| Research Abstracts Home | CSAIL Digital Archive | Research Activities | CSAIL Home |
![]()
|
Research
Abstracts - 2007
|
|
New Word Acquisition Using Subword ModelingGhinwa F. Choueiter, Stephanie Seneff & James R. GlassIntroductionThe need for more flexible and adaptive automatic speech recognition (ASR) has never been greater due to the widespread emergence of speech-enabled applications and devices as well as spoken dialogue systems for information retrieval. One of the major factors impeding the broad acceptance of ASR is the frustration experienced by users when the system breaks down when an unknown word occurs. For open-ended word recognizers with fixed vocabularies, this problem is inevitable regardless of the vocabulary size. In fact, such systems are unable to learn the pronunciation or spelling of a new word. In this research, subword modeling is used for the acquisition of new words. The subwords are generated using a context-free grammar (CFG) that encodes positional and phonological constraints. The proposed approach has the advantage of automatically learning the spelling and pronunciation of OOV words. We envision the subword model embedded within a standard word recognizer, thereby augmenting it with a learning capability. It would be activated upon the occurrence of an OOV word, and any newly acquired word can then be added to the lexical baseforms. There are many potential uses for a new word acquisition capability, such as supplying a spoken dialogue system with an error recovery mechanism in case a new word occurs. For example, when a fixed-vocabulary spoken dialogue system fails at recognizing a particular word, a second recognition pass can be initiated by some form of confidence measure or user feedback. The second pass would then utilize the subword model to estimate the faulty word. The new word acquisition mechanism can also be used to build a word recognizer bottom-up. Given a set of words whose baseforms are unavailable, the subword model can dynamically generate and update the lexical baseforms. In this preliminary work we implement the subword model within a multi-stage recognition framework where a person speaks a word, and an isolated word recognizer (Stage I) proposes and displays the top ten word candidates. If the person rejects all the words, the system enters the second stage (Stage II), which uses a subword model. It generates hypothesized word spellings via a sound-to-letter model, and filters invalid spellings using a very large lexicon. If the person rejects all top ten words presented by the second stage, a third stage (Stage III) prompts for a spoken spelling of the word. The Subword ModelThe subwords used are generated through a a Context-Free Grammar (CFG) that encodes phonological constraints and sub-syllable structure [Seneff 07]. The subwords are intermediate units between phonemes and syllables which only encode pronunciation information. The total number of subwords obtained with the CFG is 677. Table 1 illustrates the parsing of the words diction and facial into subword units such as onset and rhyme (denoted with + and - respectively). The illustration also shows a common characteristic of the English language where the same pronunciation is realized by different letter clusters (e.g., ``ti'' vs ``ci'') based on context. Two by-products of the CFG are a direct mapping between subwords and their spellings as well as between subwords and their phonemic representation. The former mapping is used to create statistical sound-to-letter (S-to-L) and letter-to-sound (L-to-S) models, while the latter to generate phonemic baseforms from subword representations.
Table 1: Parse analysis of the words diction and facial obtained using the Context-Free Grammar. We evaluate the subword model on two tasks. First, we utilize the L-to-S system to automatically generate subword and phonemic baseforms for words in a 300k lexicon. We then investigate how effective this baseforms file is in both traditional isolated word recognition and as a training corpus for the subword language model. The scenario currently simulated and used to evaluate the subword model is a multi-stage isolated word recognizer. The user first presents a word from a set of nouns, and a 55k word recognizer is utilized in Stage I to recognize the word. From this set of nouns, 3228 are in the 55k lexicon (IV), and 1454 are not (OOV). Stage I fails if the correct word is not a top 10 candidate. Failure is indicated by direct user feedback through a button click. In this case, the same utterance is then passed to Stage II, which uses the subword model to estimate a spelling cohort of size 10. If Stage II also fails, the user is prompted for a spelling of the word in Stage III. Isolated Word Recognizers We investigate the ability of the L-to-S system to automatically generate the baseforms of a 300k lexicon (Google subset). A 300k isolated word recognizer is then built and evaluated in terms of top 10 and top 20 accuracies, meaning that success occurs if the correct word is in the top 10 and top 20 candidates respectively. The results are reported in Table 2 for the IV and OOV words. It is important to note here that all the evaluated words are in the 300k lexicon, so the term OOV does not apply anymore to the 300k word recognizer. However, we choose to report the results for the two subsets (IV, OOV) separately in order to compare against the 55k word recognizer. As shown in Table 2, the performance of the IV and OOV subsets is the same for the 300k system, which illustrates that the L-to-S system has been effective in generating pronunciations for the OOV words. The IV words suffer significant degradation compared to the 55k word recognizer due to the larger vocabulary.
