| Technical Reports | Work Products | Research Abstracts | Historical Collections |
![]()
|
Research
Abstracts - 2006
|
|
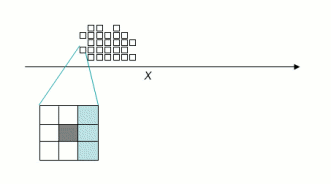
On Reducing Search Space for Learning in Modular RobotsPaulina Varshavskaya, Leslie P. Kaelbling & Daniela RusMotivationWe are researching probabilistic methods to automatically learn distributed controllers for modular self-reconfiguring robots, such as in [1]. Each module of the robot has its own local observation space, can act independently of others, and is affected by other modules' behavior. Globally coherent and cooperative behavior should emerge from the local controllers learned by individual modules. Specifically, we are interested in reducing the large search spaces associated with this learning problem. Certain properties of distributed modular robots give rise to structure in the learning space, which can be explored for faster convergence of the learning algorithm. ApproachWe start by casting the problem as a distributed Partially Observable Markov Decision Process (POMDP), and notice that this approach suffers from lack of structure in a combinatorially explosive domain. We can mitigate this problem by manipulating the size of the modular robot, i.e., the number of learning agents in the picture.
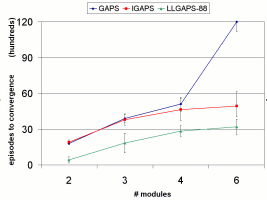
However, for learning to be applicable to real robots in the physical world, adaptation needs to happen fast relative to the agent's lifetime. Therefore, we are researching ways to improve convergence times drastically by learning with structured features defined over the raw observation-action space. ProgressWe use the Gradient Ascent in Policy Space (GAPS) [2] learning algorithm. The objective difficulty of even the simplest scenario of motion in a straight line on an even surface without obstacles in 2D was analyzed in [3]. By attempting to solve such a toy problem with a state of the art reinforcement learning technique, we discover the limitations of unstructured search in our domain. We find, however, that it is possible to leverage off the modular nature of the locomotion problem in order to improve the convergence rate. If the robot starts with only two modules, and more are added incrementally, this effectively reduces the problem state-space. With only two modules, given the physical coupling between them, there are only four states to explore. Adding one other module, only another fourteen possible observations are added and so forth. The problem becomes more manageable. Therefore, we implemented the Incremental GAPS (IGAPS) algorithm, which takes as input the policy parameters to which a previous running instance of IGAPS with fewer modules has converged. Figure 2 shows the convergence rates of the learning algorithms. We observe a dramatic decrease in convergence time for IGAPS.
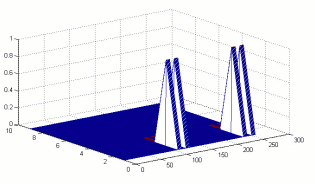
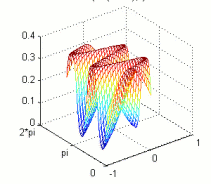
However, the incremental algorithm is limited to the set of problems where it is beneficial. Perhaps a more universal approach is to structure the observation-action space according to simple salient features, then learn in the new feature space. For example, in the above locomotion task, the local features for each module could consist of empty lines and corners in the immediate neighborhood, as well as "full" lines and corners, where a neighbor is present in each cell, plus one of the nine possible actions. Figure 3 shows the response field of one such feature. The algorithm is modified to use a log-linear model with features thus defined and is called Log-Linear GAPS (LLGAPS). Figure 2 demonstrates that, even without incremental addition of modules, LLGAPS with 88 features converges dramatically faster than both GAPS and IGAPS. ChallengesThe incremental algorithm is essentially naive structuring of a given problem. Its success depends entirely on the nature of the task the robot is to perform. An important challenge of reducing the learning space of our problem is to find a principled and perhaps automatic way to find the space strucutre, e.g., by generating features. Another issue is that physical robots operate in continuous-valued observation (sensory) and action (motor) spaces, which we have not accounted for. We are currently working to address both these issues. One promising approach is to define continuous-valued features over the observation-action space by using Fourier decomposition and Gaussian action selection. The policy we are learning is treated as a periodic function with period the size of observation space, and with maximum amplitude the size of action space. The response field of a single feature is obtained by "sweeping" a Gaussian density function along a sine or cosine base, as shown in Figure 4. FutureIn the future, lab robots such as MultiShady [4] could provide an interesting platform for our learning algorithms. The system should demonstrate increased performance at a task through reconfiguration. As an example, the modules could learn to assemble small cluster structures which are able to walk. Then the clusters could learn to reconfigure into building blocks for a larger assembly, which would also have a capability to examine itself for damage and repair broken parts by self-reconfiguration. Such demonstrated adaptability will be a great step towards fulfilling the promise of self-organizing modular robots. References:[1] Zack Butler, Keith Kotay, Daniela Rus, and Kohji Tomita. Cellular automata for decentralized control of self-reconfigurable robots. In The Proceedings of the IEEE International Conference on Robotics and Automation, 2002. [2] Leonid Peshkin. Reinforcement Learning by Policy Search. PhD thesis, Brown University, November 2001. [3] Paulina Varshavskaya, Leslie P. Kaelbling, and Daniela Rus. Learning Distributed Control for Modular Robots. In The Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems, Sendai, Japan, October 2004. [4] Carrick Detweiler, Marsette Vona, Keith Kotay, and Daniela Rus. Hierarchical Control for Self-assembling Mobile Trusses with Passive and Active Links. In CSAIL Research Abstracts 2006. |
|||||||||||
|