
Articulatory Feature Based Visual Speech Recognition
Kate Saenko, Karen Livescu, James Glass & Trevor Darrell
Introduction
The goal of this work is to develop a visual speech recognition system that models visual speech in terms of the underlying articulatory processes. Traditionally, visual speech is modeled as a single stream of contiguous units, each corresponding to a hidden phonetic state. These units are called visemes, and are defined by clustering together several visually similar phonemes. However, from the point of view of speech production, each sound can also be described by a unique combination of several underlying articulator states, or articulatory features (AFs), such as:
- the presence or absence of voicing,
- the position of the tongue,
- the opening between the lips,
- the rounding of the lips,
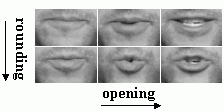
and so on. For example, the figure above shows different degrees of lip opening and rounding. While conventional speech models make the simplifying assumption that a word can be broken up into a single sequence of phonemes (visemes), the articulatory feature model views a word as multiple (not necessarily synchronous) sequences of articulator states. The advantage of the articulatory approach is a more flexible architecture in terms of both context and pronunciation modeling. For example, it can explain such effects as when the tongue gets ahead of the lips and results in a different pronunciation of a word. Similar feature-based models have been used in modeling spontaneous acoustic speech [3]; in this work, we apply the multi-stream articulatory feature approach to the visual domain [1].
Method
Since we are dealing with just the visual modality, we are limited to modeling the visible articulators. As a start, we are using features associated with the lips, since they are always visible in the image: lip opening (closed, narrow, medium and wide), lip rounding (rounded, unrounded) and labio-dental (labio-dental, not labio-dental). This ignores other articulators that might be distinguishable from the video, such as the tongue and teeth; we plan to incorporate these in the future.
We implement our system as a dynamic Bayesian network (based on [4]), where articulatory features are the hidden states underlying the surface visual observations. A preprocessing step, which involves face and lip region tracking, extracts the observed feature vectors from the input image sequence. Then, for each time step, the observation is mapped to the likelihood of a particular articulatory feature value using a support vector machine (SVM) classifier. Note that this differs from the standard method of modeling DBN observation likelihoods with Gaussian mixture models (GMMs). We chose to use SVMs instead of GMMs because we found them to have better classification performance in preliminary tests.
The figure below shows three time frames of our DBN. Conditioned on the identity of the word, it essentially consists of three parallel HMMs, one per AF, where the joint evolution of the HMM states is constrained by synchrony requirements (the orange nodes). Specifically, these requirements state that sets of trajectories that are more "synchronous" are more probable than less "synchronous" ones. Note that the standard formulation of SVM classification produces a hard decision (the class label), which is based on the thresholded decision function value. We use the decision value directly, first converting it to a posterior probability, and then dividing it by the prior probability of the feature value to obtain a (scaled) likelihood. These likelihoods are then incorporated into the Bayesian network using the mechanism of soft evidence (the blue nodes).
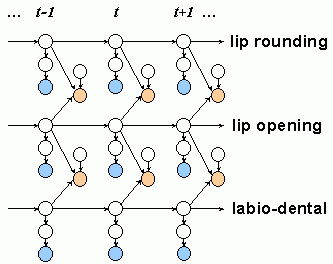
To perform recognition with this model, we use standard DBN inference algorithms to find the most likely sequence of values for a given word. The parameters of the distributions in the DBN, including the probabilities of different degrees of asynchrony between streams, can be learned using standard maximum-likelihood parameter estimation. In the experiments described below, however, only a small data set was used and the DBN parameters were set manually, although the SVM parameters were trained from data.
Experiments
We have conducted pilot experiments to investigate several questions that arise in using the proposed feature-based system. In order to facilitate quick experimentation, these initial experiments focus on an isolated-word recognition task and use only a small data set. In particular, the dataset consists of twenty utterances from a single speaker in the AVTIMIT database [2]. Training labels for the SVMs were obtained using two methods: a) using an acoustic recognizer to transcribe the audio with phonemes, which were then converted to AF labels using a table; and b) manually transcribing the images with AF labels.
