| Research Abstracts Home | CSAIL Digital Archive | Research Activities | CSAIL Home |
![]()
|
Research
Abstracts - 2007
|
|
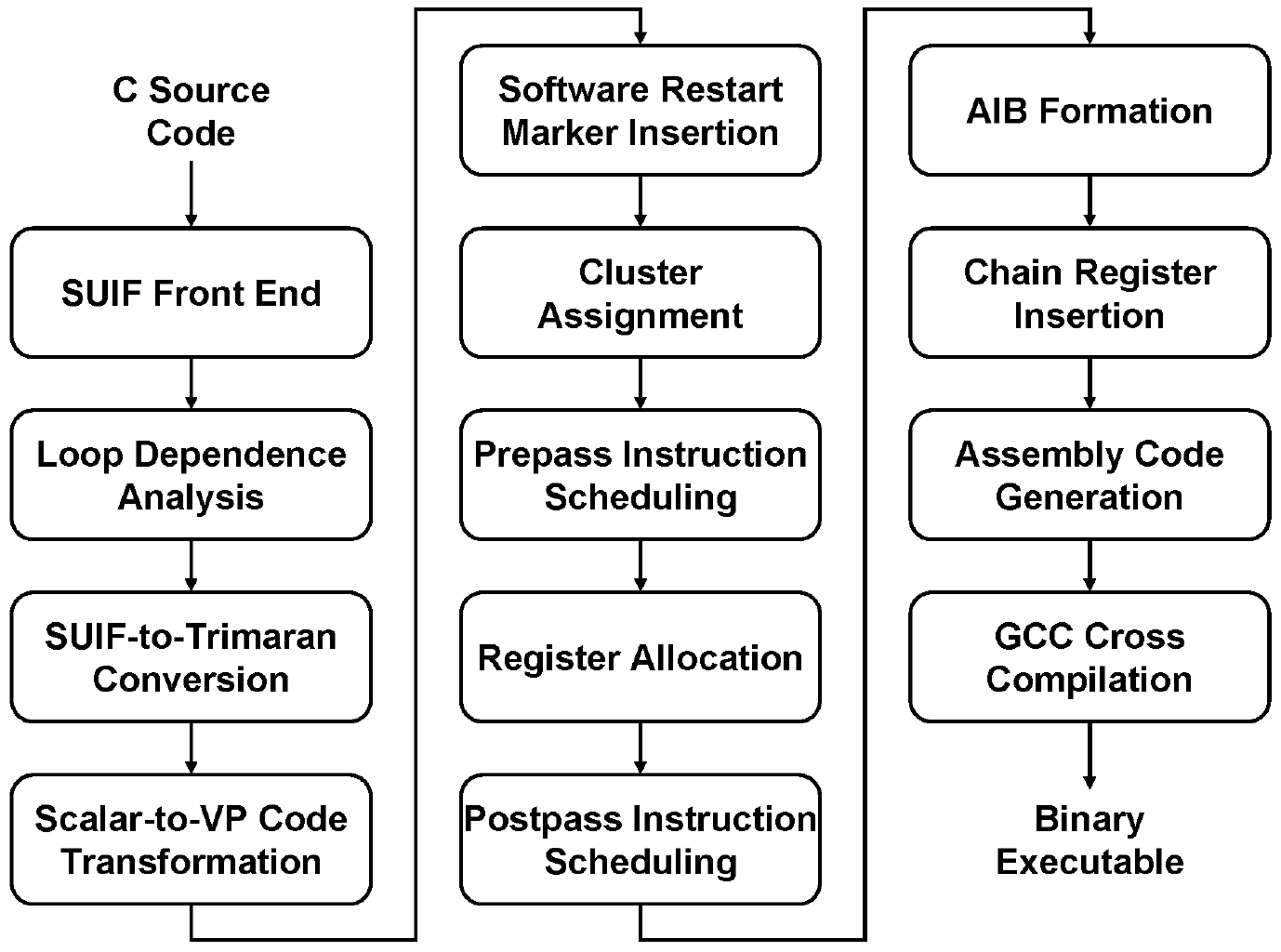
Compiling for Vector-Thread ArchitecturesMark Hampton & Krste AsanovicIntroductionThe vector-thread (VT) architectural paradigm [1] flexibly targets multiple forms of parallelism by supporting both vector and multithreaded execution models. This paradigm is designed to enable high-performance, low-power processor designs that can handle a variety of embedded applications. However, the performance-efficiency of a VT machine is dependent on the ability of the programmer to map applications to the architecture in a way that will exploit any available parallelism. Many existing embedded designs narrowly focus on one application domain, and thus it is reasonable for a programmer to create hand-coded assembly for a small set of programs. By contrast, the fact that VT architectures are intended to handle a wide range of codes increases the importance of having a compiler. In this project, we are developing a compilation infrastructure that can take advantage of the features offered by VT architectures. Our specific target system is the Scale vector-thread processor [1], which has been designed and fabricated. ApproachAlthough there are various existing compiler infrastructures that can be modified to generate Scale code, they each offer different benefits. We use multiple infrastructures, so that we can take advantage of the benefits offered by each one. Figure 1 presents a high-level depiction of the relevant parts of the compiler flow that we are currently implementing for this work. We use SUIF as our compiler front end, Trimaran as our back end, and GCC to generate the final executable. The following sections give a brief overview of the design of certain phases of the compiler.
Figure 1: Compiler Flow Loop Dependence Analysis It is important to construct an accurate dependence graph
in order to determine what parallelism can be exploited in the program.
This is a nontrivial task when considering dependences within loops, and
has been the subject of extensive research. The SUIF compiler infrastructure
contains a dependence library which we use to generate direction vectors
indicating any cross-iteration dependences. Another issue arises from
the fact that vector-thread architectures are designed for embedded systems,
which typically run programs written in C. The use of pointers in C programs
creates an aliasing problem, in which the compiler cannot determine whether
two different pointers will access the same memory location. This can
lead to an extremely conservative assumption of dependences, leading to
little or no parallelism being exploited. To handle this problem, we extended
the SUIF front end to support the Scalar-to-VP Code TransformationBy examining the dependence graph, the compiler can then parallelize the code where possible by mapping it to the VT architecture. In the VT programming model, a vector of virtual processors (VPs) is used to exploit parallelism in code, while a standard control processor handles code that cannot be mapped to virtual processors. The compiler exploits parallelism by converting conventional scalar code into VP instructions. Its first priority is to attempt to create vector-style code by searching for loops with no cross-iteration