| Technical Reports | Work Products | Research Abstracts | Historical Collections |
![]()
|
Research
Abstracts - 2006
|
|
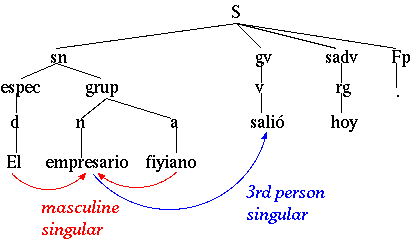
Morphology and Reranking for the Statistical Parsing of SpanishBrooke Cowan & Michael CollinsIntroductionInitial methods for statistical parsing were mainly developed through experimentation on English data sets. Subsequent research has focused on applying these methods to other languages. There has been widespread evidence that new languages exhibit linguistic phenomena that pose considerable challenges to techniques originally developed for English. For instance, English is a morphologically-impoverished language, while most of the world's languages exhibit far richer morphologies. Relative to English, Spanish has a richer morphology. For instance, the forms of Spanish nouns, determiners, and adjectives reflect both number and gender; pronouns reflect gender, number, person, and case. In Spanish, morphological constraints may be manifested at the syntactic level: certain members of a noun phrase are constrained to agree in number and gender, and a verb is constrained to agree in number and person with its subject. Hence, Spanish morphology gives us important structural cues about how words relate to one another in phrases and sentences. (See Figure 1.) Our work concerns how to model these morphological phenomena more accurately within a statistical approach. We describe two methods for incorporating detailed features in a Spanish parser. Figure 1: The determiner, noun, and adjective in the noun phrase el empresario fiyiano agree in gender and number, while the subject, empresario agrees with the verb in person and number. ApproachOur first method incorporates morphological information into a lexicalized PCFG (a version of the Model 1 parser described in [2]) by experimenting with various part-of-speech (POS) tagsets. Each tagset can be thought of as a particular morphological model or a subset of morphological attributes. For this work, we considered subsets of the 18 morphological features in Table 1. For instance, one particular model might capture the modal information of verbs. In this model, there would be six POS tags for verbs (one for each of indicative, subjunctive, imperative, infinitive, gerund, and participle). In [4], we describe in more detail how altering the POS tagset impacts the underlying model.
Table 1. The set of 18 Spanish morphological attributes with which we modified our POS tagsets. Our second method uses a reranking model to select the best Spanish parse from a list of n-best parses generated by the morphologically-sensitive model described above. The motivation for the reranking model is that a wide variety of arbitrary structural features of parse trees can be used to score candidate parses. The features we used for this work are described in [3]. To train the reranker, we applied the exponentiated gradient reranking algorithm described in [1]. DataAll of the experiments in this paper are carried out using a freely-available Spanish treebank produced by the 3LB project ([12]). This resource contains around 3,500 hand-annotated trees (97,000 words), less than 10% of the data usually used to train models in English. Prior to using the trees, we subjected them to some preprocessing steps designed to better model certain linguistic phenomena. See [4] for further discussion. Experimental ResultsOur models were trained using a training set consisting of 80% of the data (2,801 sentence/tree pairs, 75,372 words) available to us in the 3LB treebank. We reserved the remaining 20% (692 sentences, 19,343 words) to use as unseen data in a test set. We used cross-validation on the training set during the development of both the morphological and the reranking models. To evaluate our models, we considered the recovery of labeled and unlabeled dependencies as well as that of labeled constituents. Table 2 shows the performance, in terms of constituency accuracy, of three models on the test set: a baseline model, the best-performing morphological model from the development stage, and the reranking model. The baseline model is the Model 1 parser described in [2] trained with a simple POS tagset (e.g., N for noun and V for verb). The best morphological model was selected from over 50 models tested during development. It includes the number and mode of verbs, as well as the number of adjectives, determiners, nouns, and pronouns. The reranking model has been applied to an n-best list of parses from the best morphological model. All differences in the table are statistically significant at the level p=0.01, using the sign test.
Table 2. Recovery of constituents for three models on the test set. Future WorkThere are a number of ways in which this work could be extended. For example, we could use a more sophisticated underlying model such as the Model 2 parser described in [2]. We could also try engineering features for the reranker that specifically address errors made by the morphological model. We plan to use the Spanish parser for other work we are doing in machine translation. SupportThis work was funded by Sri International through the CALO project, award #03-000215, by the NSF through the MSPA-MCS program, award #DMS-0434222, and by Quanta Computer, Inc. through the Quanta T-Party: Natural Interactions program. References:[1] Peter Bartlett, Michael Collins, Ben Taskar, and David McAllester. Exponentiated gradient algorithms for large-margin structured classification. In Proceedings of NIPS 2004, 2004. [2] Michael Collins. Head-Driven Statistical Models for Natural Language Parsing. University of Pennsylvania. 1999. [3] Michael Collins and Terry Koo. Discriminative Reranking for Natural Language Parsing. Computational Linguistics, 31(1):25--69. 2005. [4] Brooke Cowan and Michael Collins. Morphology and Reranking for the Statistical Parsing of Spanish. In EMNLP 05, 2005. [5] Montserrat Civit Torruella. Guía para la anotación morfosintáctica del corpus CLiC-TALP. X-Tract Working Paper, WP-00/06. 2000. |
|||||||||||||||||||||||||||||||
|