| Research Abstracts Home | CSAIL Digital Archive | Research Activities | CSAIL Home |
![]()
|
Research
Abstracts - 2007
|
|
Efficient Model Learning for Dialog ManagementFinale Doshi & Nicholas Roy
Figure 1 - We equipped a standard power wheelchair with a computer and additional sensors to enable it to navigate autonomously as well as process user input. See robotic wheelchair for hardware details. OverviewSpoken language interfaces provide a natural way for humans to interact with robots, but noisy speech recognition and linguistic ambiguities often make it difficult for the robot to decipher the user's intent. Intelligent planning algorithms, such as the Partially Observable Markov Decision Process (POMDP), have succeeded in dialog management applications ([1],[2],[3]) because of their robustness to the inherent uncertainty of human interaction. Like all dialog planning systems, however, POMDPs require an accurate user model. POMDPs consist of large probabilistic models with many parameters that govern what the user may want, how the user may express themselves, and how the user will react to the robot's actions. These parameters are difficult to specify from domain knowledge--how can we quantify the likelihood that the robot will hear "coffee machine" when the user asks about the copy machine?--moreover, gathering enough data to estimate the parameters accurately a priori is expensive in the training time required from human operators. In our work, a dialog manager for a robotic wheelchair (Figure 1), we take a Bayesian approach to learning the POMDP parameters through user interactions. We capitalize on the fact that while we may not know the true parameters, we can often guess a reasonable starting point. For example, we know that a user will be quite frustrated if the wheelchair drives to the wrong location. By incorporating this kind of basic domain knowledge into our prior over parameters, our system can act robustly even as it adapts itself to a specific user and voice recognition system. Our ApproachSolving even small POMDPs is computationally hard, and in our work we explore several approaches for learning the dialog manager's parameters in robust and tractable way:
Current ResultsTable 1 shows an example dialog of how our learning dialog manager adapts to its user (using the expected value approach described above). In the first dialog, the system does not know that the word "elevator" is a location. In the later dialog, the dialog manager has discovered (1) the word "elevator" refers to two locations in the building, and (2) usually the user means the Gates elevator when she says "elevator." Thus, the dialog manager attempts to confirm the Gates location first. Table 1 - The pair of dialogs show how the dialog manager has adapted to the user. In the first scenario, the dialog manager does not know that the word "elevator" refers to a location and is forced to wait for keyword that it recognizes. In later scenarios, it learns a mapping for the new word.
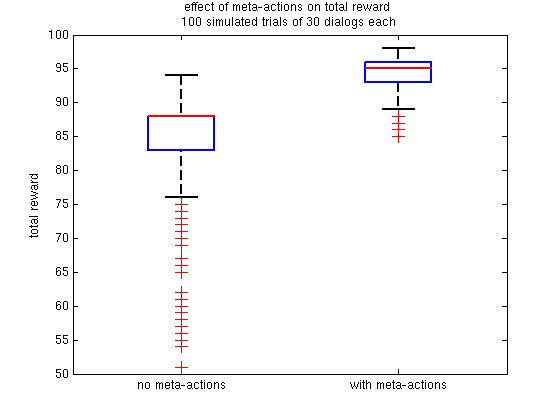
Figure 2 shows the total reward achieved over 100 simulated user trials of 30 dialogs each with and without policy queries (both systems had the ability to adapt to the user preferences). The system without policy queries (left) had no choice but to either make mistakes or act conservatively to avoid making mistakes; policy queries (right) allowed the system to discover the user's true preferences and thus act with a more optimal policy.
Figure 2 - Without meta-actions, the dialog manager has no way to learn about the user's preferences. Thus, it is forced to act more conservatively than it normally would had it known the true user model. For over half of the tests in this simulated example, the dialog manager with meta-actions scored higher than the maximum reward achieved by the non-learner. References:[1] N. Roy, J. Pineau, and S. Thrun. Spoken dialog management using probabalistic reasoning. In Proceedings of the 38th annual meeting ofthe ACL, Hong Kong, China, 2000. [2] J. Williams and S. Young. Scaling up POMDPs for dialog management: the "summary POMDP method. In Proceedings of SIGdial Workshop on Discourse and Dialog ,2005. [3] J. Hoey, P. Poupart, C. Boutilier, and A. Mihailidis. POMDP models for assistive technology, 2005. [4] R. Jaulmes, J. Pineau, and D. Precup. Learning in non-stationary partially observerable markov decision processes. In Workshop on Non-Stationary Reinforcement Learning at the ECML, 2005. [5] P. Poupart, N. Vlassis, J. Hoey, and K. Regan. An analytic solution to discrete Bayesian reinforcement learning. In Proceedings of the 23rd international conference on machine learning, pp. 697--704, New York, NY, USA, 2006. |
|||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||