Table 2: Comparison of the 55k and 300k isolated word recognizers,
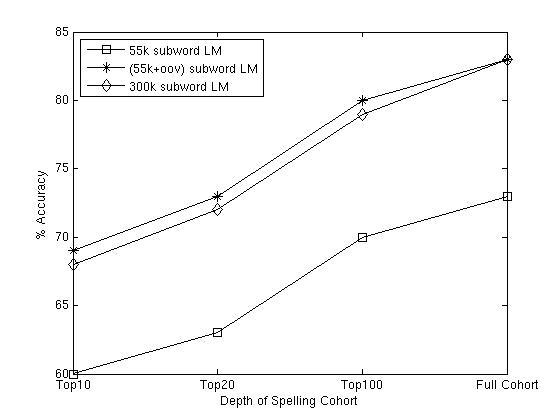
in terms of IV, OOV, and overall accuracy. Stage II: Language Models We evaluate the performance of several subword language models used in Stage II. We trained the subword LMs on three different training corpora: (1) the 55k lexicon, (2) the 55k lexicon, augmented with just the OOV words, and (3) the 300k lexicon. Figure 1 assesses the performance of the three subword recognizers built with each of the subword trigrams on the OOV words. A match occurs if the correct word is in the spelling cohort, and we report accuracies on cohorts of sizes 10, 20, and 100, as well as on the whole spelling cohorts. The length of the full spelling cohort varies with different utterances. As illustrated in Figure 1, the inclusion of only the OOV words in the subword LM training data results in a substantial improvement in performance, while only a slight degradation was incurred when the full 300k lexicon was used.
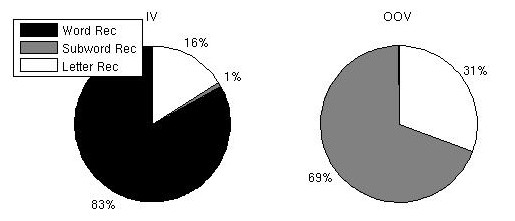
Figure 1: Accuracy of the three subword recognizers for different depths of the spelling cohort evaluated on the 1454 OOV words. Multi-Stage System We evaluate the overall performance of the multi-stage recognizer for IV and OOV words. The 55k word recognizer is used in Stage I, and the 300k LM subword recognizer is used in Stage II. The pie charts in Figure 2 describe the percentage of matching words in a cohort of size ten for the word and subword recognition stages versus words that require a spoken spelling mode (letter recognition). For the IV words, Stage I proposes the correct word among the top 10 word candidates 83% of the time. If the correct word is not in the top 10, the system reverts to the subword model in Stage II. Stage II recovers an additional 1% of the IV words. The top 10 accuracy of Stage II on the OOV words is 69%. Thus, the overall accuracy of the multi-stage recognizer is 79%, which outperforms the top 20 accuracy of the 300k isolated word recognizer as reported in Table 2.
Figure 2: Accuracy of the word and subword recognition stages for
a spelling cohort of size ten evaluated Perplexity Experiments We address the question of whether the subword-based Stage II can be used to improve upon the performance of Stage III. Stage III is based on a letter recognizer and requires a letter LM. We propose and evaluate two letter trigrams: (1) a small letter trigram built from the 100 top candidates produced by Stage II, and (2) a large letter trigram built with the 300k lexicon. The two trigrams are evaluated in terms of mean perplexity on the OOV words that failed in Stage II. Mean perplexities of 11.7 and 16 are obtained for the 100 and 300k letter trigrams respectively. The reduction in perplexity achieved by the small cohort should hopefully propagate to an improved letter error rate. An added benefit is a dramatically reduced LM size. Conclusions and Future WorkWe presented a subword model that can estimate the pronunciation and spelling of a new word. We first showed it is effective in automatically generating baseforms files required for building word recognizers. We also implemented the subword model within a multi-stage recognizer for learning new words, and reported on preliminary results, comparing it with a more traditional, isolated word recognizer. In the future, we plan to investigate in more detail the model's capability to dynamically generate and update a baseforms file. We will also implement a live system that includes a word, subword and back-up letter recognizer. We would also like to embed a subword-based OOV model within a continuous speech recognizer. This would involve more challenging issues such as the correct detection of an OOV word occurence. Acknowledgments:This research has been funded in part by a grant from ITRI and by the National Science Foundation. References:[Seneff 07] S. Seneff. "Reversible Sound-to-letter/Letter-to-sound Modeling based on Syllable Structure". To appear in Proc. NAACL-HLT, Rochester, NY , April 2007. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||