
Feature-based Pronunciation Modeling: A Progress Report
Karen Livescu & James Glass
Motivation
When speaking in a conversational style, people often pronounce words in ways that differ greatly from the dictionary pronunciations. The word probably is often pronounced "probly" or even "prawly"; everybody may be pronounced "eruwhy" and several as "serval". Such unexpected pronunciations can degrade the performance of automatic speech recognizers, which typically rely on phonetic dictionaries that allow minimal variation from citation forms. This issue is most commonly dealt with by either (1) adding phonetic pronunciations to the recognition dictionary, or (2) leaving the dictionary as is but using higher-variance models of individual speech sounds, effectively treating the sound [w] as a "noisy" version of [b] in the example everybody --> "eruwhy".
In many cases, however, such pronunciations can be explained in an elegant and parsimonious way by treating words not as a single stream of phonemes but as multiple, semi-independent, streams of linguistic features. The feature streams can represent, for example, the positions of speech articulators such as the lips and tongue. From this viewpoint, probably --> "prawly" is the result of incomplete closing and opening of the lips, and several --> "serval" can be caused by the tongue moving faster than the lips. The asynchrony between the features is constrained, however; for example, pronunciations that are more faithful to the dictionary may be more probable.
Method
We implement such models of pronunciation using dynamic Bayesian networks (DBNs), which explicitly represent the factorization of a single-stream process into multiple underlying streams with some dependencies. The task of such a model is, given a word or string of words, to generate all of the possible sets of feature trajectories and their probabilities. The parameters of the model include the probabilities of substituting a given feature value for another (e.g. closed lips --> narrow lips); the probabilities of transitioning from one state in a given feature stream to the next; and the probabilities of asynchrony between the streams. We initialize the parameters manually and estimate their maximum-likelihood values from training data. An initial model, using articulatory features such as those described above, has been presented in [1]. More recently, we have modified it to allow for learning the probabilities of feature asynchrony from data [2]; below we report on experiments conducted with this model.
Experiments
To test this pronunciation model in isolation from the other parts of a speech recognizer, we use a simulation experiment: We assume that we are given the ground truth time-aligned feature values F for a word---essentially assuming that we have perfect feature classifiers---and we compute, for every word w in a vocabulary of size N, the probability of that word given the feature values, P(w|F). We measure performance by observing the rank given to the correct word (1 if it received the highest probability, N if it received the lowest probability). We are interested both in how often the correct word was top-ranked and in the overall distribution of the ranks.
We have conducted this type of experiment on a set of conversations manually transcribed at the detailed phonetic level. These manual transcriptions are converted to "ground truth" articulatory feature values. The table below shows the performance of several models on a set of 236 words. Performance is shown in terms of error rate, the percentage of non-top-ranked words, and failure rate, the percentage of words for which the given feature trajectories are not an allowed pronunciation of the correct word. Using a basic phonetic dictionary or augmenting it with phonetically-based rules, most of the pronunciations in our set are disallowed. The articulatory feature-based models have a much lower failure rate, corresponding to the much larger number of variants they allow. By allowing many more pronunciations, we risk increasing the confusability between words and therefore increasing the error rate; however, as we have found in these experiments, the feature-based models achieve lower error rates than the phone-based ones.
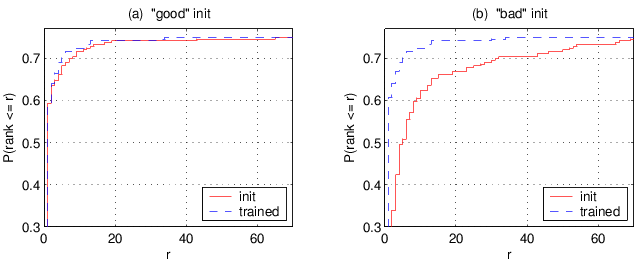
One of the goals of this set of experiments is to compare different training conditions. We train the feature-based models on approximately 2900 words using two different initializations: a "good" one in which we set the initial parameters to values that seem plausible from a linguistic perspective; and a "bad" one, in which we only set to zero those probabilities corresponding to (what we believe are) impossible pronunciations, and initialized the non-zero probabilities to uniform values. In the "good initialization" condition, performance is the same before and after training, indicating that the model is not sensitive to the exact parameter values. The "bad" initialization (line (b) in the table) indeed gives a very high error rate. However, after training, the performance of the models with the two initializations is virtually identical. In other words, the training of this model is not sensitive to initial parameter values, up to the setting of the zero probabilities.
| model | error rate (%) | failure rate (%) |
|---|---|---|
| dictionary only | 64.8 | 62.3 |
| dict + rules | 63.1 | 58.5 |
| (a) feature-based, "good" init | 40.7 | 24.6 |
| (a) + training | 40.7 | 24.6 |
| (b) feature-based, "bad" init | 76.3 | 24.6 |
| (b) + training | 37.3 | 24.6 |
For a more detailed understanding of the model's behavior, we also look at the distribution of the correct word's rank over the test set. The cumulative distributions obtained with the two initializations are shown in the figures below. Although training does not change the error rate of the model with the "good" initialization, it does improve the rank distribution, which may be important when recognizing multi-word sentences rather than isolated words.
Ongoing/Future Work
This approach opens up a number of interesting issues, such as the set of articulatory features and their quantization, the constraints on their joint evolution, and the relationship between the underlying articulatory processes and the observed speech signal. Thus far we have placed more emphasis on the first two of these. Recently, this type of model was used for rescoring recognizer outputs as part of a project at the 2004 Johns Hopkins Summer Workshop on Language Engineering [3], and we are currently incorporating it into a complete recognizer. We have also begun applying such models to the problems of lip-reading and audio-visual speech recognition (see [4] and references therein).
Acknowledgment
This research was supported in part by NSF grant IIS-0415865.
References
[1] Karen Livescu and James Glass. Feature-based pronunciation modeling for speech recognition. In Proc. Human Language Technology Conference/North American chapter of the Association for Computational Linguistics Annual Meeting, Boston, May 2004.
[2] Karen Livescu and James Glass. Feature-based pronunciation modeling with trainable asynchrony probabilities. In Proc. International Conference on Spoken Language Processing, Jeju, South Korea, October 2004.
[3] Mark Hasegawa-Johnson et al. Landmark-based speech recognition: Report of the 2004 Johns Hopkins Summer Workshop. In Proc. International Conference on Acoustics, Speech, and Signal Processing, Philadelphia, March 2005.
[4] Kate Saenko, Karen Livescu, James Glass, and Trevor Darrell. Articulatory Feature Based Visual Speech Recognition. CSAIL Research Abstract, 2005.
The Stata Center, Building 32 - 32 Vassar Street - Cambridge, MA 02139 - USA tel:+1-617-253-0073 - publications@csail.mit.edu (Note: On July 1, 2003, the AI Lab and LCS merged to form CSAIL.) |