
| Research Abstracts Home | CSAIL Digital Archive | Research Activities | CSAIL Home |
![]()
|
Research
Abstracts - 2007
|
|
A Discriminative Tree-to-Tree Translation Model for Chinese to EnglishDan Wheeler, Brooke Cowan, Chao Wang & Michael CollinsOverviewState-of-the-art statistical machine translation techniques perform poorly on languages with drastically different syntax. While any translation scheme will struggle harder the less its two languages have in common, we believe one crucial reason for this performance drop-off stems from a near-complete lack of syntactic analysis. Current systems tend to do an excellent job translating content correctly, but for a hard language pair, particularly over longer sentences, the grammatical relations between content words and phrases rarely come out right. The resulting translations are often unreadable, and perhaps worse, misleading (accidentally swapping subject and object in "Alice said to Bob ...," as a common example). Severe grammatical discrepancies, including wildly differing word order, makes Chinese to English one of the hardest language pairs to work with. The good news is that steady advances in parsing over the last decade have made syntactically motivated translation more viable. We plan to extend the discriminative tree-to-tree framework of Cowan et al [1] to the Chinese->English language pair, with the conjecture that explicitly modeling grammar through syntactic analysis on both languages will lead to improved performance over current methods. Tree-to-Tree Framework of Cowan et alBrooke Cowan, Ivona Kučerová and Michael Collins designed and implemented a tree-to-tree translation framework for German to English in 2006 [1], with similar performance to phrase-based systems [2]. At the highest level, translation proceeds sentence-by-sentence by splitting each source sentence into clauses, predicting a syntactic structure in the target language called an Aligned Extended Projection (AEP) for each source clause independently, and, finally, linking the AEPs together and collapsing to obtain the final target sentence. Verbal arguments, including subjects and objects, and adjunctive modifiers (such as PPs and ADJPs), are translated separately, currently using a phrase-based system [2]. The hope is to achieve better grammaticality through syntactic modelling at a high level, yet still maintain the same quality content translation by applying current methods to reduced (verbless) expressions. The figure below shows a simplified view of the split and predict stages on a Chinese->English example. In practice, linking and collapsing is an easy final step. 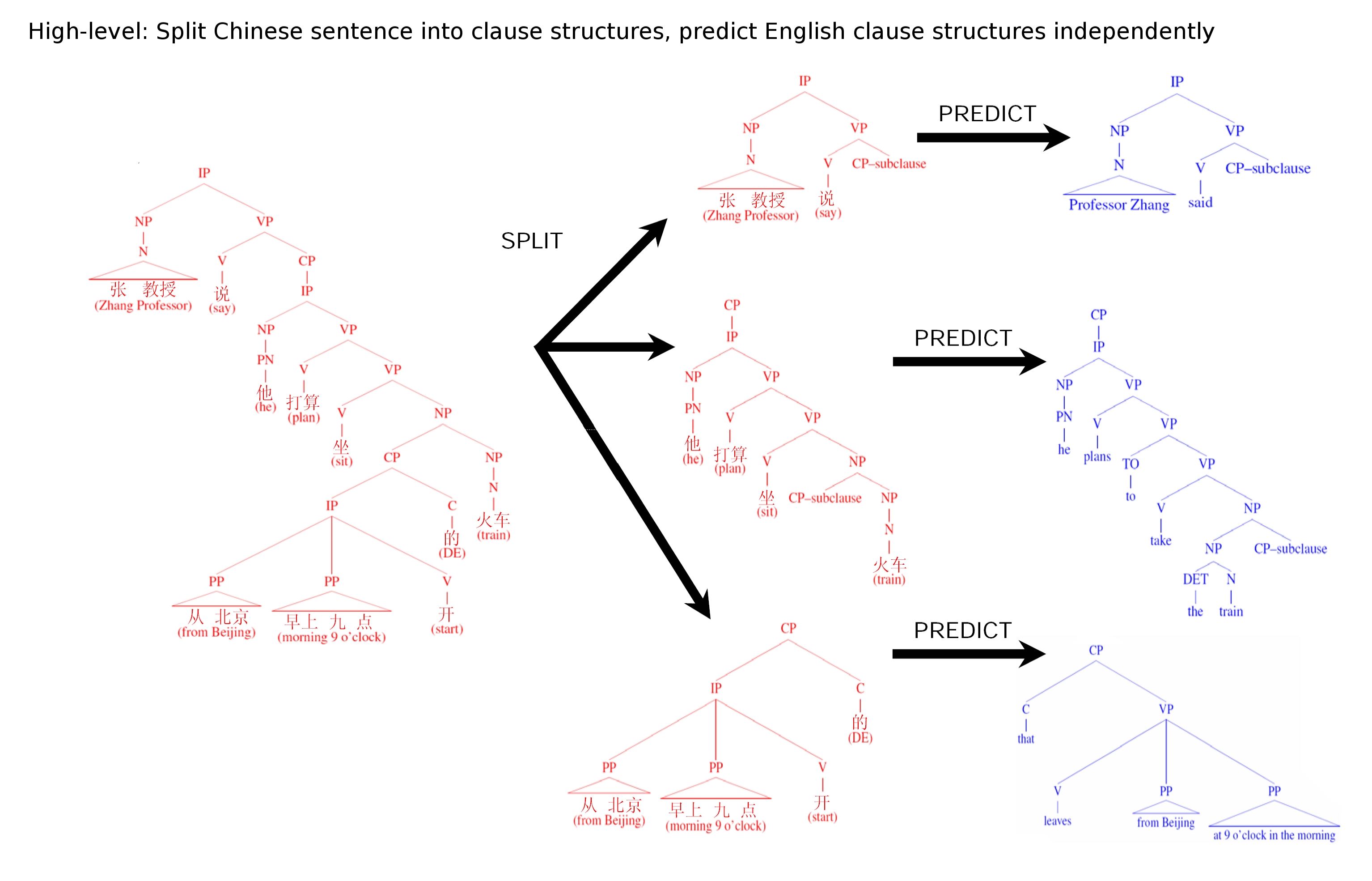
