| Technical Reports | Work Products | Research Abstracts | Historical Collections |
![]()
|
Research
Abstracts - 2006
|
|
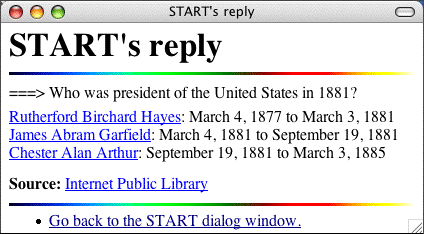
Information Access Using Natural LanguageBoris Katz, Gary Borchardt, Sue Felshin & Gregory MartonThe ProblemWith recent advances in computer and Internet technology, people have access to more information than ever before. As the amount of information grows, so does the problem of finding what one is looking for. MotivationA natural language system is the most intuitive interface for humans seeking information. It can produce high-precision responses which decrease search time and increase productivity. Such a system requires less training, is accessible to a wider audience, and can be deployed in a shorter period of time; it can serve as a rigorous testbed for research in language understanding. Regrettably, current natural language processing techniques are not yet capable of performing unrestricted full-text understanding. Furthermore, not all information is text; sounds, images, video, and other multimedia can all be valuable sources of knowledge. In response to this situation, we believe the best approach is to focus on teaching computers where and how to find the right pieces of knowledge: that is, we need to give our systems knowledge about knowledge. ApproachTo address the problem of information overload in today's world, we have developed START, a natural language question answering system that provides users with high-precision multimedia information access through the use of natural language annotations. To address the difficulty of accessing large amounts of heterogeneous data, we have developed Omnibase, which assists START by providing uniform access to structured and semistructured Web resources. Our ultimate goal is to develop a computer system that acts like a “smart reference librarian.” START has been used by researchers at MIT and other universities and research laboratories to construct and query knowledge bases using English. To date, START can access a broad range of information in a number of topic areas, including cities, countries, weather reports, U.S. colleges and universities, U.S. presidents, movies, and more. Figure 1 shows a screenshot of START responding to a user question. To give our systems knowledge about knowledge, we use natural language annotations [1], which are machine-parseable sentences and phrases that describe the content of various information segments. They serve as metadata describing the types of questions that a particular piece of knowledge is capable of answering. An important feature of the annotation concept is that any information segment can be annotated: not only text, but also images, multimedia, and even procedures. The ability to respond to natural language questions with textual and multimedia content crucially depends on natural language annotations. The knowledge coverage of the START system is thus dependent on the amount of annotated material. To increase the effectiveness of our technology, we have adapted natural language annotations to work with structured and semistructured data through Omnibase [2], which allows heterogeneous resources on the World Wide Web to be treated in a consistent manner for purposes of retrieving properties of objects.
Despite the effectiveness of START and Omnibase in solving user information needs, there are still several major unsolved challenges.
To address these challenges, we have pursued many different solutions. The following abstracts in this volume describe each of these technologies in greater detail:
Research SupportThis work is supported in part by the Advanced Research and Development Activity as part of the AQUAINT Phase II research program. References:[1] Boris Katz. Annotating the World Wide Web Using Natural Language. In Proceedings of the 5th RIAO Conference on Computer Assisted Information Searching on the Internet (RIAO '97), Montreal, Canada, 1997. [2] Boris Katz, Sue Felshin, Deniz Yuret, Ali Ibrahim, Jimmy Lin, Gregory Marton, Alton Jerome McFarland, and Baris Temelkuran. Omnibase: Uniform Access to Heterogeneous Data for Question Answering. In Proc. of the 7th Int. Workshop on Applications of Natural Language to Information Systems (NLDB '02), Stockholm, Sweden, June 2002. |
|||||
|