dependences. Each VP executes a single iteration of the loop under this model. The fact that branches can be mapped to VP instructions makes it possible to handle loops with internal control flow and also to perform outer loop vectorization. If no loops within a loop nest can be found without cross-iteration dependences, the compiler then attempts to perform loop vectorization by passing values between VPs using cross-VP data transfers. If this is not possible, the compiler can attempt to exploit thread-level parallelism---for example, it can have the control processor spawn free-running threads to implement a divide-and-conquer algorithm. Alternatively, the compiler can map the program to a single VP in order to take advantage of clustered execution to target any instruction-level parallelism. If none of these approaches are possible or desirable, the compiler simply allows the control processor to execute the original program. The virtual processor abstraction simplifies compilation, as the same programming model is used regardless of the type of parallelism being exploited. Software Restart Marker InsertionIf VP code has been generated, the compiler is responsible for inserting software restart markers [2], which enable support for exceptions. The purpose of software restart markers is to indicate to the operating system where to restart a process after handling an exception. For vectorized code, restart markers are inserted at the granularity of a function in the basic model. Alternatively, the compiler can take advantage of an optimization for many counted loops that inserts restart markers at the granularity of a loop iteration, reducing the amount of re-executed work after an exception. For threaded code, restart markers are inserted at the granularity of a basic block. Cluster AssignmentThe Scale processor partitions datapath resources for VPs into multiple execution clusters, which are decoupled from one another. The compiler is responsible for assigning instructions to clusters, and has several goals to consider during cluster assignment. One goal is to provide load balancing between the clusters in order to improve the utilization of the VP resources. Another goal is to avoid register spills---for example, if all register values with long lifetimes are mapped to a single cluster, that will increase register pressure as opposed to spreading those values across different clusters. Besides avoiding spills, trying to reduce the number of live register values at any given point in time provides another benefit, as the use of fewer registers per VP can enable a greater number of active VPs. Note that the instruction scheduler may change the lifetimes of certain values; one approach to account for this is to estimate the final schedule during cluster assignment. Another goal during this phase is to facilitate decoupled execution by avoiding inter-cluster register moves. Finally, it is also desirable to have acyclic dataflow between clusters when programming for Scale. Instruction SchedulingAs mentioned in the previous section, the instruction scheduler can affect the lifetime of register values, and thus has an impact on the number of register spills. There is an additional effect on the ability of the compiler to target chain registers, which are the programmer-visible inputs to the ALU. Not only can using chain registers reduce