| Research Abstracts Home | CSAIL Digital Archive | Research Activities | CSAIL Home |
![]()
|
Research
Abstracts - 2007
|
|
Detecting And Tracking Multiple Interacting Objects Without Class-Specific ModelsBiswajit Bose, Xiaogang Wang & Eric GrimsonThe ProblemGiven an image sequence from a single, static, uncalibrated camera, we seek to track multiple objects in the sequence. The number of objects is variable and unknown, and object-class-specific models (such as pedestrian models or vehicle models) are not available. The object may interact with and occlude one another. MotivationThe problem of detecting and tracking multiple interacting objects arises quite commonly in unconstrained outdoor environments. It is often not feasible to use trained class-specific models of all objects that may occur in the scene. This is especially true if one is interested in tracking unusual objects for the sake of activity analysis and anomaly detection. Instead, a generic object model, that can differentiate between moving objects and the static background, can be used. However, since the number of moving objects is unknown, and can vary with time, there is a need for a method to associate foreground pixels (obtained through background subtraction) with objects. ApproachWe define a generic object model using two properties: spatial connnectedness of parts, and temporal coherence of motion of parts. Instead of associating individual foreground pixels with objects, we associate clusters of pixels (connected components) with objects. Any such cluster can be associated with a target-set, which can be a fragment of an object, a whole object, or even a group of objects. We track target-sets till they merge or split. We then use a hierarchical graph representation of the merges and splits, along with our generic object definition, to stitch together tracks of target-sets that belong to the same object. An illustration of our approach is shown below:
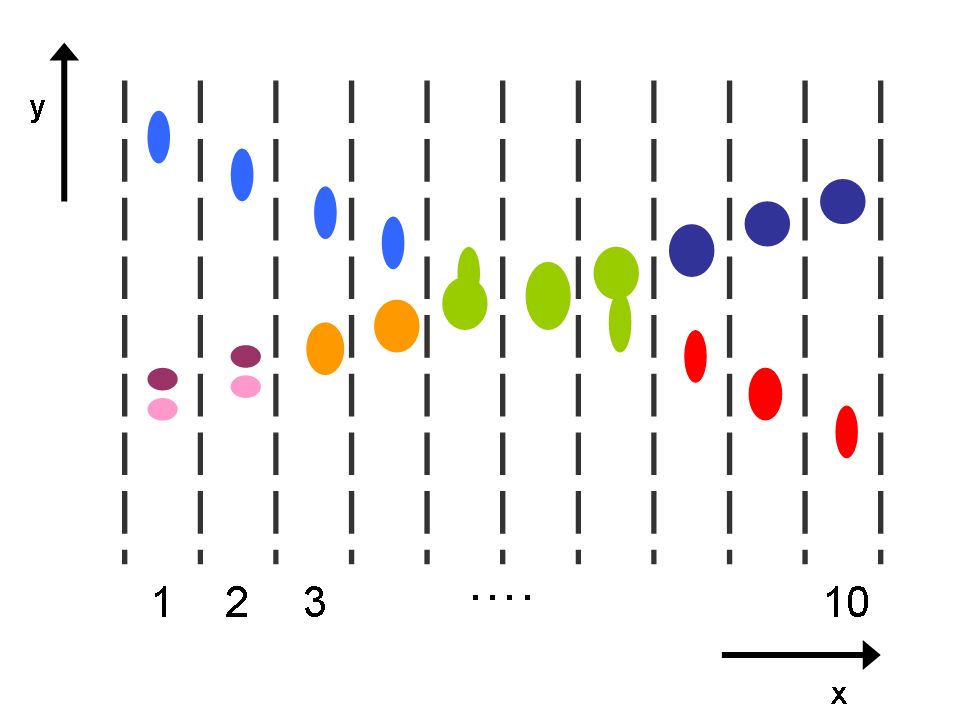
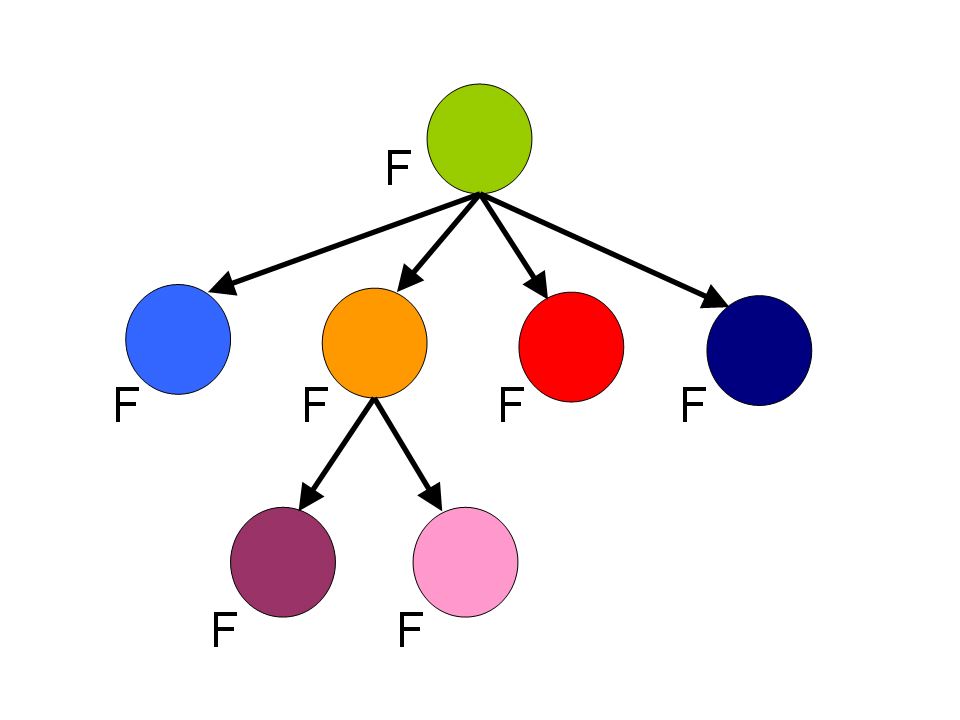
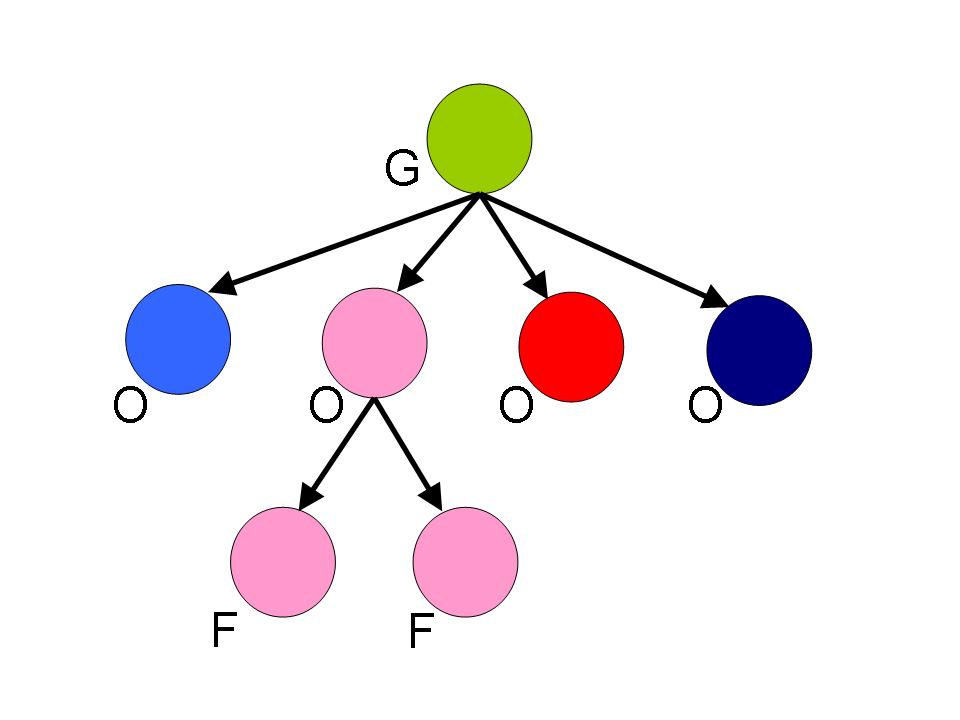
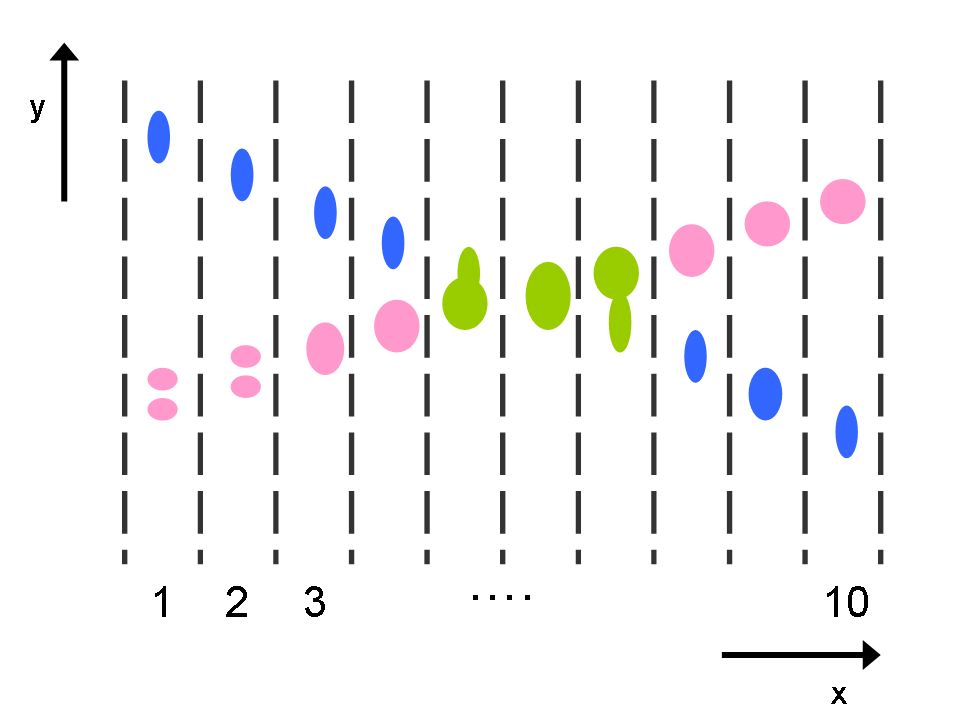
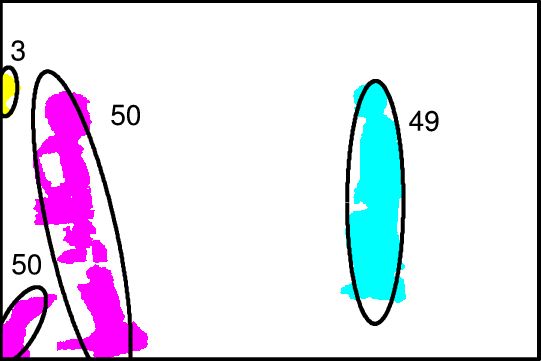
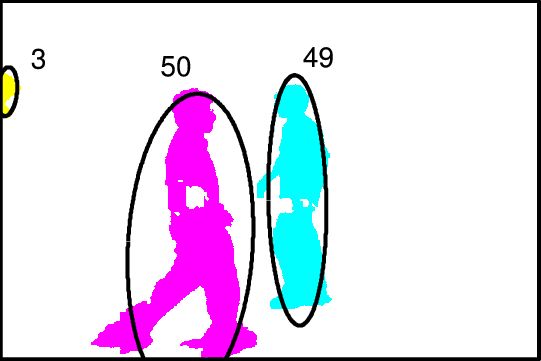
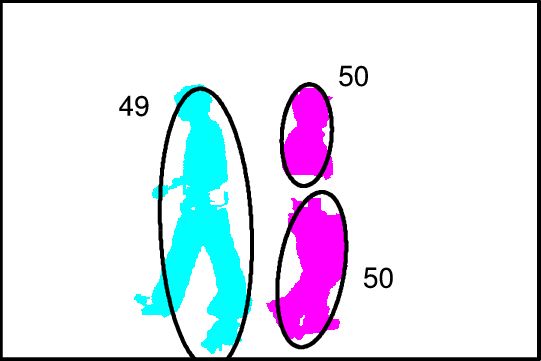
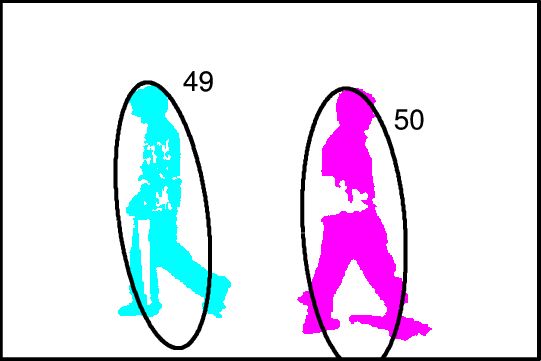
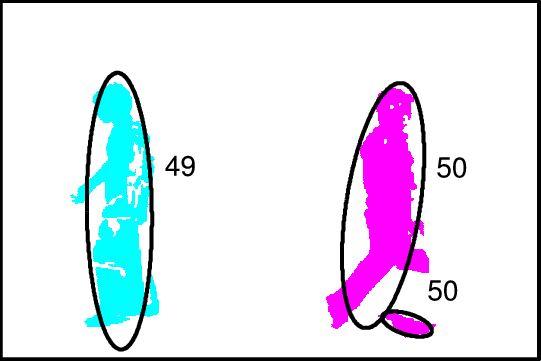
Image (a) shows measurement clusters detected in 10 frames. To show multiple frames in one image, dashed vertical lines indicate regions of the scene where measurements occur in each frame. There are two objects, moving from left to right, and crossing each other in the process, and occasionally fragmenting. Image (b) shows the inference graph constructed from merge/split events detected in (a). Colors in (a) and (b) represent target-set tracking results. Stitching of tracks and use of the object model allows labeling tracks as fragments (F), objects (O) or groups (G) (image (c)). Colors in (c) show stitched tracks. After performing association of objects across groups, image (d) shows the final result, indicated by the corresponding colors from image (c). ResultsWe tested our algorithm on a number of image sequences. Sample results from an indoor image sequence are shown below. Only the foreground pixels (after noise filtering) are shown. Ellipses indicate estimated states of tracked target-sets. Colors indicate final IDs assigned to objects/groups. Groups are indicated in black. Note that one person is almost completely occluded by the other during the interaction, and object 50 is repeatedly split into multiple foreground fragments.
Future WorkTo be able to handle more complicated types of interaction, it will be necessary to use the appearance of objects, in addition to their motion and silhouette. This appearance information can perhaps be learned online, after bootstrapping with the results of our detection/tracking system. AcknowledgementThis research was supported by funding from the Defense Advanced Research Projects Agency (DARPA) |
|||||||||||||||||
|