| Research Abstracts Home | CSAIL Digital Archive | Research Activities | CSAIL Home |
![]()
|
Research
Abstracts - 2007
|
|
Spoken Correction for Chinese Text EntryBo-June (Paul) Hsu & James R. GlassIntroductionWith an average of 17 Chinese characters per phonetic syllable, correcting conversion errors with current phonetic input method editors (IMEs) is often painstaking and time consuming. In this work, we explore the application of spoken character description as a correction interface for Chinese text entry, in part motivated by the common practice of describing Chinese characters in names for self-introductions. MotivationWhen using the most popular IME for Traditional Chinese input, correcting a conversion error involves first moving the cursor to the incorrect character and then selecting the desired character from a candidate list of homonyms with matching pronunciations, as illustrated in Figure 1. For errors far from the current cursor position, navigating to the target position can be tedious. Since some pronunciations have more than 200 matching characters, the candidate list is often divided into multiple pages. While the desired character often appears within the first page and can be selected with a single keystroke, visually finding the correct character can at times be painstaking given that characters are rendered with a small font and sometimes differ only by their radicals.
Character DescriptionsTsai et al. [1] applied spoken descriptions of characters to help resolve homonym ambiguities in Chinese names for a directory assistance application. In this work, we apply the approach of using character descriptions for disambiguating among homonyms as a correction interface for Chinese text entry using IMEs. We observe that in addition to describing characters by usage phrase (e.g. ????), descriptions using character radical (?????), compositional structure (???), and character semantics (????) are also fairly typical. In addition, since these descriptions include the target character at the end, the position of the desired character within the current IME composition can often be unambiguously inferred from the character description. Furthermore, because the pronunciations of the characters in the uncommitted IME composition are known, we can limit the recognizer grammar to only accept descriptions for characters with those pronunciations, reducing the grammar perplexity. DesignLeveraging these observations, we have extended an IME with the capability for users to correct errors in the conversion using spoken character descriptions. For each correction, the user may choose to select the target character using the arrow keys as before or press the Control key to speak a character description. Upon a successful recognition, we look up the potentially multiple candidate characters matching the description. Typically, the recognized target pronunciation only corresponds to a single syllable position in the IME composition. Thus, if the character description specifies a unique candidate, we immediately replace the character at the matching position with the user-described character, as illustrated in Figure 2(b). If the character description matches multiple characters, a list containing the candidate characters is displayed at the matching syllable position, as shown in Figure 2(c). Occasionally, the pronunciation corresponds to multiple candidate syllable positions, requiring user intervention prior to making the correction. To allow the user to select the syllable from among these candidate positions, we highlight all candidate positions, display the filtered candidate list containing the matching characters, and restrict the left/right arrow keys to navigate only among these positions, as illustrated in Figure 2(d). To reduce keystrokes, the candidate list is initially displayed under the position corresponding to the single correction that maximizes the language model likelihood.
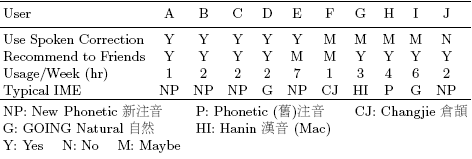
User StudyFor evaluation, we conducted a user study with 10 students from Taiwan with varying proficiency in Chinese text entry. Table 1 summarizes the results from the study. Overall, the response to spoken correction is positive, with half of the participants expressing interest in using the system. Through the post-study questionnaire, we learned that of the 5 users expressing a neutral or negative opinion, 3 have memorized deterministic key sequences of common characters for their respective IMEs. Thus, minor improvements to correcting the sporadic errors that they encounter do not justify overcoming the learning curve of a new system and the need to set up a high-quality microphone whenever performing text entry. Interestingly, of these 5 users without definite interest in using the system themselves, 4 would still recommend it to friends. As user J observed, "This system is very useful and convenient for users less familiar with Chinese input. . . [However], frequent typists will still choose selecting characters [using the keyboard]." Thus, although spoken correction may not be more effective for everyone, nearly all participants saw the potential value of such a system, even with less than 10 minutes of usage. ConclusionIn this work, we extended a commercial IME with a spoken correction interface and evaluate the resulting system in a user study. Preliminary results suggest that although correcting IME conversion errors with spoken character descriptions may not be more effective than traditional techniques for everyone, nearly all users see the potential benefit of such a system and would recommend it to friends. For additional details, please refer to the full paper at [2]. References[1] Ching-Ho Tsai, Nick J.-C. Wang, Patrick Huang and Jia-Lin Shen. Open Vocabulary Chinese Name Recognition with the Help of Character Description and Syllable Spelling Recognition. In Proc. ICASSP, Philadelphia, PA, USA, March 2005. [2] Bo-June P. Hsu and James Glass. Spoken Correction for Chinese Text Entry. In Proc. ISCSLP, Kent Ridge, Singapore, December 2006. |
|||
|