register file energy, but they can also increase the number of active VPs by reducing the number of physical registers required for each VP. To take advantage of chain registers, instructions within a dependence chain need to be scheduled together. However, it is important to do this while still attempting to minimize the critical path length for the program. Additionally, even in situations where the overall critical path is not affected, the fact that Scale supports decoupled cluster execution means that it is desirable to minimize the critical path length for each cluster. AIB FormationIn order to exploit locality in the application, VP instructions are gathered into atomic instruction blocks (AIBs). There is a limit on the number of operations for each cluster that can be placed within a single AIB, so the compiler must account for that restriction during AIB formation. For this reason, the compiler creates AIBs after register allocation; otherwise the insertion of register spill code could cause the AIB size limit to be violated. A separate reason to have AIB formation occur late in the compilation process---specifically, after instruction scheduling has been completed---is that creating AIBs before scheduling would artificially restrict the scheduler, since VP instructions cannot be moved across AIB boundaries. This could lead to a longer critical path length. Chain Register InsertionOnce AIBs are formed, the compiler can map temporary values to chain registers, which are only valid within an AIB. The use of chain registers can reduce the physical register file resources required by each VP. However, the processor allocates resources to each VP based on the highest numbered register that appears in the VP code. Thus, if the compiler simply replaces physical VP registers with chain registers, the reduction in resource requirements will be dependent on whether temporary values were previously mapped to the highest-numbered VP registers during register allocation. To avoid this issue, the compiler unbinds all previous physical VP register numbers and re-executes register allocation. During this phase, the compiler first inserts the use of chain registers where appropriate, and then allocates any remaining values to physical registers. Progress and Future WorkWe are currently able to compile traditional vectorizable loops---i.e. innermost loops with no internal control flow. We are in the midst of updating the compiler to support loops with internal control flow as well as to perform outer loop vectorization. Future work includes adding support for loops with cross-iteration dependences, as well as extending the compiler to exploit thread-level and instruction-level parallelism. Research SupportThis work was partly funded by an NTT graduate fellowship, DARPA PAC/C award F30602-00-2-0562, NSF CAREER award CCR-0093354, the Cambridge-MIT Institute, and a donation from Infineon. References:[1] Ronny Krashinsky, Christopher Batten, Mark Hampton, Steve Gerding, Brian Pharris, Jared Casper, and Krste Asanovic. The Vector-Thread Architecture. In 31st International Symposium on Computer Architecture, Munich, Germany, June 2004. [2] Mark Hampton and Krste Asanovic. Implementing Virtual Memory in a Vector Processor with Software Restart Markers. In 20th ACM International Conference on Supercomputing, Cairns, Australia, June 2006.
|
||||
|