
| Research Abstracts Home | CSAIL Digital Archive | Research Activities | CSAIL Home |
![]()
|
Research
Abstracts - 2007
|
|
Continuous State POMDPs for Object Manipulation TasksEmma Brunskill & Nicholas RoyOverviewThe focus of this research is to improve robotic grasping of objects by explicitly modelling the uncertainty induced by imperfect sensors and actuators. During object manipulation, object dynamics can be extremely complex, non-linear and challenging to specify. To avoid modeling the full complexity of possible dynamics, we instead use a hierarchical model of a discrete number of outcomes, each which specify a different transition dynamics model. By learning these models and extending Porta's continuous state partially observable Markov decision process (POMDP) framework [2] to handle this hierarchical model of the dynamics, the hope is to be able to plan more robustly for object manipulation tasks in partially observable environments. IntroductionFrom robot tutors that can help children learn to assistive care robots that can help the sick and the elderly, robots have the potential to be hugely useful to humans. Many assistive tasks involve manipulating objects: in order to clean the house or make breakfast, a robot must interact with a variety of objects. Creating successful plans to accomplish an object manipulation task is a hard problem for several reasons. First, the robot only observes the world through its sensors which provide noisy estimates of the actual world state. In addition, the robot must plan actions over a large number of world states. Finally, it is extremely difficult to gather enough information about the world to deterministically predict the precise effect of an action: even the result of a coin flip may be deterministic if there is complete information about the previous state and action, but this is not reasonable to assume. Instead actions can be modeled as having stochastic effects. The goal then is to get the robot to plan robustly and perform tasks which involve manipulating objects in a partially sensed environment (such as in the figure below). 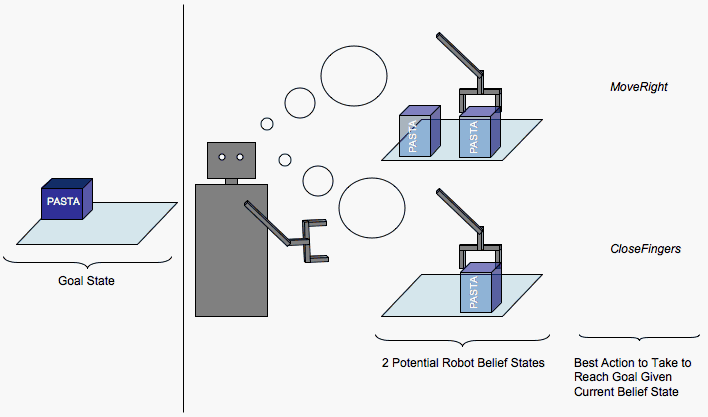
Figure 1. An example manipulation task: the best action to take depends on the robot's current belief state. Continuous POMDPsWe will set the problem within the popular partially observable Markov decision process framework [1] which endows the agent with a model of the world dynamics. We propose that the world dynamics model used can have a significant impact on the quality and tractability of plans created using the model. However, hand designing a dynamics model of the physics laws underlying object manipulation is a challenging task, particularly to design a model that facilitates planning. The figure below gives an illustration of some of the different world states that can occur for a simple world consisting of a pasta box and soup can: modelling all possible transitions between such a set of states is a formidable task. 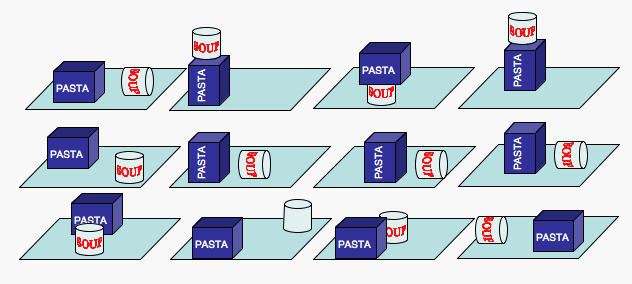
Figure 2. A few of the possible world states of a simple two object domain. Exactly modelling the possible transitions between this enormous set of states is intractable. Instead of assuming the dynamics model to be specified in advance, we hope to learn a good representation of the dynamics model which will enable tractable planning of good policies for acting in partially observed realistic domains. Learning such models of the world dynamics requires first selecting how to represent the state of the world. This work chooses to use a factored continuous representation. A factored representation can exploit existing independence between variables to create compact dynamics models, which may lead to more compact policies. The choice to use continuous instead of discrete variables is motivated by our application: object manipulation involves real valued measurements of object and robot arm locations. By using continuous values we avoid the symbol grounding problem of having to specify a mapping between higher level representations and ground sensory states (which are noisily measured by robotic sensors). However, this choice does yield an extremely large state space since the world is represented by variables that can take on an infinite number of values. Preliminary WorkThe current approach draws inspiration from Porta et. al's recent work on continuous POMDPs [2]. Porta and his collaborators proved theoretical results on continuous state POMDPs with discrete action and observation spaces. They also extended the Perseus point-based POMDP algorithm [3] to handle continuous states using a transition model that described the effect of an action by using a linear Gaussian distribution. We intend to extend this model by first allowing different transition dynamics in different parts of the state space. This can be achieved by using probability distributions to control in which part of the state space different dynamics models apply. We have developed a Expectation-Maximization (EM) technique for learning one model of such dynamics given a labeled set of data. The approach is similar to the EM algorithm for learning a set of linear Gaussian Mixture Model (GMM) parameters but instead of the cluster prior being constant across all data points, the cluster priors vary according to the previous state value. Our approach automatically learns both where the different dynamics models apply, and the parameters of those dynamics models. Future WorkThis work is still in its preliminary phases. The next task is to be able to plan with the learned dynamics in a small simulated domain. After this we plan to perform experiments on a Barrett seven degree of freedom robotic arm platform and adapt the initial approach to handle real world robotic data. References:[1] L.Kaelbling, M.Littman, and A.Cassandra. Planning and acting in partially observable stochastic domains. Artificial Intelligence. 1998. v101 p99-104. [2] J.Porta, M.Spaan, N.Vlassis, and P.Poupart. Point-based value iteration for continuous pomdps. Journal of Machine Learning Research. 2006 v7 p2329-2367. [3] M.Spaan and N.Vlassis. Perseus: Randomized point-based value iteration for pomdps. Journal of Artificial Intelligence Research. 2005. v24. p24-195. |
|||
|