First, we would like to compare the effects of using a feature-based versus a viseme-based model in our recognizer. A viseme-based pronunciation model is a special case of our DBN, in which the features are constrained to be completely synchronous. Using viseme classifiers with a viseme-based pronunciation model is essentially the conventional viseme-based HMM that is used in most VSR systems. Also, since we do not have ground truth articulatory feature labels, we investigate how sensitive the system is to the quality of the training labels in terms of both feature classification and word recognition. Finally, to show how well the system could be expected to perform if we had ideal classifiers, we replace the SVM soft evidence with likelihoods derived from our manual transcriptions. In this oracle test, we assign a very high likelihood to feature values matching the transcriptions and the remaining likelihood to the incorrect feature values.
The table below shows the per-frame accuracies of the three articulatory feature classifiers, trained either on audio transcription labels or on manual labels, as well as the accuracy of the viseme classifier. It is clear that having manual labels significantly improves the acuracy of the feature classifiers.
| lip opening | lip rounding | labio-dental | viseme | ||
|---|---|---|---|---|---|
| SVMs trained on audio transcription labels | 44% | 63% | 50% | 33% | |
| SVMs trained on manual labels | 59% | 78% | 87% | - | |
| Chance performance | 25% | 50% | 50% | 17% |
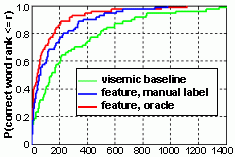
The plot below compares the performance of different word recognizers. The task of isolated-word lipreading with a 1793-word vocabulary is extremely difficult, so that the absolute lipreading word recognition rate is always near 0 and thus not meaningful. We instead measure performance using the rank of the correct word. The cumulative distribution function (CDF) of the correct word rank for the recognizer using a viseme classifier and a viseme-based pronunciation model is shown in green. The closer the distribution is to the top left corner, the better the performance. We can see from the plot that both feature-based models, shown in blue and red (oracle), outperform the viseme baseline.
Future Plans
We plan to continue testing this model on more data and in comparison with more realistic viseme-based baselines. We are also interested in applying this model to the problem of audio-visual fusion. Most state-of-the-art audio-visual speech recognizers model the asynchrony between the audio and visual streams. However, the fusion is done at the level of the phoneme/viseme. We believe that the feature is a more natural level for audio-visual fusion. The structure we have used can be naturally extended to perform this type of fusion; all that is required is a complementary set of classifiers for the acoustically-salient features, such as voicing and nasality, and the corresponding additional variables in the DBN.
Acknowledgments
This research was supported by DARPA under SRI sub-contract No. 03-000215.
References:
[1] Kate Saenko, Karen Livescu, James Glass, and Trevor Darrell. Production Domain Modeling of Pronunciation for Visual Speech Recognition. In Proceedings of the International Conference on Acoustics, Speech, and Signal Processing, pp. 473-476, Philadelphia, March 1005.
[2] Timothy J. Hazen, Kate Saenko, Chia-Hao La and James Glass. A segment-based audio-visual speech recognizer: Data collection, development and initial experiments. In Proceedings of the International Conference on Multimodal Interfaces, pp. 235-242, State College, Pennsylvania, October 2004.
[3] Karen Livescu and James Glass. Feature-based Pronunciation Modeling: A Progress Report. CSAIL Research Abstracts, 2005.
[4] Karen Livescu and James Glass. Feature-based pronunciation modeling for speech recognition. In Proceedings of the Human Language Technology Conference/North American chapter of the Association for Computational Linguistics Annual Meeting, Boston, May 2004.
The Stata Center, Building 32 - 32 Vassar Street - Cambridge, MA 02139 - USA tel:+1-617-253-0073 - publications@csail.mit.edu (Note: On July 1, 2003, the AI Lab and LCS merged to form CSAIL.) |