL.) |