| Research Abstracts Home | CSAIL Digital Archive | Research Activities | CSAIL Home |
![]()
|
Research
Abstracts - 2007
|
|
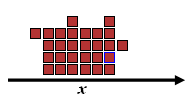
Learning of Distributed Controllers for Self-Reconfiguring Modular RobotsPaulina Varshavskaya, Leslie Pack Kaelbling & Daniela RusMotivationWe study reinforcement learning in the domain of self-reconfigurable modular robots (SRMRs): the underlying assumptions, the applicable algorithms, and the issues of partial observability, large search spaces and local optima. We propose and validate experimentally in simulation a number of techniques designed to address these and other scalability issues that arise in applying machine learning to distributed systems such as modular robots. The simulations are based on an abstract kinematic model of lattice-based self-reconfiguring modular robots. Instantiations of such robots in hardware include the Molecule, M-TRAN, and the SuperBot. We are researching probabilistic methods to automatically learn distributed controllers for SRMRs, such as the locomotion rules found in [2]. Each module of the robot has its own local observation space, can act independently of others, and is affected by other modules' behavior. Globally coherent and cooperative behavior should emerge from the local controllers learned by individual modules. ApproachIn lattice-based SRMRs, robot motion is achieved by individual modules changing their lattice positions through disconnecting and reconnecting at adjacent sites with primitive motions executed in between. The whole robot then moves like a discretized liquid, conforming to the terrain. A snapshot of a two-dimensional simulator for lattice-based locomotion by self-reconfiguration is shown in figure 1.
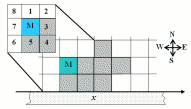
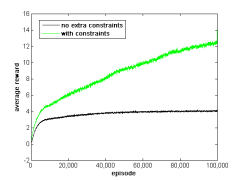
Each module is a reinforcement learning agent, observing a local neighborhood of adjacent modules and executing one of possible eight movements (plus a NOP) at every discrete timestep. The distributed task results in partial observability from each agent's point of view. We model the problem as a Partially Observable Markov Decision Process (POMDP) and use a gradient-ascent algorithm in the space of policies [4] for learning. Information and ConstraintsIn what ways can we make learning faster, more robust and amenable to online application? Giving scaffolding to the learning agents in the form of policy representation, structured experience and additional information affects learning. Our position is that with enough structure modular robots can run learning algorithms to both automate the generation of distributed controllers, and adapt to the changing environment and deliver on the self-organization promise with less interference from human designers, programmers and operators. Figure 3 demonstrates one example of how additional constraints affect learning. Where a fully distributed implementation of the gradient ascent algorithm does not achieve any improvement of rewards after tens of thousands of learning episodes, constraining the search to only legal actions in any local configuration results in a dramatic improvement and much greater rewards.
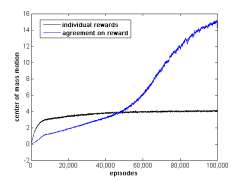
Learning with AgreementThe more experience an agent gets the better it is going to learn. In a physically coupled distributed system such as a modular robot, the learning modules that are positioned on the perimeter of the robot have the most freedom of movement. Therefore, they can attempt more actions and get more experience essential for learning. But those modules which are "stuck" on the inside have no way of exploring their actions and the environment. They gather almost no experience and cannot learn a reasonable policy in the allotted time. They need a mechanism for sharing in other agents' experience. We study tasks in which individual modules are all expected to learn a similar policy. Therefore they can share any and all information and experience they gather: observations, actions, rewards, current parameter values. There is a trade-off between exploration and information sharing, as well as a natural limit in the channel bandwidth. One way of sharing information is by agreement algorithms [1,5] among modules, where individual agents communicate and average their current values for reward and parameter updates. Figure 4 shows an example of dramatically improved learning through agreement on rewards at the end of each episode. FutureWe are looking into applying the techniques developed for locomotion in lattice-based SRMRs also to chain and truss-based robots such as MultiShady [3], as well as to assembly and shape-maintenance tasks. In addition, for learning algorithms to be applicable at the module level at runtime on physical robotic systems, we need to look at minimizing the number of learned parameters. AcknowledgementsThis research is sponsored by Boeing Corporation. References:[1] Dimitri P. Bertsekas and John N. Tsitsiklis. Parallel and Distributed Computation: Numerical Methods, Athena Scientific, 1997. [2] Zack Butler, Keith Kotay, Daniela Rus, and Kohji Tomita. Cellular automata for decentralized control of self-reconfigurable robots. In The Proceedings of the IEEE International Conference on Robotics and Automation, 2002. [3] Carrick Detweiler, Marsette Vona, Keith Kotay, Daniela Rus. Hierarchical Control for Self-assembling Mobile Trusses with Passive and Active Links. IEEE Intl. Conf. on Robotics and Automation, 2006. [4] Leonid Peshkin. Reinforcement Learning by Policy Search. PhD thesis, Brown University, November 2001. [5] John N. Tsitsiklis, Dimitri P. Bertsekas, and Michael Athans. Distributed Aynchronous Deterministic and Stochastic Gradient Optimization Algorithms. In IEEE Transactions on Automatic Control, vol. AC-31, no. 9, September 1986. [6] Paulina Varshavskaya, Leslie Pack Kaelbling, and Daniela Rus. Learning Distributed Control for Modular Robots. In The Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems, Sendai, Japan, October 2004. [7] Paulina Varshavskaya, Leslie Pack Kaelibling, and Daniela Rus. Automated Design of Adaptive Controllers for Modular Robots Using Reinforcement Learning. Submitted to IJRR Special Issue on Self-Reconfigurable Modular Robots September 2007. |
|||||||||||
|