
| Research Abstracts Home | CSAIL Digital Archive | Research Activities | CSAIL Home |
![]()
|
Research
Abstracts - 2007
|
|
Exponentiated Gradient Algorithms for Log-Linear Structured PredictionAmir Globerson, Xavier Carreras, Terry Koo & Michael CollinsAbstractConditional log-linear models are a popular method for structured prediction. Efficient learning of the model parameters is therefore an important problem, and becomes a key factor when learning from very large data sets. This paper describes an exponentiated gradient (EG) algorithm for training such models. EG is applied to the convex dual of the maximum likelihood objective; this results in both sequential and parallel update algorithms, where in the sequential algorithm parameters are updated in an online fashion. We provide a convergence proof for both algorithms, which also applies to max-margin learning, simplifying previous results on EG learning of max-margin models, and leading to a tighter bound on the convergence rate for these models. Experimental results on a large scale parsing task show that the proposed algorithm converges much faster than a conjugate-gradient approach both in terms of optimization objective and test error. Overview Structured learning problems involve the prediction of objects such
as sequences or parse trees. The set of possible objects may be exponentially
large, but each object typically has rich internal structure. Several
models that implement learning in this scenario have been proposed over
the last few years [1,2]. The underlying idea in these methods is to classify
each instance 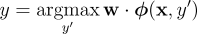 Here In both CRFs and max-margin models, the learning task involves an optimization problem which is convex, and therefore does not suffer from problems with local minima. However, finding the optimal weight vector w may still be computationally intensive, especially for very large data sets with millions of data points. In the current paper, we propose a fast and efficient algorithm for optimizing log-linear models such as CRFs. To highlight the difficulty we address, consider the common practice of optimizing the conditional log-likelihood of a CRF using conjugate gradient algorithms, or other methods such as L-BFGS [3]. Any update to the weight vector would require at least one pass over the data set, and typically more due to line-search calls. Since conjugate gradient convergence typically requires several tens of iterations if not hundreds, the above optimization scheme can turn out to be quite slow. It would seem advantageous to have an algorithm that updates the weight vector after every sample point, instead of after the entire data set. One example of such algorithms is stochastic gradient descent and its variants [4]. A different approach, which we employ here, was first suggested by Jaakkola
and Haussler [5]. It proceeds via the convex dual problem of the likelihood
maximization problem. As in the dual Support Vector Machine (SVM) problem,
the dual variables correspond to data points 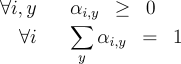 It
is thus tempting to optimize We provide a convergence proof of the algorithm, using a symmetrization of the KL divergence. Our proof is relatively simple, and applies both to the max-margin and log-linear settings. Furthermore, we show that convergence can be obtained for the max-margin case with a higher learning rate than that used in the proof of Bartlett et al. [9], giving a tighter bound on the rate of convergence. Finally, we compare our EG algorithm to a conjugate gradient optimization on a standard multiclass learning problem, and a complex natural language parsing problem. In both settings we show that EG converges much faster than conjugate gradient, both in terms of objective function and classification error. Primal and Dual Problems for Log-Linear Models Consider a supervised learning setting where we are given training data
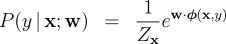 where
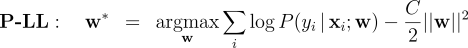 where 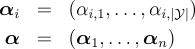 as aggregates of these duals. Let 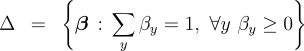 be the set of distributions over the labels for a given example. The dual problem can be expressed as 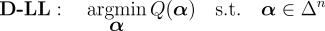 where the dual
objective function 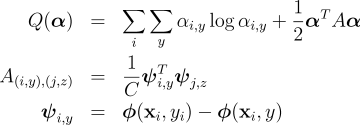 Exponentiated Gradient AlgorithmsThe method of Exponentiated Gradient (EG) updates was first introduced by Kivinen and Warmuth [8] and extended to structured learning by Bartlett et al. [9]. We briefly describe batch and online-like methods for performing EG updates on our dual optimization problem (cf. D-LL above). Given an initial distribution 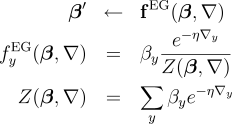 where 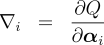 The batch
and online-like EG updates are then simple to describe. In the batch setting,
we fix 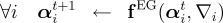 In the online
setting, we consider each 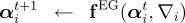 Convergence of the Batch and Online Updates We briefly sketch our proof of convergence. The analysis relies on manipulations
of three divergence measures between sets of distributions 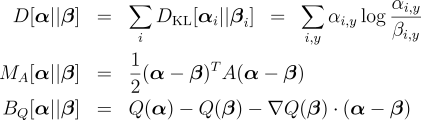 Here,
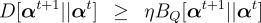 By the definition
of 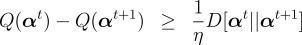 This
result allows us to deduce that both batch and online-like EG updates
will eventually converge at the optimum of the dual problem D-LL. Furthermore,
by applying an additional lemma from Kivinen and Warmuth [8], we can prove
