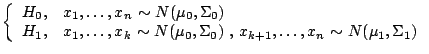| Research Abstracts Home | CSAIL Digital Archive | Research Activities | CSAIL Home |
![]()
|
Research
Abstracts - 2007
|
|
Audio Segmentation and Classification using Extended Baum-Welch TransformationsTara N. Sainath & Victor ZueIntroductionAudio steams, such as broadcast news or meeting recordings, contain audio from a wide variety of sources, including speech, music, coughing, laughter, etc. Segmentation and classification have become important tools to describe an audio scene that contains a variety of acoustic events. In our work, we use the Extended Baum-Welch (EBW) transformations [1] to develop novel segmentation and classification approaches. Specifically, in [2] we show that our segmentation algorithm offers improvements over two baseline methods, namely the Bayesian Information Criterion (BIC) [3] and Cumulative Sum (CUSUM) [4] methods. In addition, in [5] we use these transformations to develop a novel audio classification algorithm, which is able to outperform both the Gaussian Mixture Model (GMM) Likelihood and Support Vector Machine (SVM) classification techniques. Extended Baum-Welch TransformationsThe EBW procedure involves continuous transformations that can be described
as follows. Assume that data
Here
Segmentation via EBW TransformationsThe goal of a segmentation algorithm is to divide an audio segment into
homogeneous regions. Given observations
Using the above two hypothesis, our segmentation criterion becomes:
Intuitively this means that we detect a change at point Classification via EBW TransformationsGiven a set of class models
We can also use the formula given in the right side of Equation 1
for classification. Here D is a constant chosen in the EBW re-estimation
formulas
In [6], Valtchev et.al shows that using a phone-specific
D instead of a global value allows for better re-estimated phoneme
models using the EBW transformations. Similarly, in [5] we show that different classes prefer a specific
D value when estimating the updated model ExperimentsWe perform segmentation experiments using the Computers in the Human Interaction Loop (CHIL) Isolated Acoustic Event data set [7]. This data set contains isolated acoustic events from 15 different classes, including knocks, doors opening/closing, applause, laughter, etc. The set is divided into 3 sessions, with 10 participants per session. In total, there are over 6000 change points per session, which are annotated manually by the University Polytechnic of Catalonia (UPC). Our segmentation experiments use 19 dimension Mel-Frequency Cepstral Coefficients (MFCCs) while our classification experiments compare both MFCCs and MFCCs plus perceptual features, including short-time energy, zero crossing rate, subband energy spectral flux. ResultsTo evaluate our segmentation algorithms, we compute the F-measure, which measures the tradeoff between precision and recall. Table 1 shows the evaluation metric scores for the CUSUM, BIC and EBW algorithms, the latter with and without the refinement and merge stages. Note that the BIC implementation discussed here also includes a similar refinement and merge stage. One reason that EBW outperforms CUSUM is that each term T in EBWSeg captures the difference between the likelihood of a data given the initial model and the likelihood with a model estimated from the entire data sequence, while CUSUM just calculates the former. The EBW with the refinement and merge stage is able to outperform BIC. One theory is that the objective of an EBW-hypothesized test is to minimize detection time for a given false alarm rate, which closely matches the goal of segmentation.
Table 2 shows the average total execution time on 5.5 hours of data for the three methods. EBW performs more than 5 times faster than BIC and 3 times faster than CUSUM. At each new hypothesized boundary within an observation sequence, BIC re-estimates model parameters. However, EBW and CUSUM only estimate model parameters once within an observation sequence. Yet, CUSUM computes the inverse covariance and determinant in the likelihood formulation, and is thus slower than EBW which computes variances.
Table 3 shows the classification results for the baseline and EBW classifiers using both MFCC and MFCC+Perceptual features. The EBW-T and GMM offer comparable performance. However, when we are able to control how fast we update our model using EBW-F classifier, we outperform both EBW-T and GMM for both feature sets. Again we see that using EBW to re-estimate trained models with the current data sequence being classified offers improvements over the standard GMM likelihood approach. As expected, the SVM outperforms the GMM and EBW models on all feature sets. However, transforming the feature space using the scores of EBW-F classifiers for different D offers improvements over the baseline SVM. Ongoing ResearchAudio segmentation and classification are often used as preprocessing step in speech recognition to separate an audio stream into homogeneous regions where each region can be handled in a different manner. We are currently looking to apply these EBW techniques for multilevel preprocessing, include speech/non-speech and broad phonetic class detection, to improve robustness of speech recognition systems. AcknowledgementsThis reseach is sponsored by the T-Party Project, a joint research program between MIT and Quanta Computer Inc., Taiwan. We would also like to thank Dimitri Kanevsky and Giridharan Iyengar of IBM for their contributions and inputs to this work. References[1] D. Kanevsky. Extended Baum Transformations for General Functions. In Proc. ICASSP, 2004. [2] T.N. Sainath, D. Kanevsky, and G. Iyengar. Unsupervised Audio Segmentation using EBW Transformations. To Appear in Proc. ICASSP, 2007. [3] S. Chen and P. Gopalakrishnan. Speaker, Environment and Channel Change Detection and Clustering via The Bayesian Information Criterion. In Proc. Broadcast News Trans. and Under. Workshop , February 1998, pp. 127132. [4] M. Omar, U. Chauduri, and G. Ramaswamy. Blind Change Detection for Audio Segmentation. In Proc. ICASSP, 2005. [5] T.N. Sainath, V. Zue, and D. Kanevsky. Audio Classification using EBW Transformations. Submitted to ICSLP, 2007. [6] V. Valtchev, J.J. Odell, P.C. Woodland, and S.J. Young. MMIE Training of Large Vocabulary Speech Recognition Systems. In Speech Communication,, vol. 22, no. 303-314, 1997. [7] A. Waibel et al., CHIL: Computers in the Human Interaction Loop. In WIAMIS, 2004. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||