| Research Abstracts Home | CSAIL Digital Archive | Research Activities | CSAIL Home |
![]()
|
Research
Abstracts - 2007
|
|
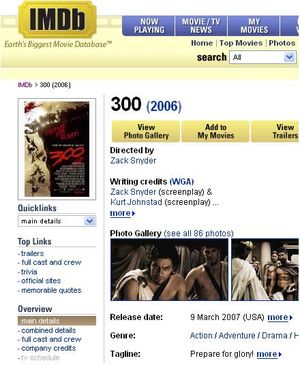
Wrapster: Semi-Automatic Wrapper Generation for Semi-Structured Web Data SourcesGabriel Zaccak & Boris KatzThe ProblemSemi-structured resources constitute many of the available information sources, especially on the Web, and this trend is likely to increase. Information extraction from semi-structured data uses wrappers. A wrapper is an automatic method for information extraction from a semi-structured source format, and Wrapper Induction is the field of research whose goal is to generate a wrapper by generalizing over a set of examples [1] [11] [9]. Although semi-structured sources follow syntactic regularities, it is not trivial to process and extract information from those sources. The main issues that wrapper generation systems needs to deal with are scalability and flexibility. Scalability concerns the variations of layout and format between many sites, and flexibility concerns the robustness of the wrappers to frequent layout and format change. Wrapster, a new system that semi-automatically generates wrappers for semi-structured Web sources, tackles these issues and eliminates the need for programming skills and, to a large extent, the process of scripts creation. Wrapster's novel component is the repairing module that constantly checks if any wrapper has broken and repairs the broken wrapper's script using stored extracted instances. Wrapster is being tested on the START Question Answering system; however it is a generic tool to be used by any QA system that uses the Web as its knowledge base. MotivationLets look at an excerpt of the Garden State Web page from the Internet Movie Database (IMDb) site (Figure 1). The page contains a top panel, a left panel, and a main section. The top panel has the IMDb logo and some links to the site services. The left panel consists of search boxes and list of links to related and non-related Web pages. The main section contains the movies properties such as the director, the genre, and the actors. A wrapper generation system needs to identify the regions of relevant information on the page, associate those regions with semantic labels, and create a wrapper for the data resource that represents a general form of the page. In this example, the page is in HTML format and is populated from a database of movies and their properties. It is generated by filling a movie template with particular properties. We can notice that properties are in different format such as a single value for year-of-release, a list of values for genre, or a table for the cast. The wrapper works as a smart index of such pages and is able to identify the properties and extract their values for use of information extraction systems. Automating this task is not trivial, even though the page is a simple structured Web page. For example, how can a wrapper generation system identify that the picture under the movies title is the movie poster and not the picture of the director when there is no textual indicator? The same difficulty applies to the movie title and year of release properties. In other cases where there are textual indicators such as the director property, it is easier to identify the information and its meaning. A wrapper generation systems' goal is to be able to extract this information even if the textual clue Directed by and the property location change. After the wrapper has been created, it should be able to identify the movie properties for any movie page from the IMDb site and, for example, should identify "Zack Snyder" as the director of the movie "300(2006)" even though the layout has changed (Figure 2).
ApproachThe input for Wrapster is the set of symbols and their Web page links on a site (Table 1). The output is a wrapper that consists of a finite set of scripts and their corresponding semantic labels that represent the properties of the site.