that the batch algorithm will converge within AcknowledgementsThis work was funded by a grant from the National Science Foundation (DMS-0434222) and a grant from NTT, Agmt. Dtd. 6/21/1998. In addition, A. Globerson is supported by a postdoctoral fellowship from the Rothschild Foundation - Yad Hanadiv. References:[1] B. Taskar, C. Guestrin, and D. Koller. Max-margin markov networks. In NIPS, 2004. [2] J. Lafferty, A. McCallum, and F. Pereira. Conditional random fields: Probabilistic models for segmenting and labeling sequence data. In Proceedings of ICML, 2001. [3] Sha, F., and Pereira, F. Shallow parsing with conditional random fields. In Proceedings of HLT-NAACL, 2003. [4] Vishwanathan, S. N., Schraudolph, N. N., Schmidt, M.W., and Murphy, K. P. Accelerated training of conditional random fields with stochastic gradient methods. In Proceedings of ICML, 2006. [5] Jaakkola, T., and Haussler, D. Probabilistic kernel regression models. In Proceedings of AISTATS, 1999. [6] Platt, J. Fast training of support vector machines using sequential minimal optimization. In Advances in kernel methods - support vector learning. MIT Press, 1998. [7] Keerthi, S., Duan, K., Shevade, S., and Poo, A. N. A fast dual algorithm for kernel logistic regression. Machine Learning, 61, 151-165, 2005. [8] Kivinen, J., and Warmuth, M. Exponentiated gradient versus gradient descent for linear predictors. Information and Computation, 132, 1-63, 1997. [9] Bartlett, P., Collins, M., Taskar, B., and McAllester, D. Exponentiated gradient algorithms for large-margin structured classification. In NIPS, 2004. [10] Lebanon, G, and Lafferty, J. Boosting and maximum likelihood for exponential models. In NIPS, 2004. |
|||
|
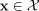 into a label
into a label 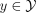 using a prediction rule
using a prediction rule 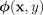 is a feature vector, and
is a feature vector, and 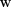 is a set of weights that
are learned from labeled data. The methods differ in their approach to
learning the weight vector. The Maximum Margin Markov Networks of Taskar
et al. [1] rely on margin maximization, while the Conditional Random Fields
(CRFs) of Lafferty et al. [2] construct a conditional log-linear model
and maximize the likelihood of the observed data. Empirically both methods
have shown promising results on complex structured labeling tasks.
is a set of weights that
are learned from labeled data. The methods differ in their approach to
learning the weight vector. The Maximum Margin Markov Networks of Taskar
et al. [1] rely on margin maximization, while the Conditional Random Fields
(CRFs) of Lafferty et al. [2] construct a conditional log-linear model
and maximize the likelihood of the observed data. Empirically both methods
have shown promising results on complex structured labeling tasks.  .
Specifically, to every point
.
Specifically, to every point 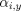 satisfying:
satisfying: 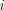 separately, much like the Sequential Minimization Optimization (SMO) algorithm
[6] often used to optimize SVMs. Several authors (e.g. Keerthi et al.
[7]) have studied such an approach, using different optimization schemes,
and ways of maintaining the distribution constraints on
separately, much like the Sequential Minimization Optimization (SMO) algorithm
[6] often used to optimize SVMs. Several authors (e.g. Keerthi et al.
[7]) have studied such an approach, using different optimization schemes,
and ways of maintaining the distribution constraints on 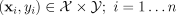 . A globally-normalized log-linear model
defines the following conditional probability distribution over labels:
. A globally-normalized log-linear model
defines the following conditional probability distribution over labels:
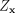 is the partition function and
is the partition function and 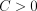 is the regularization constant. The above has an equivalent convex dual,
as derived by Lebanon & Lafferty [10]. For each example and label,
introduce the dual variable
is the regularization constant. The above has an equivalent convex dual,
as derived by Lebanon & Lafferty [10]. For each example and label,
introduce the dual variable 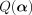 is
is 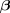 and the gradient
and the gradient
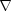 of the objective function at that point, the
EG update is defined by
of the objective function at that point, the
EG update is defined by 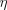 is a constant learning rate that controls how strongly the algorithm adjusts
the parameters. Note that the normalization of
is a constant learning rate that controls how strongly the algorithm adjusts
the parameters. Note that the normalization of 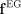 ensures that the updated parameters form a distribution. For convenience,
define
ensures that the updated parameters form a distribution. For convenience,
define 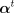 , compute all gradients
, compute all gradients 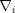 and update all of the duals simultaneously via
and update all of the duals simultaneously via 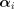 in sequence, compute
the appropriate gradient
in sequence, compute
the appropriate gradient 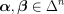 :
:
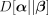 is the cumulative KL divergence between the two
sets of distributions,
is the cumulative KL divergence between the two
sets of distributions, 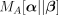 is the Mahalanobis distance
(parameterized by the matrix
is the Mahalanobis distance
(parameterized by the matrix 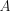 ), and
), and 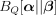 is the Bregman divergence (parameterized by a strictly convex function
is the Bregman divergence (parameterized by a strictly convex function
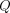 ). For both log-linear and max-margin definitions
of the dual objective
). For both log-linear and max-margin definitions
of the dual objective  of the optimum after
of the optimum after 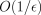 updates. Unfortunately,
this lemma does not apply to the online-like EG updating strategy, and
we have not yet proven a rate of convergence for this strategy. However,
our experiments indicate that online-like EG updates converge considerably
faster than state-of-the-art batch optimization approaches such as conjugate
gradient descent and quasi-Newton methods (e.g., L-BFGS).
updates. Unfortunately,
this lemma does not apply to the online-like EG updating strategy, and
we have not yet proven a rate of convergence for this strategy. However,
our experiments indicate that online-like EG updates converge considerably
faster than state-of-the-art batch optimization approaches such as conjugate
gradient descent and quasi-Newton methods (e.g., L-BFGS).