Aligned Extended Projections build on the concept of Extended Projections in lexicalized tree adjoining grammars (LTAG) as described in [3], through the addition of alignment information based on work in synchronous LTAG [4]. Roughly speaking, an extended projection applies to a content word in a parse tree (such as a noun or verb), and consists of a tree fragment around the content word that includes its associated function words, such as complementizers, determiners, and prepositions. Importantly, an extended projection around a verb encapsulates that verb's argument structure — how the subject and object attach to the clausal tree fragment, and with what function words in between. An aligned extended projection of a main verb is an EP in the target language that contains alignment information to the corresponding clause in the source language. Cowan's tree-to-tree framework provides methods for (1) extracting {source clause, target AEP} training pairs from a parallel treebank, and (2) training a discriminative feature-based model that predicts target AEPs from source clauses. A more detailed explanation, replete with examples, may be found in the original paper [1]. A few key properties are worth mentioning:
Proposed TranslatorOur training data consists of unprocessed newspaper articles from the government-run news agency of the People's Republic of China, translated in parallel to English. We plan to wrap the translation framework described above into an end-to-end system that can translate such articles. Because Chinese sentences do not contain spaces between words, tokenization must first be performed. The sentence is then parsed using a Chinese-tailored variant of the Collins parser [7]. After the tree-to-tree translation step for each clause, the resulting English AEPs are reassembled and flattened, resulting in an English output sentence.
Chinese-Specific ChallengesWe're currently thinking about how to best cope with the following Chinese-specific issues.
In EssenceThe goal of this project is twofold. We plan to:
SupportThis research is made possible through a sub-contract to BBN Technologies Corp under DARPA grant HR0011-06-C-0022 References:[1] Brooke Cowan, Ivona Kučerová and Michael Collins. A discriminative model for tree-to-tree translation. In EMNLP 2006, 2006 [2] Philipp Koehn, Franz J. Och and Daniel Marcu. Statistical phrase based translation. In HLT/NAACL 04, 2004 [3] Robert Frank. Phrase Structure Composition and Syntactic Dependencies. Cambridge, MA: MIT Press, 2002. [4] Stuart M. Shieber, Yves Schabes. Synchronous tree-adjoining grammars. In Proceedings of the 13th International Conference on Computational Linguistics, 1990 [5] Franz J. Och, Hermann Ney. A systematic comparison of various statistical alignment models. In Computational Linguistics, 29(1):19-51, 2003 [6] Michael Collins and Brian Roark. Incremental parsing with the perceptron algorithm. In ACL 04, 2004 [7] Michael Collins. Head-Driven Statistical Models for Natural Language Processing. University of Pennsylvania, 1999 |
|||
|