Wrapster consists of the following five modules: 1. Template Creation: This module creates a general template that identifies and marks the relevant information from the pages. Using some of the pages from the data source, Wrapster incrementally constructs the template they share. Wrapster computes the alignment between a small subset of pages using the tree edit distance technique [4] [6] [3] [5] [8] [7]. The alignment allows us to identify and discard the elements in common, and leaves us with the relevant slots for extraction. Then, Wrapster clusters the slots from all the aligned pages using a trained classifier [10], creates regions of neighboring slots, and identifies data structures such as lists and tables comparing the HTML structural and content similarity. Wrapster only needs a few examples of training data by using a variation of active learning technique [2]. Given a new set of unlabeled data it classifies the data and then retrains the classifier expanding the training data with new classified instances that have high confidence classification score. 2. Wrapper Induction: After identifying the relevant regions of the the source pages, Wrapster creates the scripts that extract the information from the template page from the previous step. In addition, it creates scripts with different focuses, i.e., a response for question fusion needs to be precise for value comparison while other question types require HTML fragments as answers for human friendly display purposes. The scripts generated comprise the wrapper for the data resource. They are written in a high-level description language that abstracts HTML-specific vocabulary and low-level regular expressions. As a result, such scripts are robust to format and layout changes, in contrast to regular expressions and high-level tag paths that break easily with such changes and need constant maintenance. 3. Semantic Annotation: The annotation module attaches semantic labels to the wrappers properties. Wrapster labels the regions using a trained classifier with features such as context and type of value. It is important to give meaningful labels to the scripts instead of using randomly generated ones for reasons such as facilitating the annotation process that maps properties to English sentences and paraphrases. 4. User Interface: The graphical user interface displays the wrapper generated from the previous steps and asks the user to approve that the wrapper includes the relevant properties and correct labels. The user can modify the regions, change the labels, and then approve the deployment of the wrapper to the online system. This verification step is optional but crucial to high-precision question answering systems such as START. 5. Repairing Module: The repairing module is a background service that constantly verifies the wrappers correctness. In cases where some scripts are broken, the system tries to repair the broken scripts if possible or else regenerates the wrapper again. Wrapster repairs the broken scripts by finding the most similar region on the symbols page that matches the stored extracted instances of the script. Wrapster uses the same trained classifier from the template creation module. The verification component deals successfully with frequently updated resources such as The Weather Channel and Yahoo Stocks. Although the scripts were built to be robust to format changes, this component is a safety net in cases of total format changes or word paraphrase changes. ProgressWe have implemented the template creation module, parts of the wrapper induction module, and the repairing module. We are currently working on making those components more robust and we are in the procress of building the user interface. FutureWrapster will be extended to also handle symbol discovery which is currently dealt with by manual creation of site-specific scripts. In addition, Wrapster will deal with unstructured data sources. Research SupportThis work is supported in part by the Disruptive Technology Office as part of the AQUAINT Phase 3 research program. References:[1] D. Freitag. Information Extraction from HTML: Application of a General Machine Learning Approach. In AAAI/IAAI 1998. [2] Yoav Freund, H. Sebastian Seung, Eli Shamir, and Naftali Tishby. Selective Sampling Using the Query by Committee Algorithm. In Machine Learning v. 28; 2-3, pp. 133-168, 1997. [3] M. Dubiner, Z. Galil, and E. Magin. Faster tree pattern matching. In J. Association of computing Machinery, 41 (2), pp. 205–213, March 1987. [4] R. Cole, R. Hariharan and P. Indyk. Tree pattern matching and subset matching in deterministic O(nlog3n)-time. In In SODA: ACM-SIAM Symposium on Discrete Algorithms (A conference on Theoretical and Experimental Analysis of Discrete Algorithms) 1999. [5] C. M. Hoffmann, M. J. O'Donnell. Pattern matching in trees. In J. Association of computing Machinery, 29 (1)), pp. 68-95, January 1982. [6] T. Cormen, C. Lieserson, R. Rivest, and C Stein. Introduction to Algorithms. 2nd edition, 2001. [7] K. Zhang, D. Shasha. Simple fast algorithms for the editing distance between trees and related problems. In SIAM J. Computing, 18 (6), pp. 1245–1262, December 1989. [8] D. Reis, P. Golgher, A. Laender, A. da Silva. Automatic web news extraction using tree edit distance.. In WWW 2004. [9] S. Soderland. Learning Information Extraction Rules for Semistructured and Free Text. In Machine Learning 1999. [10] V. Vapnik. Statistical Learning Theory. New York, 1998. [11] N. Kushmerick, D. S. Weld, and R. B. Doorenhos. Wrapper induction for information extraction. In In Intl. Joint Conference on Artificial Intelligence (IJCAI) pp. 729–737, 1997. |
||||||||||||||||||||||||||||||||
|
|||||||||||||||||||||||||||||||||