| Technical Reports | Work Products | Research Abstracts | Historical Collections |
![]()
|
Research
Abstracts - 2006
|
|
Syntactic Decomposition for Complex Question AnsweringBoris Katz, Sue Felshin & Gary BorchardtThe ProblemCurrent question answering systems have demonstrated an ability to answer simple factoid and list questions such as “Who is the current prime minister of Italy?” and “In which countries is Spanish spoken?” However, many questions are more complex. For example, the question “When was the current prime minister of Italy elected?” requires a question answering system to determine not only who the prime minister of Italy is, but also when that person was elected. We are developing technology that will make it possible to decompose a complex question into simpler questions, each of which can be answered individually; the individual responses will then be combined into an answer to the original complex question. MotivationBy using syntactic means to decompose complex questions into simpler factoid and list questions, we can leverage our existing question answering machinery and answer complex queries at relatively low cost. See Figure 1 for an example of syntactic decomposition as implemented in our START question answering system.
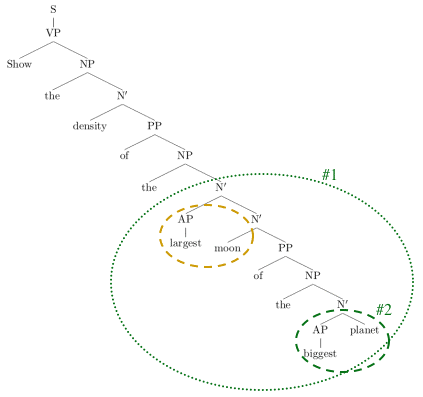
Related WorkSTART's ternary expressions (subject–relation–object triples) can richly and efficiently represent the user's questions, as well as natural language annotations used to describe content, and therefore lend themselves well to syntactic decomposition of complex questions (see [1] [2] and related abstracts). For further information on syntactic decomposition, see [3]. ApproachWe may approach syntactic decomposition from two directions: first, syntax, and second, meta-knowledge about the contents of available information resources. Syntax informs us of which decompositions of a question are legal, and meta-knowledge about information resources can guide the system to answerable subquestions when many legal decompositions exist. Legal syntactic decompositions are proper branches of the parse tree. Figure 2 shows two proper and one improper branch. The structure of a sentence, of course, is related to the meaning conveyed by the sentence. For example, if asked "Who was the third Republican president?", we must first find the Republican presidents (Lincoln, Grant, Hayes, Garfield, ...) and then find the third one, rather than first finding the third president (John Adams), and then seeing if he was a Republican. In many cases, a low, proper branch that captures a single relation should be resolved first. However, in some cases, annotations in the knowledge base may indicate that it is possible to resolve a higher (i.e., larger), proper branch, that captures several relations, in a single step. Also, in some cases, lexico-semantic information may indicate that a relation that is higher in the parse tree and is captured by an improper branch can and should be resolved first, for reasons of efficiency.
Future WorkWe plan to examine more closely the relation between syntax and legal decompositions, paying particular attention to the validity of resolving a relation before another relation which is lower in the parse tree. We also plan to investigate more completely the manner in which knowledge base contents (as indicated by available annotations) can influence the decomposition of complex questions into subquestions and the order of evaluation for those subquestions. Research SupportThis work is supported in part by the Advanced Research and Development Activity as part of the AQUAINT Phase II research program. References:[1] Boris Katz. Using English for Indexing and Retrieving. In Artificial Intelligence at MIT: Expanding Frontiers, v. 1; Cambridge, MA, 1990. [2] Boris Katz. Annotating the World Wide Web Using Natural Language. In Proceedings of the 5th RIAO Conference on Computer Assisted Information Searching on the Internet (RIAO '97), Montreal, Canada, 1997. [3] Boris Katz, Gary Borchardt, and Sue Felshin. Syntactic and Semantic Decomposition Strategies for Question Answering from Multiple Resources. In Proceedings of the AAAI 2005 Workshop on Inference for Textual Question Answering, pp. 35–41, 2005. |
|||||
|